Instanzfunktionen in Jitterbit Studio
Einführung
Diese Funktionen sind für die Verwendung in Transformationszuordnungen (oder Skripten, die während der Zuordnungen aufgerufen werden) gedacht, da sie die Instanzen von Daten-Elementen (Quellen und Ziele) verwenden, die in den Zuordnungen gefunden werden.
Einfügen eines Hashs zur Rückgabe eines Arrays
In Fällen, in denen ein erforderlicher Eingabeparameter für eine Instanzfunktion ein Array ist, kann ein Hash-Symbol (#) im Referenzpfad eines Daten-Elements eingefügt werden, um ein Array von Daten anstelle eines einzelnen Feldes zurückzugeben.
Zum Beispiel:
SumString(_Root$customer.contact#.Email, ",", true);
Im obigen Beispiel wird der Daten-Element-Pfad (_Root$customer.contact#.Email) so konstruiert, dass er ein Array von Email-Adressen (.Email) innerhalb eines Arrays von Kontakten (.contact) zurückgibt. Das # wird vor dem Array von Email-Adressen (#.Email) eingefügt, um anzuzeigen, dass es für jeden Kontakt ein Array von Email-Adressen geben könnte. Dies führt zu einer Zuordnung, die durch das Array der Kontaktaufzeichnungen iteriert, aber nicht durch das Array der Emails.
Dieses Konzept gilt auch für Schleifen-Knoten in Transformationen.
Erweiterte Nutzung
Die Instanzfunktionen können im Allgemeinen ineinander geschachtelt werden. Wenn sie geschachtelt sind, bewegen sich die Ergebnisse nach oben in der Hierarchie und umfassen mehr Ergebnisse. Diese Funktionen können entweder einen einzelnen Wert oder ein Array von Werten zurückgeben, abhängig vom Kontext, in dem sie verwendet werden.
Zum Beispiel wird eine Sum-Funktion, die eine Count-Funktion enthält, die Ergebnisse jeder Aufruf der Count-Funktion addieren und eine Gesamtsumme erzeugen:
Sum(Count(_Root$customer.sales#.items#.ID));
Count
Deklaration
int Count(type de)
int Count(array arr)
Syntax
Count(<de>)
Count(<arr>)
Erforderliche Parameter
de: (Erste Form) Ein Entitätspfad zu Instanzen eines Datenelements in einer Quelle oder einem Zielarr: (Zweite Form) Ein Array; alle Elemente des Arrays müssen vom gleichen Typ sein
Beschreibung
Zählt alle Instanzen eines Datenelements auf einer bestimmten hierarchischen Ebene in einer Quelle oder einem Ziel, wobei dieses Datenelement einen gültigen Wert enthält (und nicht null ist).
Die Funktion gibt je nach Kontext, in dem sie aufgerufen wird, entweder eine Ganzzahl oder ein Array von Instanzen zurück.
Hinweis
Verwenden Sie die Count-Funktion nicht, um festzustellen, ob eine Variable ein Array ist. Verwenden Sie die IsValid-Funktion und versuchen Sie stattdessen, auf einen Array-Index zuzugreifen. Zum Beispiel: IsValid(variable[0]).
Beispiele
Angenommen, eine Datenbank enthält ein Feld "Quantity" in einer Tabelle "Items", die ein Kind von "POHeader" (einer Bestellung) ist, und dass es viele Artikel innerhalb eines POHeader gibt. Dann gibt diese Anweisung die Anzahl der Artikelzeilen für einen bestimmten POHeader zurück, die Werte in der Quantity-Spalte haben, die nicht null sind:
Count(POHeader.Items#.Quantity);
In diesem Fall nehmen wir an, dass eine Datendatei mit mehreren Instanzen vorhanden ist, mit Kunden, die Verkäufe haben, die Artikel haben; und jeder Artikel hat ein ID-Feld. Diese Anweisung zählt, wie viele verschiedene Artikel in jedem Verkauf vorhanden sind, und verwendet die Sum-Funktion, um alle zurückgegebenen Artikel für jeden Verkauf zusammenzuzählen; dies wird die Gesamtzahl der unterschiedlichen Artikel sein, die gekauft wurden:
Sum(Count(_Root$customer.sales#.items#.ID));
CountSourceRecords
Deklaration
int CountSourceRecords()
Syntax
CountSourceRecords()
Beschreibung
Gibt die Anzahl der Quellinstanzen für einen Zielknoten zurück, wenn der Zielknoten auf ein übergeordnetes Feld einer Zuordnung verweist.
Wenn der Zielknoten kein Schleifenknoten ist, gibt die Funktion 1 zurück. Siehe auch die Funktion SourceInstanceCount.
Hinweis
Der Streaming-Modus einer Flat-to-Flat-Transformation würde durch die Verwendung dieser Funktion nicht beeinflusst, während der Streaming-Modus für eine XML-to-Flat-Transformation deaktiviert würde.
Beispiele
Angenommen, eine Quelle mit Kunden-Datensätzen, die Instanzen von Verkäufen mit Instanzen von Artikel mit einem Feld Typ haben:
// Diese Anweisung zeigt die Instanzanzahl eines Datensatzes im Vergleich
// zur Gesamtzahl der Quelldatensätze
"Datensatz " + SourceInstanceCount() + " von " + CountSourceRecords();
Exist
Deklaration
bool Exist(type v, type de)
bool Exist(type v, array arr)
Syntax
Exist(<v>, <de>)
Exist(<v>, <arr>)
Erforderliche Parameter
v: Ein zu findender Wertde: (Erste Form) Ein Entitätspfad zu Instanzen eines Datenelements in einer Quelle oder einem Zielarr: (Zweite Form) Ein Array; alle Elemente des Arrays müssen vom gleichen Typ sein und denselben Typ wievhaben
Beschreibung
Überprüft die Existenz eines Wertes (v) in Instanzen eines Datenelements (de) oder einem Array (arr) und gibt je nach Fund true (oder false) zurück.
Die Funktion gibt entweder einen booleschen Wert oder ein Array von Instanzen zurück, abhängig vom Kontext, in dem sie aufgerufen wird.
Beispiele
Angenommen, eine Quelle mit Kunden-Datensätzen, die Instanzen von Verkäufen mit Instanzen von Artikel mit einem Feld Typ haben:
// Returns if true if the value "subscription" is
// found in any instances of a field "customer.sales.items.Type"
// at the level of "sales":
Exist("subscription",_Root$customer.sales.items#.Type);
// To test this at the next highest level of the hierarchy,
// at the level of the customer,
// enclose this in a nested "Exist", testing for "true":
Exist(true, Exist("subscription",_Root$customer.sales#.items#.Type));
// The last statement answers, at the customer level, if a customer
// has any items in any sales with a Type field equal to "subscription"
FindByPos
Deklaration
type FindByPos(int pos, type de)
type FindByPos(int pos, array arr)
Syntax
FindByPos(<pos>, <de>)
FindByPos(<pos>, <arr>)
Erforderliche Parameter
pos: Der Index (von welcher Vorkommen; 1-basiert), um den Wert abzurufende: (Erste Form) Ein Entitätspfad zu Instanzen eines Datenelements in einer Quelle oder einem Ziel; oderarr: (Zweite Form) Ein Array; alle Elemente des Arrays müssen vom gleichen Typ sein
Beschreibung
Gibt den Wert eines Datenelements aus einer Instanz zurück, die mehrfach vorkommt. Es kann auch verwendet werden, um ein Element eines Arrays in einer 1-basierten Weise zurückzugeben.
Wenn eine negative Zahl für das Vorkommen oder das Array angegeben wird, beginnt die Zählung von der letzten Zeile oder dem letzten Element. Beachten Sie, dass der Index 1-basiert ist.
Beispiele
// Assume a database has a child-parent relationship
// where for each parent the child occurs multiple times
// To retrieve the second child, use:
FindByPos(2, ParentTab.ChildTab#.Value$);
// To retrieve the last child, use:
FindByPos(-1, ParentTab.ChildTab#.Value$);
FindValue
Deklaration
type FindValue(type0 v, type1 de1, type2 de2)
Syntax
FindValue(<v>, <de1>, <de2>)
Erforderliche Parameter
v: Ein Wert, nach dem gesucht werden sollde1: Ein Entitätspfad zu Instanzen eines Datenelements in einer Quelle oder einem Ziel, der als Übereinstimmung verwendet werden sollde2: Ein Entitätspfad zu Instanzen eines Datenelements in einer Quelle oder einem Ziel, der zurückgegeben werden soll, wenn eine Übereinstimmung gefunden wird
Beschreibung
Durchsucht mehrere Instanzen eines Datenelements (de1) nach dem in v angegebenen Wert. Wenn die Funktion den Wert findet, gibt sie den Wert im Feld zurück, das im dritten Parameter (de2) für diese gefundene Instanz angegeben ist. Wenn der Wert nicht gefunden wird, gibt die Funktion null zurück. Siehe auch die Funktion HasKey.
Beispiele
Diese Anweisung sucht die Instanzen von B unter A und überprüft den Inhalt von field1. Sie wählt die erste Instanz von B aus, die sie findet, wo field1 "ID" enthält, und gibt dann den Wert von field2 aus derselben Instanz zurück:
FindValue("ID", A.B#.field1, A.B#.field2);
Diese Anweisungen zeigen, wie man einen Test eines Arrays auf die Einschluss eines Wertes implementiert. Es wird ein Array nach einem Wert durchsucht und gibt true zurück, wenn er gefunden wird, und false, wenn nicht. Es ist das Array-Äquivalent zur Wörterbuchfunktion HasKey. Beachten Sie, dass zwei Instanzen desselben Arrays an die Funktion übergeben werden:
arr = {1, 2, 3};
value = 1;
t = (FindValue(value, arr, arr) == value);
// t will be 1 (true)
value = 4;
t = (FindValue(value, arr, arr) == value);
// t will be 0 (false)
GetInstance
Deklaration
type GetInstance()
Syntax
GetInstance()
Beschreibung
Diese Funktion gibt das Instanzdaten-Element zurück, das durch den Aufruf einer SetInstances-Funktion während der Generierung des Elternteils definiert wurde. Als Alternative zu dieser Funktion siehe die ArgumentList-Funktion.
Beispiele
Angenommen, eine der Elternzuordnungen einer Transformation enthält diese Anweisungen:
...
r1=DBLookupAll("<TAG>endpoint:database/My Database</TAG>",
"SELECT key_name, key_value, key_type FROM key_values");
SetInstances("DETAILS", r1);
r2 = {"MS", "HP", "Apple"};
SetInstances("COMPANIES", r2);
...
Im Zielknoten DETAILS können wir eine Zuordnungsbedingung mit folgendem erstellen:
<trans>
GetInstance()["key_value"] != "";
// Same as GetInstance()[0] != ""
</trans>
oder in einem der Attribute kann die Zuordnung enthalten:
<trans>
x=GetInstance();
x["key_name"] + "=" + x["key_value"];
// Same as x[0] + "=" + x[1]
</trans>
In einem der Attribute des Zielknotens COMPANIES oder im Zielknoten selbst kann die Zuordnung enthalten:
<trans>
GetInstance();
// This will return
// "MS" for the first instance
// "HP" for the second instance
// "Apple" for the third instance
</trans>
Visuelles Beispiel und Ausgabe
Unten ist eine Beispiel-Schema-Konfiguration, die das obige r2-Beispiel auf einen getInformationRequest-Schleifenknoten und einen COMPANIES-Zielschleifenknoten anwendet. DETAILS wurde der Einfachheit halber ausgeschlossen.
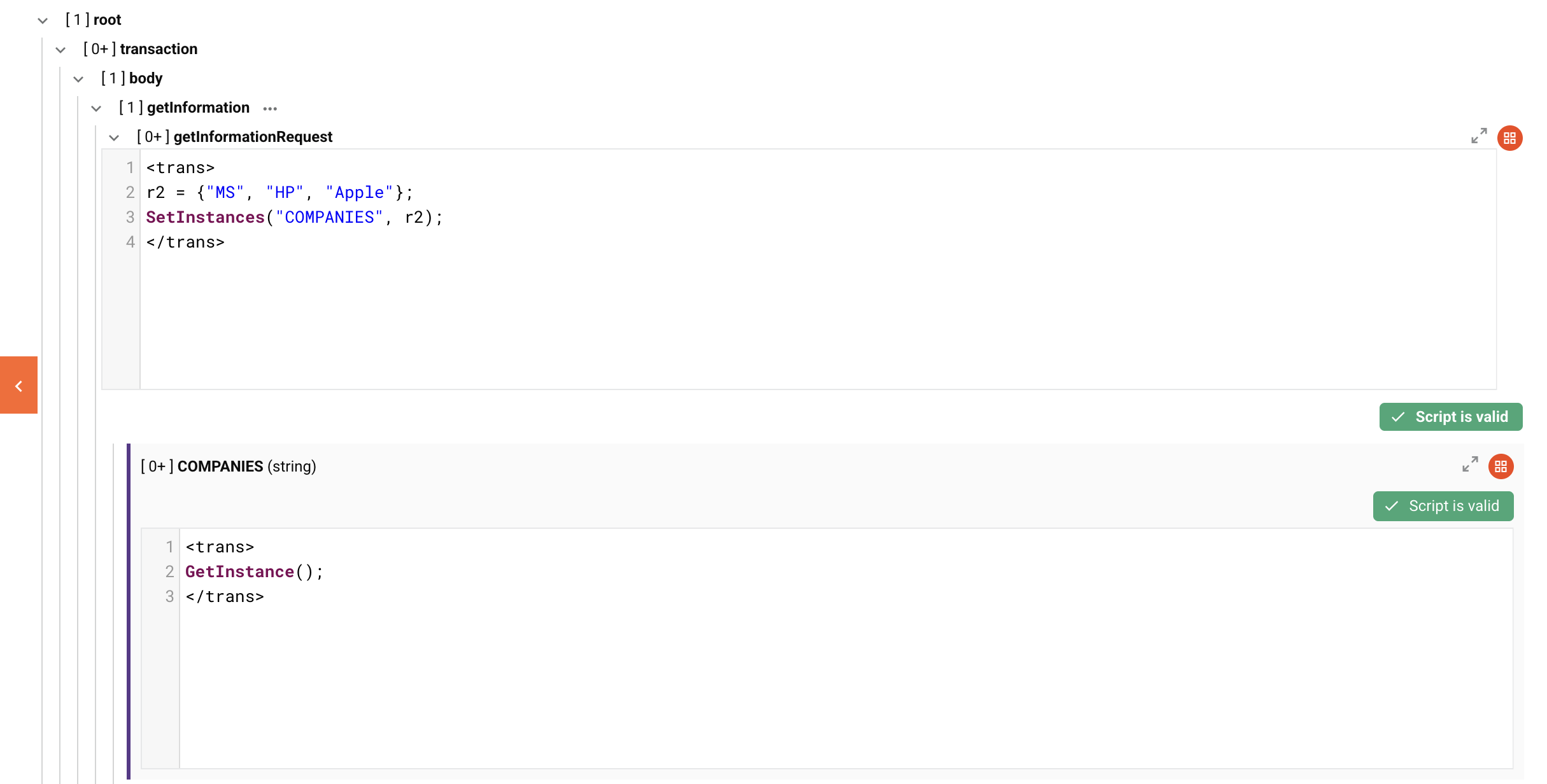
Das resultierende XML, wenn die Ausgabe direkt nach der Transformation geschrieben wird:
<?xml version="1.0" encoding="UTF-8"?>
<root xmlns="http://www.jitterbit.com/XsdFromWsdl" xmlns:ns="com.iex.tv.webservices.services.agentResourcesService" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<transaction>
<body>
<ns:getInformation>
<ns:getInformationRequest>
<ns:COMPANIES>MS</ns:COMPANIES>
<ns:COMPANIES>HP</ns:COMPANIES>
<ns:COMPANIES>Apple</ns:COMPANIES>
</ns:getInformationRequest>
</ns:getInformation>
</body>
</transaction>
</root>
Max
Deklaration
type Max(type de)
type Max(array arr)
Syntax
Max(<de>)
Max(<arr>)
Erforderliche Parameter
de: (Erste Form) Ein Entitätspfad zu Instanzen eines Datenelements in einer Quelle oder einem Zielarr: (Zweite Form) Ein Array; alle Elemente des Arrays müssen vom gleichen Typ sein
Beschreibung
Gibt den maximalen Wert von Instanzen eines Datenelements auf einem bestimmten Niveau in der Hierarchie einer Datenstruktur zurück. Es werden alle Instanzen auf diesem Niveau überprüft und der größte Wert zurückgegeben. Es kann auch verwendet werden, um den maximalen Wert eines Arrays zurückzugeben.
Beispiele
Angenommen, eine Datenbank enthält ein Feld "Quantity" in einer Tabelle "Items", das ein Kind von "POHeader" (einer Bestellung) ist, und dass es viele Artikel innerhalb eines POHeader gibt. Dann gibt diese Anweisung den maximalen Wert von Quantity für einen beliebigen Artikel für einen bestimmten POHeader zurück:
Max(POHeader.Items#.Quantity);
Min
Deklaration
type Min(type de)
type Min(array arr)
Syntax
Min(<de>)
Min(<arr>)
Erforderliche Parameter
de: (Erste Form) Ein Entitätspfad zu Instanzen eines Datenelements in einer Quelle oder einem Zielarr: (Zweite Form) Ein Array; alle Elemente des Arrays müssen vom gleichen Typ sein
Beschreibung
Gibt den minimalen Wert von Instanzen eines Datenelements auf einem bestimmten Niveau in der Hierarchie einer Datenstruktur zurück. Es werden alle Instanzen auf diesem Niveau überprüft und der kleinste Wert zurückgegeben. Es kann auch verwendet werden, um den minimalen Wert eines Arrays zurückzugeben.
Beispiele
Angenommen, eine Datenbank enthält ein Feld "Quantity" in einer Tabelle "Items", das ein Kind von "POHeader" (einer Bestellung) ist, und dass es viele Artikel innerhalb eines POHeader gibt. Dann gibt diese Anweisung den minimalen Wert von Quantity für einen beliebigen Artikel für einen bestimmten POHeader zurück:
Min(POHeader.Items#.Quantity);
ResolveOneOf
Deklaration
type ResolveOneOf(type de)
type ResolveOneOf(array arr)
Syntax
ResolveOneOf(<de>)
ResolveOneOf(<arr>)
Erforderliche Parameter
de: (Erste Form) Ein Entitätspfad zu Instanzen eines Datenelements in einer Quelle oder einem Zielarr: (Zweite Form) Ein Array; alle Elemente des Arrays müssen vom gleichen Typ sein
Beschreibung
Gibt den ersten nicht-null Wert aus Instanzen eines Datenelements zurück. Diese Funktion wird allgemein verwendet, um den Wert eines "one-of" Quelldatenelements abzurufen. Sie kann auch mit Arrays verwendet werden und gibt das erste nicht-null Element zurück.
SetInstances
Deklaration
null SetInstances(string nodeName, array de)
Syntax
SetInstances(<nodeName>, <de>)
Erforderliche Parameter
nodeName: Der Name eines Zielsde: Ein Entitätspfad zu Instanzen eines Datenelements im Ziel
Beschreibung
Definiert die Quellinstanzen für einen Zielschleifen-Knoten. Normalerweise wird eine Zielinstanz aus einer Quellinstanz der Schleife generiert. Manchmal können die Daten aus anderen Quellen stammen. Diese Funktion ist für Fälle gedacht, in denen die Daten in mehreren Mengen vorliegen und jede Menge ein einzelnes Zielelement generiert.
Die Instanz ist ein Datenelement, das ein einfacher Wert oder ein Array von Datenelementen sein kann. Bei der Erstellung des Ziels wird jede Instanz verwendet, um eine Zielinstanz zu generieren.
Um zu sehen, wie man ein Instanzdatenelement verwendet, siehe die Funktionen GetInstance und ArgumentList.
Diese Funktion sollte in den Zuordnungen des übergeordneten Knotens des beabsichtigten Ziels aufgerufen werden. Wenn im übergeordneten Knoten kein Blattknoten verfügbar ist, kann ein Bedingungsknoten erstellt werden, der diese Funktion aufruft. Die Bedingung sollte mit true enden, damit sie immer akzeptiert wird.
Die Funktion sollte nicht mehr als einmal mit demselben Zielknoten aufgerufen werden, da der letzte Aufruf vorherige überschreibt. Um ein Überschreiben zu vermeiden, können mehrere Mapping-Ordner erstellt werden.
Ein Null-Datenelement wird von dieser Funktion zurückgegeben und sollte ignoriert werden.
Beispiele
Angenommen, es gibt einen gemeinsamen Elternknoten für die Zielknoten DETAILS und COMPANIES; beide sind Schleifenknoten; und ein Mehrfach-Mapping-Ordner wurde für den Zielknoten DETAILS erstellt.
...
r1 = DBLookupAll("<TAG>endpoint:database/My Database</TAG>",
"SELECT key_name, key_value FROM key_values");
SetInstances("DETAILS", r1);
SetInstances("DETAILS#1", r1);
// DETAILS#1 is the name of the
// 1st multiple-mapping-folder for DETAILS
r2 = {"MS", "HP", "Apple"};
SetInstances("COMPANIES", r2);
// Note: Renaming the display name of a
// multiple-mapping-folder doesn't change
// the folder's actual name, which can be
// found by control-clicking the node and using
// "Copy node name to clipboard"
...
Visuelles Beispiel und Ausgabe
Nachfolgend finden Sie eine Beispiel-Schema-Konfiguration, die das obige r2-Beispiel auf einen Schleifenknoten getInformationRequest und einen Ziel-Schleifenknoten COMPANIES anwendet. DETAILS wurde der Einfachheit halber ausgeschlossen.
Das resultierende XML, wenn die Ausgabe direkt nach der Transformation geschrieben wird:
<?xml version="1.0" encoding="UTF-8"?>
<root xmlns="http://www.jitterbit.com/XsdFromWsdl" xmlns:ns="com.iex.tv.webservices.services.agentResourcesService" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<transaction>
<body>
<ns:getInformation>
<ns:getInformationRequest>
<ns:COMPANIES>MS</ns:COMPANIES>
<ns:COMPANIES>HP</ns:COMPANIES>
<ns:COMPANIES>Apple</ns:COMPANIES>
</ns:getInformationRequest>
</ns:getInformation>
</body>
</transaction>
</root>
SortInstances
Deklaration
null SortInstances(string nodeName, array sourceDataElements1[, bool sortOrder, ..., array sourceDataElementsN, bool sortOrderN])
Syntax
SortInstances(<nodeName>, <sourceDataElements1>[, <sortOrder>, ..., <sourceDataElementsN>, <sortOrderN>])
Erforderliche Parameter
nodeName: Name der Ziel-Schleifenelemente, die sortiert werden sollensourceDataElements: Ein Entitätspfad zu Instanzen eines Datenelements in einer Quelle oder einem Ziel
Optionale Parameter
sourceDataElementsN: Ein Entitätspfad zu Instanzen eines Datenelements in einer Quelle oder einem ZielsortOrder: Eine optionale Sortierreihenfolge, standardmäßig true für aufsteigend. Das Argument ist nicht optional, wenn mehreresourceDataElements-Argumente bereitgestellt werden.
Beschreibung
Sortiert die Generierung von Ziel-Schleifendaten-Elementen basierend auf einem oder mehreren Daten-Elementen im Quell- oder Zielbereich.
Alle Sortierungsinstanzen müssen die gleiche Anzahl von Instanzen wie die Anzahl der Zielinstanzen haben.
Die Sortierreihenfolge wird als aufsteigend angenommen, und ein optionales Skalarargument kann neben jedem Sortierungsdaten-Element angegeben werden, um die Standard-Sortierreihenfolge zu überschreiben. Wenn sortOrder false ist, ist die Sortierreihenfolge absteigend.
Die Ziel-Schleifendaten-Elemente werden zuerst nach den Instanzen der ersten Quell-Daten-Elemente sortiert und dann nach den Instanzen der zweiten Daten-Elemente und so weiter.
Diese Funktion muss in den Zuordnungen des übergeordneten Knotens aufgerufen werden. Wenn es kein Feld gibt, das im übergeordneten Knoten zugeordnet werden kann, kann entweder ein Skript mit dieser Funktion aufgerufen oder eine Bedingung zu diesem Zweck hinzugefügt werden.
Ein Nullwert wird von dieser Funktion zurückgegeben und sollte ignoriert werden.
Beispiele
// The target node "detail" will be ordered
// by "price" from high to low and,
// if the prices are the same for two items,
// the node will be ordered by "quantity" from low to high
SortInstances("detail", Invoice$Item#.price, false, Invoice$Item#.quantity);
Dieses nächste Beispiel könnte in einer Bedingung in einer Zuordnung verwendet werden, um alle Verkäufe für jeden Kunden nach Datum zu sortieren. Es würde auf der Ebene des customer-Knotens platziert werden. Beachten Sie die Einbeziehung der Anweisung true am Ende des Codeblocks, damit die Bedingung immer akzeptiert wird:
<trans>
SortInstances("SalesOrders", _Root$customer.sales#.SalesDate);
true
</trans>
Sum
Deklaration
type Sum(type de)
type Sum(array arr)
Syntax
Sum(<de>)
Sum(<arr>)
Erforderliche Parameter
de: (Erste Form) Ein Entitätspfad zu Instanzen eines Daten-Elements in einer Quelle oder einem Zielarr: (Zweite Form) Ein Array; alle Elemente des Arrays müssen vom gleichen Typ sein
Beschreibung
Nimmt den Wert jeder Instanz eines Daten-Elements auf einer bestimmten hierarchischen Ebene und gibt die Summe zurück. Der Datentyp von sowohl de als auch arr muss einer von Integer, Long, Float, Double oder String sein. Die Datentypen aller Instanzen oder aller Elemente müssen gleich sein.
Wenn das Array leer ist, wird 0 (null) zurückgegeben. Obwohl null-Werte in Arrays mit einem anderen Datentyp ignoriert werden, führt ein Array, das nur null-Werte enthält, zu einem Fehler.
Beispiele
Angenommen, es gibt eine Datenbank mit einem Feld "Quantity" in einer Tabelle "Items", die ein Kind von POHeader ist (es gibt viele Artikel innerhalb eines POHeader).
// Gibt die Summe des Feldes "Quantity" für
// alle Artikel für einen bestimmten "POHeader" zurück
Sum(POHeader.Items#.Quantity);
SumCSV
Deklaration
string SumCSV(type de)
string SumCSV(array arr)
Syntax
SumCSV(<de>)
SumCSV(<arr>)
Erforderliche Parameter
de: (Erste Form) Ein Entitätspfad zu Instanzen eines Datenelements in einer Quelle oder einem Zielarr: (Zweite Form) Ein Array; alle Elemente des Arrays müssen vom gleichen Typ sein
Beschreibung
Verkettet jede Instanz eines Feldes eines Datenelements oder jedes Element eines Arrays mit einem Komma als Trennzeichen zwischen jeder Instanz oder jedem Element.
Wenn das Feld oder das Array-Element Sonderzeichen wie Zeilenumbrüche oder Kommas enthält, wird das Feld oder das Array-Element in doppelte Anführungszeichen gesetzt. Nach der letzten Instanz oder dem letzten Element wird kein Trennzeichen hinzugefügt.
Siehe auch die Funktion SumString für eine ähnliche Funktion, jedoch mit zusätzlichen Optionen.
Beispiele
// Verkettet alle Instanzen eines Feldes von Email-Adressen
// mit einem Komma zwischen jeder Adresse
SumCSV(_Root$customer.contact#.Email);
SumString
Deklaration
string SumString(type de[, string delimiter, bool omitLast])
string SumString(array arr[, string delimiter, bool omitLast])
Syntax
SumString(<de>[, <delimiter>, <omitLast>])
SumString(<arr>[, <delimiter>, <omitLast>])
Erforderliche Parameter
de: (Erste Form) Ein Entitätspfad zu Instanzen eines Datenelements in einer Quelle oder einem Zielarr: (Zweite Form) Ein Array; alle Elemente des Arrays müssen vom gleichen Typ sein
Optionale Parameter
delimiter: Eine Zeichenkette zur Trennung der Elemente; der Standardwert ist ein SemikolonomitLast: Ein Flag, das angibt, ob der Trennzeichen nach dem letzten Element eingeschlossen werden soll; der Standardwert ist false
Beschreibung
Verkettet jede Instanz der angegebenen Datenelemente oder jedes Element eines Arrays, wobei ein Trennzeichen automatisch an das Ende jeder verketteten Zeichenkette angefügt wird.
Wenn der Parameter omitlast true ist, wird das Trennzeichen nach der letzten Zeichenkette weggelassen.
Siehe auch die Funktion SumCSV.
Beispiele
// Concatenates all instances of a field of email addresses
// with a comma between each address,
// but does not place a delimiter after the last address
SumString(_Root$customer.contact#.Email, ",", true);