Funciones de instancia en Jitterbit Studio
Introducción
Estas funciones están destinadas a ser utilizadas en mapeos de transformación (o scripts llamados durante los mapeos), ya que utilizan las instancias de elementos de datos (fuentes y destinos) que se encuentran en los mapeos.
Inserción de un hash para devolver un array
En los casos donde un parámetro de entrada requerido para una función de instancia es un array, se puede insertar un símbolo de hash (#) en la ruta de referencia de un elemento de datos para devolver un array de datos en lugar de un solo campo.
Por ejemplo:
SumString(_Root$customer.contact#.Email, ",", true);
En el ejemplo anterior, la ruta del elemento de datos (_Root$customer.contact#.Email) se construye para devolver un array de direcciones de correo electrónico (.Email) dentro de un array de contactos (.contact). El # se inserta antes del array de direcciones de correo electrónico (#.Email) para indicar que en cada contacto, podría haber un array de direcciones de correo electrónico. Esto resulta en un mapeo que recorre el array en los registros de contacto pero no recorre el array en los correos electrónicos.
Este concepto también se aplica a nodos de bucle en transformaciones.
Uso avanzado
Las funciones de instancia pueden, en general, estar anidadas entre sí. A medida que se anidan, los resultados se moverán hacia arriba en la jerarquía y abarcarán más resultados. Estas funciones pueden devolver ya sea un solo valor o un array de valores, dependiendo del contexto en el que se utilicen.
Por ejemplo, una función Sum que tiene una función Count dentro sumará los resultados de cada invocación de la función Count, y producirá un total:
Sum(Count(_Root$customer.sales#.items#.ID));
Count
Declaración
int Count(type de)
int Count(array arr)
Sintaxis
Count(<de>)
Count(<arr>)
Parámetros requeridos
de: (Primera forma) Una ruta de entidad a instancias de un elemento de datos en una fuente o un destinoarr: (Segunda forma) Un arreglo; todos los elementos del arreglo deben ser del mismo tipo
Descripción
Cuenta todas las instancias de un elemento de datos en un nivel jerárquico particular en una fuente o destino, donde ese elemento de datos contiene un valor válido (y no es nulo).
La función devuelve ya sea un entero o un arreglo de instancias, dependiendo del contexto en el que se llame.
Ejemplos
Suponga que una base de datos contiene un campo "Cantidad" en una tabla "Artículos" que es un hijo de "EncabezadoPO" (una orden de compra), y que hay muchos artículos dentro de un EncabezadoPO. Entonces, esta declaración devuelve el número de filas de artículos para un EncabezadoPO particular que tienen valores en la columna Cantidad que no son nulos:
Count(POHeader.Items#.Quantity);
En este caso, suponga un archivo de datos con múltiples instancias en él, con clientes que tienen ventas que tienen artículos; y cada artículo tiene un campo ID. Esta declaración contará cuántos artículos diferentes hay en cada venta y usará la función Sum para sumar todos los artículos devueltos para cada venta; este será el total de artículos diferentes comprados:
Sum(Count(_Root$customer.sales#.items#.ID));
CountSourceRecords
Declaración
int CountSourceRecords()
Sintaxis
CountSourceRecords()
Descripción
Devuelve el número de instancias de fuente para un nodo de destino, cuando el nodo de destino se refiere a un padre de un campo de mapeo.
Si el nodo de destino no es un nodo de bucle, la función devuelve 1. Véase también la función SourceInstanceCount.
Nota
El modo de transmisión de una transformación Plano-a-Plano no se vería afectado por el uso de esta función, mientras que el modo de transmisión se desactivaría para una transformación XML-a-Plano.
Ejemplos
Suponga una fuente con registros de cliente que tienen instancias de ventas con instancias de artículos con un campo Tipo:
// Esta declaración muestra el conteo de instancias de un registro en comparación
// con el número total de registros de la fuente
"Registro " + SourceInstanceCount() + " de " + CountSourceRecords();
Exist
Declaración
bool Exist(type v, type de)
bool Exist(type v, array arr)
Sintaxis
Exist(<v>, <de>)
Exist(<v>, <arr>)
Parámetros requeridos
v: Un valor a ser encontradode: (Primera forma) Una ruta de entidad a instancias de un elemento de datos en una fuente o un destinoarr: (Segunda forma) Un arreglo; todos los elementos del arreglo deben ser del mismo tipo y ser del mismo tipo quev
Descripción
Verifica la existencia de un valor (v) en instancias de un elemento de datos (de) o un arreglo (arr) y devuelve verdadero (o falso) dependiendo de si se encuentra.
La función devuelve ya sea un booleano o un arreglo de instancias, dependiendo del contexto en el que se llame.
Ejemplos
Suponga una fuente con registros de cliente que tienen instancias de ventas con instancias de artículos con un campo Tipo:
// Returns if true if the value "subscription" is
// found in any instances of a field "customer.sales.items.Type"
// at the level of "sales":
Exist("subscription",_Root$customer.sales.items#.Type);
// To test this at the next highest level of the hierarchy,
// at the level of the customer,
// enclose this in a nested "Exist", testing for "true":
Exist(true, Exist("subscription",_Root$customer.sales#.items#.Type));
// The last statement answers, at the customer level, if a customer
// has any items in any sales with a Type field equal to "subscription"
FindByPos
Declaración
type FindByPos(int pos, type de)
type FindByPos(int pos, array arr)
Sintaxis
FindByPos(<pos>, <de>)
FindByPos(<pos>, <arr>)
Parámetros requeridos
pos: El índice (desde qué ocurrencia; basado en 1) para recuperar el valorde: (Primera forma) Una ruta de entidad a instancias de un elemento de datos en una fuente o un destino; oarr: (Segunda forma) Un arreglo; todos los elementos del arreglo deben ser del mismo tipo
Descripción
Devuelve el valor de un elemento de datos de una instancia que ocurre múltiples veces. También se puede usar para devolver un elemento de un arreglo, de manera basada en 1.
Si se especifica un número negativo para la ocurrencia o el arreglo, el conteo comenzará desde la última fila o elemento. Tenga en cuenta que el índice es basado en 1.
Ejemplos
// Assume a database has a child-parent relationship
// where for each parent the child occurs multiple times
// To retrieve the second child, use:
FindByPos(2, ParentTab.ChildTab#.Value$);
// To retrieve the last child, use:
FindByPos(-1, ParentTab.ChildTab#.Value$);
FindValue
Declaración
type FindValue(type0 v, type1 de1, type2 de2)
Sintaxis
FindValue(<v>, <de1>, <de2>)
Parámetros requeridos
v: Un valor que se buscade1: Una ruta de entidad a instancias de un elemento de datos en una fuente o un destino, que se usará como coincidenciade2: Una ruta de entidad a instancias de un elemento de datos en una fuente o un destino, que se devolverá si se encuentra una coincidencia
Descripción
Busca múltiples instancias de un elemento de datos (de1) buscando el valor especificado en v. Si la función encuentra el valor, devuelve el valor en el campo especificado en el tercer parámetro (de2) para esa instancia encontrada. Si no se encuentra el valor, la función devuelve null. Consulte también la función HasKey.
Ejemplos
Esta declaración buscará las instancias de B bajo A y verificará el contenido de field1. Seleccionará la primera instancia de B que encuentre donde field1 contenga "ID", y luego devolverá el valor de field2 de esa misma instancia:
FindValue("ID", A.B#.field1, A.B#.field2);
Estas declaraciones muestran cómo implementar una prueba de un arreglo para la inclusión de un valor. Busca un valor en un arreglo y devuelve verdadero si se encuentra y falso si no. Es el equivalente en arreglo de la función de diccionario HasKey. Tenga en cuenta que se pasan dos instancias del mismo arreglo a la función:
arr = {1, 2, 3};
value = 1;
t = (FindValue(value, arr, arr) == value);
// t will be 1 (true)
value = 4;
t = (FindValue(value, arr, arr) == value);
// t will be 0 (false)
GetInstance
Declaración
type GetInstance()
Sintaxis
GetInstance()
Descripción
Esta función devuelve el elemento de datos de instancia que fue definido al llamar a una función SetInstances durante la generación del padre. Como alternativa a esta función, consulte la función ArgumentList.
Ejemplos
Suponga que uno de los mapeos padre de una transformación contiene estas declaraciones:
...
r1=DBLookupAll("<TAG>endpoint:database/My Database</TAG>",
"SELECT key_name, key_value, key_type FROM key_values");
SetInstances("DETAILS", r1);
r2 = {"MS", "HP", "Apple"};
SetInstances("COMPANIES", r2);
...
En el nodo objetivo DETAILS, podemos crear una condición de mapeo utilizando:
<trans>
GetInstance()["key_value"] != "";
// Same as GetInstance()[0] != ""
</trans>
o, en uno de los atributos, el mapeo puede contener:
<trans>
x=GetInstance();
x["key_name"] + "=" + x["key_value"];
// Same as x[0] + "=" + x[1]
</trans>
En uno de los atributos del nodo objetivo COMPANIES o el nodo objetivo mismo, el mapeo puede contener:
<trans>
GetInstance();
// This will return
// "MS" for the first instance
// "HP" for the second instance
// "Apple" for the third instance
</trans>
Ejemplo visual y salida
A continuación se muestra una configuración de esquema aplicando el ejemplo r2 anterior a un nodo de bucle getInformationRequest y un nodo de bucle objetivo COMPANIES. DETAILS fue excluido por simplicidad.
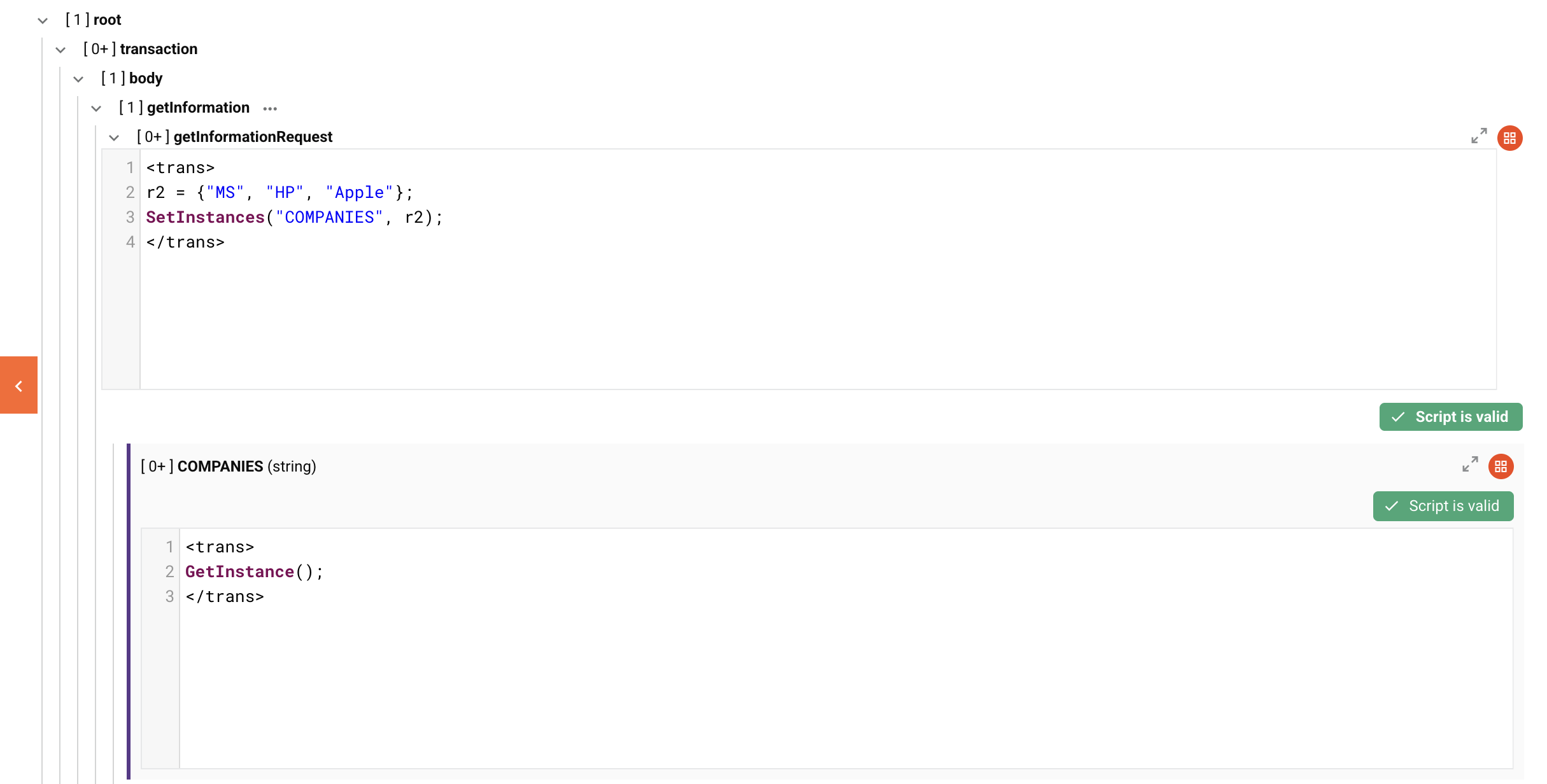
El XML resultante si la salida se escribe directamente después de la transformación:
<?xml version="1.0" encoding="UTF-8"?>
<root xmlns="http://www.jitterbit.com/XsdFromWsdl" xmlns:ns="com.iex.tv.webservices.services.agentResourcesService" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<transaction>
<body>
<ns:getInformation>
<ns:getInformationRequest>
<ns:COMPANIES>MS</ns:COMPANIES>
<ns:COMPANIES>HP</ns:COMPANIES>
<ns:COMPANIES>Apple</ns:COMPANIES>
</ns:getInformationRequest>
</ns:getInformation>
</body>
</transaction>
</root>
Max
Declaración
type Max(type de)
type Max(array arr)
Sintaxis
Max(<de>)
Max(<arr>)
Parámetros requeridos
de: (Primera forma) Una ruta de entidad a instancias de un elemento de datos en una fuente o un objetivoarr: (Segunda forma) Un arreglo; todos los elementos del arreglo deben ser del mismo tipo
Descripción
Devuelve el valor máximo de las instancias de un elemento de datos en un nivel particular de la jerarquía de una estructura de datos. Verificará todas las instancias en ese nivel y devolverá la más grande. También se puede utilizar para devolver el valor máximo de un arreglo.
Ejemplos
Suponga que una base de datos contiene un campo "Cantidad" en una tabla "Items" que es un hijo de "POHeader" (una orden de compra), y que hay muchos artículos dentro de un POHeader. Entonces, esta declaración devuelve el valor máximo de Cantidad para cualquier artículo de un POHeader particular:
Max(POHeader.Items#.Cantidad);
Min
Declaración
type Min(type de)
type Min(array arr)
Sintaxis
Min(<de>)
Min(<arr>)
Parámetros requeridos
de: (Primera forma) Una ruta de entidad a instancias de un elemento de datos en una fuente o un destinoarr: (Segunda forma) Un arreglo; todos los elementos del arreglo deben ser del mismo tipo
Descripción
Devuelve el valor mínimo de las instancias de un elemento de datos en un nivel particular de la jerarquía de una estructura de datos. Verificará todas las instancias en ese nivel y devolverá la más pequeña. También se puede utilizar para devolver el valor mínimo de un arreglo.
Ejemplos
Suponga que una base de datos contiene un campo "Cantidad" en una tabla "Items" que es un hijo de "POHeader" (una orden de compra), y que hay muchos artículos dentro de un POHeader. Entonces, esta declaración devuelve el valor mínimo de Cantidad para cualquier artículo de un POHeader particular:
Min(POHeader.Items#.Cantidad);
ResolveOneOf
Declaración
type ResolveOneOf(type de)
type ResolveOneOf(array arr)
Sintaxis
ResolveOneOf(<de>)
ResolveOneOf(<arr>)
Parámetros requeridos
de: (Primera forma) Una ruta de entidad a instancias de un elemento de datos en una fuente o un destinoarr: (Segunda forma) Un arreglo; todos los elementos del arreglo deben ser del mismo tipo
Descripción
Devuelve el primer valor no nulo de las instancias de un elemento de datos. Esta función se utiliza generalmente para recuperar el valor de un elemento de datos de origen "uno de". También se puede usar con arreglos y devolverá el primer elemento no nulo.
SetInstances
Declaración
null SetInstances(string nodeName, array de)
Sintaxis
SetInstances(<nodeName>, <de>)
Parámetros requeridos
nodeName: El nombre de un destinode: Una ruta de entidad a instancias de un elemento de datos en el destino
Descripción
Define las instancias de origen para un nodo de bucle de destino. Normalmente, una instancia de destino de bucle se genera a partir de una instancia de origen de bucle. A veces, los datos pueden provenir de otras fuentes. Esta función está destinada a casos donde los datos están en múltiples conjuntos y cada conjunto genera un único elemento de destino.
La instancia es un elemento de datos que podría ser un valor simple o un arreglo de elementos de datos. Al crear el destino, cada instancia se utilizará para generar una instancia de destino.
Para ver cómo usar un elemento de datos de instancia, consulte las funciones GetInstance y ArgumentList.
Esta función debe ser llamada en los mapeos del nodo padre del destino previsto. Si no hay un nodo hoja disponible en el padre, puede crear un nodo de condición que llame a esta función. La condición debe terminar con true para que siempre sea aceptada.
La función no debe ser llamada más de una vez con el mismo nodo de destino, ya que la última llamada anula las anteriores. Para evitar ser anulada, puede crear carpetas de mapeo múltiples.
Un elemento de datos nulo es devuelto por esta función y debe ser ignorado.
Ejemplos
Suponga que hay un padre común para los nodos de destino DETAILS y COMPANIES; ambos son nodos de bucle; y se ha creado una carpeta de mapeo múltiple para el nodo de destino DETAILS.
...
r1 = DBLookupAll("<TAG>endpoint:database/My Database</TAG>",
"SELECT key_name, key_value FROM key_values");
SetInstances("DETAILS", r1);
SetInstances("DETAILS#1", r1);
// DETAILS#1 is the name of the
// 1st multiple-mapping-folder for DETAILS
r2 = {"MS", "HP", "Apple"};
SetInstances("COMPANIES", r2);
// Note: Renaming the display name of a
// multiple-mapping-folder doesn't change
// the folder's actual name, which can be
// found by control-clicking the node and using
// "Copy node name to clipboard"
...
Ejemplo visual y salida
A continuación se muestra una configuración de esquema que aplica el ejemplo r2 anterior a un nodo de bucle getInformationRequest y un nodo de bucle de destino COMPANIES. DETAILS fue excluido por simplicidad.
El XML resultante si la salida se escribe directamente después de la transformación:
<?xml version="1.0" encoding="UTF-8"?>
<root xmlns="http://www.jitterbit.com/XsdFromWsdl" xmlns:ns="com.iex.tv.webservices.services.agentResourcesService" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<transaction>
<body>
<ns:getInformation>
<ns:getInformationRequest>
<ns:COMPANIES>MS</ns:COMPANIES>
<ns:COMPANIES>HP</ns:COMPANIES>
<ns:COMPANIES>Apple</ns:COMPANIES>
</ns:getInformationRequest>
</ns:getInformation>
</body>
</transaction>
</root>
SortInstances
Declaración
null SortInstances(string nodeName, array sourceDataElements1[, bool sortOrder, ..., array sourceDataElementsN, bool sortOrderN])
Sintaxis
SortInstances(<nodeName>, <sourceDataElements1>[, <sortOrder>, ..., <sourceDataElementsN>, <sortOrderN>])
Parámetros requeridos
nodeName: Nombre de los elementos de bucle de destino a ordenarsourceDataElements: Una ruta de entidad a instancias de un elemento de datos en una fuente o un destino
Parámetros opcionales
sourceDataElementsN: Una ruta de entidad a instancias de un elemento de datos en una fuente o un destinosortOrder: Un orden de clasificación opcional, por defecto verdadero para ascendente. El argumento no es opcional si se proporcionan múltiples argumentossourceDataElements.
Descripción
Ordena la generación de elementos de datos de bucle de destino en función de uno o más elementos de datos en la fuente o el destino.
Todas las instancias de ordenación deben tener el mismo número de instancias que el número de instancias de destino.
El orden de clasificación se asume como ascendente, y se puede colocar un argumento escalar opcional junto a cada elemento de datos de clasificación para anular el orden de clasificación predeterminado. Si sortOrder es falso, el orden de clasificación es descendente.
Los elementos de datos del bucle objetivo se clasificarán primero por las instancias de los primeros elementos de datos de origen, y luego se clasificarán por las instancias de los segundos elementos de datos, y así sucesivamente.
Esta función debe ser llamada en los mapeos del nodo padre. Si no hay un campo para mapear en el nodo padre, se puede llamar a un script con esta función o agregar una condición para ese propósito.
Se devuelve un valor nulo de esta función y debe ser ignorado.
Ejemplos
// The target node "detail" will be ordered
// by "price" from high to low and,
// if the prices are the same for two items,
// the node will be ordered by "quantity" from low to high
SortInstances("detail", Invoice$Item#.price, false, Invoice$Item#.quantity);
Este siguiente ejemplo podría usarse en una condición en un mapeo para clasificar todas las ventas de cada cliente por fecha. Se colocaría al nivel del nodo customer. Tenga en cuenta la inclusión de la declaración true al final del bloque de código para que la condición siempre sea aceptada:
<trans>
SortInstances("SalesOrders", _Root$customer.sales#.SalesDate);
true
</trans>
Sum
Declaración
type Sum(type de)
type Sum(array arr)
Sintaxis
Sum(<de>)
Sum(<arr>)
Parámetros Requeridos
de: (Primera forma) Una ruta de entidad a instancias de un elemento de datos en un origen o un destinoarr: (Segunda forma) Un arreglo; todos los elementos del arreglo deben ser del mismo tipo
Descripción
Toma el valor de cada instancia de un elemento de datos en un nivel jerárquico particular y devuelve la suma. El tipo de datos de de y arr debe ser uno de entero, largo, flotante, doble o cadena. Los tipos de datos de todas las instancias o todos los elementos deben ser los mismos.
Si el arreglo está vacío, se devuelve 0 (cero). Aunque los valores nulos serán ignorados en arreglos con otro tipo de datos, un arreglo que contenga solo nulos devolverá un error.
Ejemplos
Suponga una base de datos que contiene un campo "Cantidad" en una tabla "Items" que es un hijo de POHeader (hay muchos elementos dentro de un POHeader).
// Devuelve la suma del campo "Cantidad" para
// todos los elementos de un "POHeader" particular
Sum(POHeader.Items#.Cantidad);
SumCSV
Declaración
string SumCSV(tipo de)
string SumCSV(array arr)
Sintaxis
SumCSV(<de>)
SumCSV(<arr>)
Parámetros requeridos
de: (Primera forma) Una ruta de entidad a instancias de un elemento de datos en una fuente o un destinoarr: (Segunda forma) Un arreglo; todos los elementos del arreglo deben ser del mismo tipo
Descripción
Concatena cada instancia de un campo de un elemento de datos o cada elemento de un arreglo, con un delimitador de coma entre cada instancia o elemento.
Si el campo o el elemento del arreglo contiene caracteres especiales como saltos de línea o comas, el campo o el elemento del arreglo se encierra entre comillas dobles. No se agrega ningún delimitador después de que se concatena la última instancia o elemento.
Consulte también la función SumString para una función similar pero con opciones adicionales.
Ejemplos
// Concatena todas las instancias de un campo de direcciones de correo electrónico
// con una coma entre cada dirección
SumCSV(_Root$customer.contact#.Email);
SumString
Declaración
string SumString(tipo de[, string delimitador, bool omitirÚltimo])
string SumString(array arr[, string delimitador, bool omitirÚltimo])
Sintaxis
SumString(<de>[, <delimitador>, <omitirÚltimo>])
SumString(<arr>[, <delimitador>, <omitirÚltimo>])
Parámetros requeridos
de: (Primera forma) Una ruta de entidad a instancias de un elemento de datos en una fuente o un destinoarr: (Segunda forma) Un arreglo; todos los elementos del arreglo deben ser del mismo tipo
Parámetros opcionales
delimiter: Una cadena para delimitar los elementos; el valor predeterminado es un punto y comaomitLast: Una bandera que indica si se debe incluir el delimitador después del último elemento; el valor predeterminado es falso
Descripción
Concatena cada instancia de los elementos de datos especificados o cada elemento de un arreglo, con un delimitador automáticamente añadido al final de cada cadena concatenada.
Si el parámetro omitlast es verdadero, se omite el delimitador después de la última cadena.
Consulta también la función SumCSV.
Ejemplos
// Concatenates all instances of a field of email addresses
// with a comma between each address,
// but does not place a delimiter after the last address
SumString(_Root$customer.contact#.Email, ",", true);