Betriebsoptionen in Jitterbit Studio
Einführung
Konfigurieren Sie die Betriebsoptionen, um Zeitüberschreitungen, Protokollierung und Datenverarbeitung zu steuern. Die meisten Operationen funktionieren gut mit den Standardeinstellungen, aber Sie können sie an spezifische Bedürfnisse anpassen.
Zugriff auf Betriebsoptionen
Sie können die Einstellungen-Option für Operationen von diesen Orten aus aufrufen:
- Der Workflows-Tab im Projektbereich (siehe Komponentenaktionsmenü im Projektbereich Workflows-Tab).
- Der Komponenten-Tab im Projektbereich (siehe Komponentenaktionsmenü im Projektbereich Komponenten-Tab).
- Die Entwurfskanvas (siehe Komponentenaktionsmenü in Entwurfskanvas).
- Die Entwurfskanvas durch Doppelklicken auf die Operation (dies öffnet Einstellungen direkt).
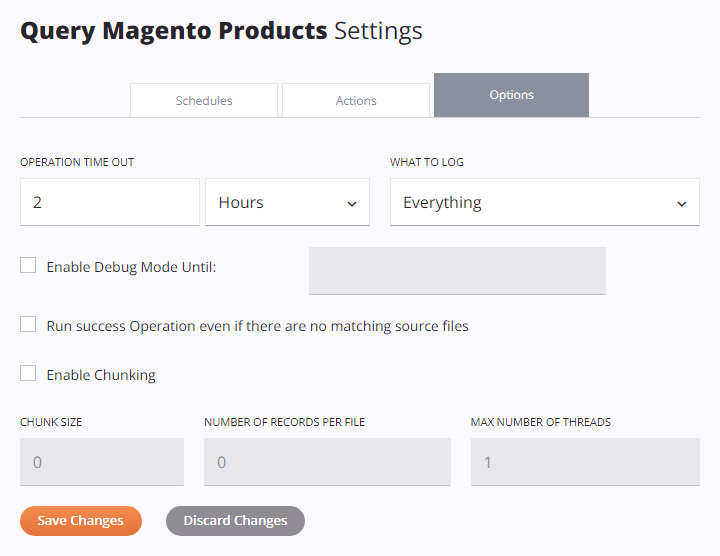
Nachdem der Bildschirm für die Betriebseinstellungen geöffnet ist, wählen Sie den Tab Optionen:

Konfigurieren von Betriebsoptionen
Die folgenden Abschnitte beschreiben jede Betriebsoption:
- Betriebszeitüberschreitung
- Was protokolliert werden soll
- Auf dediziertem Agenten ausführen
- Debug-Protokollierungsmodus aktivieren bis
- Erfolgreiche Operation ausführen, auch wenn keine passenden Quelldateien vorhanden sind
- Chunking aktivieren
- Salesforce-Bulk-Betriebsoptionen
Betriebszeitüberschreitung
Setzen Sie, wie lange die Operation läuft, bevor sie abgebrochen wird. Der Standardwert beträgt 2 Stunden, was für die meisten Operationen funktioniert.
Möglicherweise möchten Sie diese Einstellung aus folgenden Gründen anpassen:
-
Erhöhen Sie das Timeout für große Datensätze, die länger zur Verarbeitung benötigen. Geplante Operationen, die große Datenmengen verarbeiten, benötigen möglicherweise längere Timeouts. Wenn Ihre Datensätze die Timeout-Grenzen überschreiten, siehe Chunking aktivieren für Optionen, die große Datensätze in kleinere Chargen aufteilen und die Anzahl der pro Ausgabedatei geschriebenen Datensätze steuern.
-
Verringern Sie das Timeout für zeitkritische Operationen, die schnell abgeschlossen werden müssen.
Geben Sie eine Zahl ein und wählen Sie Sekunden, Minuten oder Stunden aus dem Dropdown-Menü.
Hinweis
Operationen, die durch API Manager APIs ausgelöst werden, ignorieren diese Einstellung bei Cloud-Agenten. Für private Agenten aktivieren Sie EnableAPITimeout in der Konfigurationsdatei des privaten Agenten, damit die Einstellung Operation Time Out für durch APIs ausgelöste Operationen gilt.
Was zu protokollieren ist
Wählen Sie aus, welche Informationen in den Betriebsprotokollen angezeigt werden:
- Alles: Protokolliert alle Betriebsaktivitäten (empfohlen).
- Nur Fehler: Protokolliert nur Operationen mit einem Fehlerstatus (wie Fehler, SOAP-Fehler oder Erfolg mit Kindfehler). Verwenden Sie diese Einstellung, wenn Sie Leistungsprobleme haben und keine detaillierten Protokolle benötigen. Erfolgreiche Kindoperationen werden nicht protokolliert. Elternoperationen (Root-Ebene) werden immer protokolliert, da sie für eine ordnungsgemäße Funktion protokolliert werden müssen.
Debugging
Der Abschnitt Debugging enthält Optionen, um eine Operation auf einem dedizierten Agenten auszuführen und den Debug-Modus zu aktivieren.
Auf dediziertem Agenten ausführen
Leiten Sie diese Operation zur Ausführung auf einem bestimmten Agenten als vorübergehende Fehlersuche-Maßnahme. Diese Option gilt nur für private Agentengruppen, die mit einer Hochverfügbarkeit (HA) Agentengruppenkategorie konfiguriert sind. Verwenden Sie sie, um Fehler auf einem bestimmten Agenten zu reproduzieren oder um einen problematischen Agenten zu umgehen, während der Rest der Gruppe betriebsbereit bleibt.
Um diese Option zu aktivieren, wählen Sie das Kontrollkästchen Auf dediziertem Agenten ausführen aus und konfigurieren Sie Folgendes:
-
Wählen Sie einen Agenten aus: Wählen Sie den spezifischen Agenten innerhalb der HA-Gruppe aus, der für die Ausführung dieser Operation verwendet werden soll. Wenn der von Ihnen ausgewählte Agent gelöscht wird, während diese Option aktiv ist, wird die Ausführung auf einem dedizierten Agenten automatisch deaktiviert und die Operation wechselt zur Standardausführung der Agentengruppe.
-
Bis: Wählen Sie ein Datum bis zu zwei Wochen ab heute. Die Ausführung auf einem dedizierten Agenten wird an diesem Datum automatisch deaktiviert, und die Operation wechselt zum Standardverhalten der Agentengruppe.
-
Auf untergeordnete Operationen anwenden: Wenn die Operation untergeordnete Operationen hat, wird dieses Kontrollkästchen angezeigt. Wählen Sie es aus, um alle untergeordneten Operationen auf demselben Agenten wie die übergeordnete Operation auszuführen.
Wenn Auf dediziertem Agenten ausführen aktiviert ist, erscheint eine Warnung.
Dialog
Die Ausführung dieser Operation auf einem einzelnen Agenten umgeht Ihre Hochverfügbarkeitskonfiguration (HA). Wenn dieser Agent ausfällt oder die Kapazität erreicht, wird die Operation ohne Failover gestoppt.
Debug-Modus bis aktivieren
Aktivieren Sie detaillierte Protokollierung zur Fehlersuche. Wählen Sie ein Datum bis zu zwei Wochen ab heute. Der Debug-Modus wird an diesem Datum automatisch deaktiviert.
Warnung
Bei Cloud-Agentengruppen ist die Dauer dieser Einstellung unzuverlässig. Protokolle können vor dem Ende des ausgewählten Zeitraums nicht mehr erstellt werden.
Wenn Sie den Debug-Modus für Operationen mit untergeordneten Operationen aktivieren, können Sie dieselbe Einstellung auf alle untergeordneten Operationen anwenden, indem Sie das Kontrollkästchen Auch auf untergeordnete Operationen anwenden auswählen.
Die Debug-Protokollierung erzeugt verschiedene Arten von Protokollen, basierend auf Ihrem Agententyp:
| Protokolltyp | Protokollbeschreibung | Agenttyp |
|---|---|---|
| Debug-Protokolldateien | Debug-Protokolldateien für detaillierte Fehlersuche. Diese Dateien können direkt auf dem Agenten zugegriffen oder über die Management-Konsole heruntergeladen werden. Das Debug-Logging kann auch für das gesamte Projekt direkt vom privaten Agenten selbst aktiviert werden (siehe Betriebs-Debug-Logging). Die Debug-Protokolldateien sind direkt auf privaten Agenten zugänglich und können über die Seiten Agenten und Laufzeit der Management-Konsole heruntergeladen werden. Warnung Der Debug-Modus erstellt große Protokolldateien. Nur während des Testens verwenden, nicht in der Produktion. |
Nur private Agenten |
| Eingabe- und Ausgabekomponenten | Anforderungs- und Antwortdaten (30 Tage aufbewahrt). Zugriff über die Seite Laufzeit der Management-Konsole. Vorsicht Komponenten-Eingabe- und Ausgabedaten werden immer in der Harmony-Cloud protokolliert, selbst wenn Cloud-Protokollierung deaktiviert ist. Um dies bei privaten Agenten zu stoppen, setzen Sie Debug-Protokolle enthalten alle Anforderungs- und Antwortdaten, einschließlich sensibler Informationen wie Passwörter und personenbezogene Daten (PII). Diese Daten erscheinen im Klartext in den Harmony-Cloud-Protokollen für 30 Tage. |
Cloud- und private Agenten |
| API-Betriebsprotokolle | Protokolle für erfolgreiche API-Betriebsvorgänge (konfiguriert für benutzerdefinierte APIs oder OData-APIs). Standardmäßig werden nur API-Betriebsvorgänge mit Fehlern in den Betriebsprotokollen protokolliert. |
Cloud- und private Agenten |
Führen Sie die Erfolgsoperation aus, auch wenn keine übereinstimmenden Quelldateien vorhanden sind
Diese Option zwingt eine Operation zum Erfolg, selbst wenn ihr Trigger fehlschlägt. Dadurch können andere Operationen, die Bei Erfolg dieser Operation ausgelöst werden, unabhängig vom Ergebnis der ursprünglichen Operation ausgeführt werden. Sie gilt nur, wenn die ursprüngliche Operation eine Quellaktivität für einen dieser Connectoren enthält:
Standardmäßig werden alle Bei Erfolg-Operationen nur ausgeführt, wenn sie eine übereinstimmende Quelldatei zum Verarbeiten haben. Diese Option kann nützlich sein, um spätere Teile eines Projekts einzurichten, ohne den Erfolg einer abhängigen Operation zu erfordern.
Hinweis
Die Einstellung AlwaysRunSuccessOperation in der Konfigurationsdatei des privaten Agents überschreibt diese Option.
Chunking aktivieren
Chunking zerlegt große Datensätze in kleinere Teile (Batches). Dies beschleunigt die Verarbeitung und hilft, die API-Datensatzlimits einzuhalten. Für einen aufgabenorientierten Leitfaden zur Auswahl der Chunk-Größe, paralleler Verarbeitung und Variablenbereich sehen Sie sich Chunking von Operationen für große Datensätze konfigurieren an.
Um Chunking zu aktivieren, muss Ihre Operation eine Transformation oder eine Aktivität von einem dieser Connectoren enthalten:
Hinweis
Chunking wird nicht unterstützt, wenn die Quelle ein auf Connector SDK-basierten Connector (angezeigt als SDK in der Spalte Connector-Typ der Connector-Liste) ist. Wenn Ihre Quelle SDK-basiert ist, teilen Sie die Operation in zwei Teile: Verwenden Sie eine Variable Write-Aktivität als Ziel der ersten Operation und verwenden Sie dann eine Variable Read-Aktivität als Quelle in der zweiten Operation mit aktiviertem Chunking.
Verwenden Sie Chunking in diesen Situationen:
- Sie verarbeiten große Datensätze mit Tausenden von Datensätzen.
- Sie verwenden Webdienste mit Datensatzgrenzen. Zum Beispiel erlaubt Salesforce nur 200 Datensätze pro Aufruf.
- Sie möchten mehrere CPU-Kerne für die parallele Verarbeitung nutzen.
Tipp
Für Hinweise, wann Batch- versus ereignisgesteuerte Verarbeitung in Integrationsprojekten verwendet werden sollte, siehe Batch- und ereignisgesteuerte Verarbeitung.
Wenn eine Salesforce, Salesforce Service Cloud oder ServiceMax Aktivität in der Operation enthalten ist, wird Chunking automatisch aktiviert.
Wenn diese Einstellung aktiviert ist, konfigurieren Sie diese Felder:
-
Chunk-Größe: Die Anzahl der Datensätze in jedem Chunk. Standard ist
1für die meisten Operationen und200für Salesforce-Operationen.Hinweis
Wenn Sie eine (Salesforce, Salesforce Service Cloud oder ServiceMax) Bulk-Aktivität verwenden, ändern Sie diesen Standard auf eine viel größere Zahl, wie z.B.
10.000. -
Anzahl der Datensätze pro Datei: Die Anzahl der Datensätze, die in jede Zieldatei (Batch) geschrieben werden sollen. Standard ist
0, was bedeutet, dass es keine Begrenzung gibt. -
Maximale Anzahl von Threads: Die Anzahl der Verarbeitungsthreads, die gleichzeitig ausgeführt werden. Standardmäßig ist dies
1für die meisten Operationen und2für Salesforce-Operationen.
Warnung
Chunking beeinflusst, wie globale und Projektvariablen funktionieren. Nur Änderungen vom ersten Thread werden beibehalten. Siehe detaillierte Informationen zum Chunking unten.
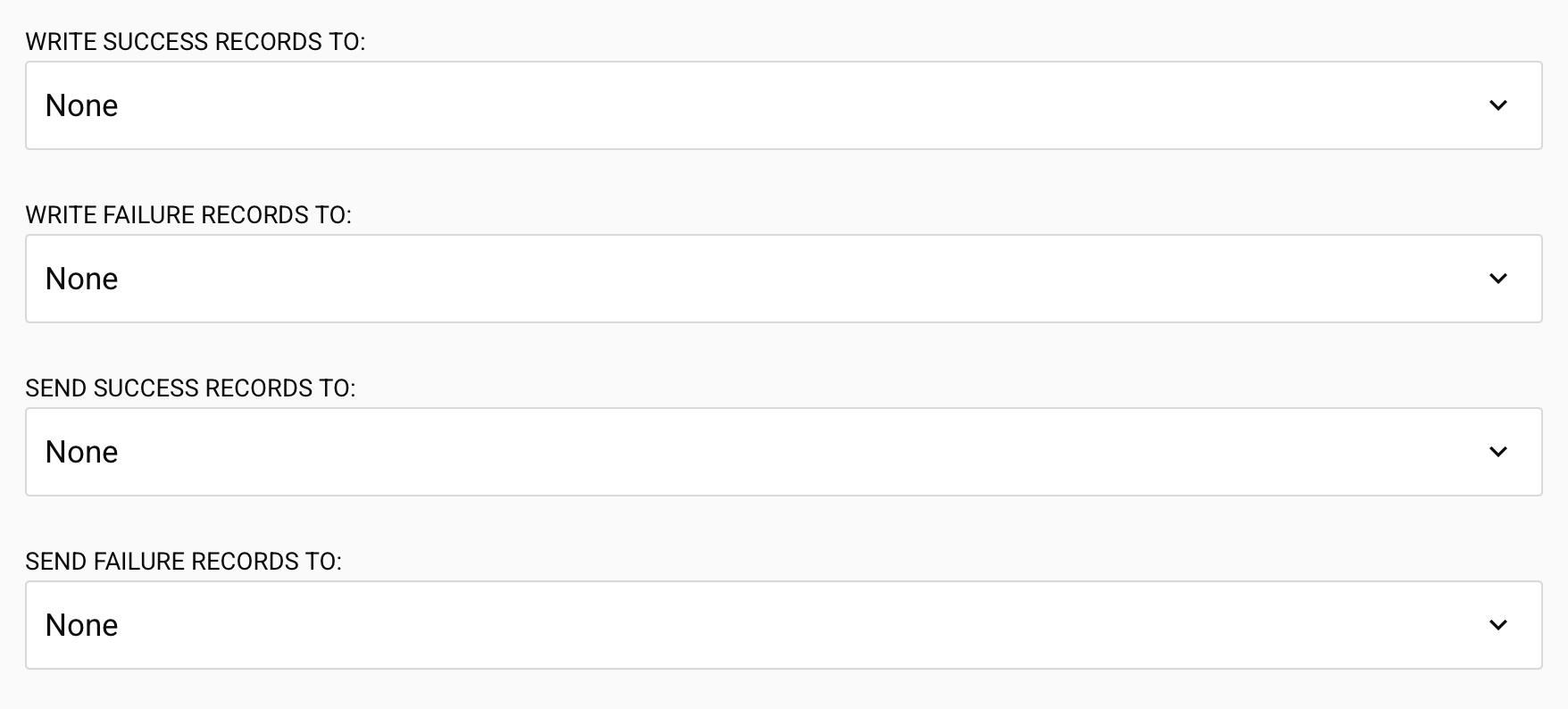
Salesforce-Bulk-Operationsoptionen
Die folgenden Optionen erscheinen nur für Salesforce, Salesforce Service Cloud und ServiceMax Bulk-Operationen (außer Bulk Query-Operationen):
-
Erfolgreiche Datensätze schreiben nach: Wählen Sie aus, wohin erfolgreiche Datensätze nach Abschluss der Bulk-Operation gesendet werden sollen. Wählen Sie aus konfigurierten dateibasierten Aktivitäten: HTTP, API, FTP, Dateifreigabe, Lokaler Speicher, Temporärer Speicher oder Variable. Standard: Keine.
-
Fehlerhafte Datensätze schreiben nach: Wählen Sie aus, wohin fehlgeschlagene Datensätze nach Abschluss der Bulk-Operation gesendet werden sollen. HTTP, API, FTP, Dateifreigabe, Lokaler Speicher, Temporärer Speicher oder Variable. Standard: Keine.
Wichtig
Wenn Sie Variable-Aktivitäten verwenden, können nur Operationen in derselben Operation-Kette während der Laufzeit auf den Variablenwert zugreifen.
-
Erfolgreiche Datensätze senden an: Wählen Sie eine E-Mail-Benachrichtigung, um erfolgreiche Datensätze zu erhalten. Wählen Sie aus den konfigurierten E-Mail-Benachrichtigungen. Standard: Keine.
-
Fehlerhafte Datensätze senden an: Wählen Sie eine E-Mail-Benachrichtigung, um fehlerhafte Datensätze zu erhalten. Wählen Sie aus den konfigurierten E-Mail-Benachrichtigungen. Standard: Keine.
Hinweis
Dateibasierte Aktivitäten und E-Mail-Benachrichtigungen, die in diesen Optionen ausgewählt sind, müssen nicht Teil einer bestehenden bereitgestellten Operation sein. Das Studio wird diese Komponenten automatisch bereitstellen und verwalten, wenn sie ausgewählt werden.
Detaillierte Chunking-Informationen
Chunking wird verwendet, um die Quelldaten basierend auf der konfigurierten Chunk-Größe in mehrere Chunks (Batches) zu unterteilen. Die Chunk-Größe ist die Anzahl der Quelldatensätze (Knoten) für jeden Chunk. Die Transformation wird dann für jeden Chunk separat durchgeführt, wobei jeder Quell-Chunk einen Ziel-Chunk produziert. Die resultierenden Ziel-Chunks kombinieren sich, um das endgültige Ziel zu erzeugen.
Chunking kann nur verwendet werden, wenn die Datensätze unabhängig und aus einer nicht-LDAP-Quelle stammen. Wir empfehlen, eine so große Chunk-Größe wie möglich zu verwenden, wobei sichergestellt wird, dass die Daten für einen Chunk in den verfügbaren Speicher passen. Für zusätzliche Methoden zur Begrenzung des Speicherverbrauchs einer Transformation siehe Transformation-Verarbeitung.
Warnung
Die Verwendung von Chunking beeinflusst das Verhalten von globalen und Projektvariablen. Siehe Verwendung von Variablen mit Chunking unten.
API-Beschränkungen
Viele Webservice-APIs (SOAP/REST) haben Größenbeschränkungen. Zum Beispiel akzeptiert ein Salesforce-basiertes Upsert nur 200 Datensätze pro Aufruf. Bei ausreichendem Speicher könnten Sie eine Operation so konfigurieren, dass sie eine Chunk-Größe von 200 verwendet. Die Quelle würde in Chunks von jeweils 200 Datensätzen unterteilt, und jede Transformation würde den Webservice einmal mit einem 200-Datensatz-Chunk aufrufen. Dies würde wiederholt, bis alle Datensätze verarbeitet sind. Die resultierenden Zieldateien würden dann kombiniert. (Beachten Sie, dass Sie auch Salesforce-basierte Bulk-Aktivitäten verwenden könnten, um die Verwendung von Chunking zu vermeiden.)
Parallelverarbeitung
Wenn Sie eine große Quelle und einen Multi-CPU-Computer haben, kann Chunking verwendet werden, um die Quelle für die parallele Verarbeitung zu teilen. Da jeder Chunk isoliert verarbeitet wird, können mehrere Chunks parallel verarbeitet werden. Dies gilt nur, wenn die Quellaufzeichnungen auf der Ebene der Chunk-Knoten unabhängig voneinander sind. Webdienste können parallel unter Verwendung von Chunking aufgerufen werden, was die Leistung verbessert.
Bei der Verwendung von Chunking in einem Vorgang, bei dem das Ziel eine Datenbank ist, beachten Sie, dass die Zieldaten zunächst in zahlreiche temporäre Dateien (eine für jeden Chunk) geschrieben werden. Diese Dateien werden dann zu einer Zieldatei kombiniert, die an die Datenbank zum Einfügen/Aktualisieren gesendet wird. Wenn Sie die Jitterbit-Variable jitterbit.target.db.commit_chunks auf 1 oder true setzen, während Chunking aktiviert ist, wird jeder Chunk stattdessen an die Datenbank übergeben, sobald er verfügbar ist. Dies kann die Leistung erheblich verbessern, da die Datenbankeinfügungen/Aktualisierungen parallel durchgeführt werden.
Variablen mit Chunking verwenden
Da Chunking Multi-Threading auslösen kann, kann seine Verwendung das Verhalten von Variablen beeinflussen, die nicht zwischen den Threads geteilt werden.
Globale und Projektvariablen sind zwischen den Instanzen des Chunkings segregiert, und obwohl die Daten kombiniert werden, sind Änderungen an diesen Variablen nicht vorhanden. Nur Änderungen, die im ursprünglichen Thread vorgenommen werden, werden am Ende der Transformation beibehalten.
Wenn ein Vorgang — mit Chunking und mehreren Threads — eine Transformation hat, die eine globale Variable ändert, ist der Wert der globalen Variable nach dem Ende des Vorgangs der aus dem ersten Thread. Alle Änderungen an der Variablen in anderen Threads sind unabhängig und werden verworfen, wenn der Vorgang abgeschlossen ist.
Diese globalen Variablen werden den anderen Threads nach Wert und nicht nach Referenz übergeben, wodurch sichergestellt wird, dass Änderungen an den Variablen nicht in anderen Threads oder Vorgängen widergespiegelt werden. Dies ähnelt der Funktion RunOperation, wenn sie im asynchronen Modus ist.