Estructuras de datos en Jitterbit Integration Studio
Introducción
Las estructuras de datos se pueden proporcionar como esquemas durante la configuración de la actividad o pueden ser definidos dentro de la transformación en sí. Cuando se proporcionan estructuras de datos en una actividad, la transformación hereda los esquemas utilizando la actividad como origen o destino en la operación. Una vez definidos los esquemas de origen y destino de una transformación, se crean asignaciones de transformación entre ellos para definir cómo se deben procesar los datos.
Para obtener información sobre cómo resolver ciertos errores de ejecución de operación causados por estructuras de datos, consulte Solución de problemas de operaciones.
Tipos de estructuras de datos
En Harmony, los esquemas de origen y destino pueden usar estructuras de datos que se consideran planas o jerárquico.
Estructura plana
Una estructura de datos plana consta de uno o más campos y registros individuales en una estructura bidimensional. Algunos ejemplos son archivos CSV, archivos XML simples y tablas de bases de datos individuales. Una estructura de datos plana también se conoce como estructura de archivo plano.
<customer>
<id>10123</id>
<name>ABC Co.</name>
<street>1 Main St.</street>
<city>Anytown</city>
<state>NY</state>
<zip>12345</zip>
</customer>
Estructura jerárquica
Una estructura de datos jerárquica tiene una o más relaciones padre-hijo o anidadas entre campos y registros en una estructura compleja. A veces se denomina estructura de datos relacional, multinivel, compleja o de árbol.
<customer>
<id>10123</id>
<name>ABC Co.</name>
<addresses>
<address>
<street>1 Main St.</street>
<city>Anytown</city>
<state>NY</state>
<zip>12345</zip>
</address>
<address>
<street>1 Time Square</street>
<city>New York City</city>
<state>NY</state>
<zip>54321</zip>
</address>
</addresses>
</customer>
Visualización de estructuras de datos
Las estructuras de datos se muestran en formato de árbol, que puede expandirse y contraerse para mostrar el árbol completo o solo una parte.
Cada árbol consta de nodos y campos, donde los campos dentro de la estructura de datos de origen se pueden asignar a campos dentro de la estructura de datos de destino.
Los nodos tienen un triángulo desplegable a la izquierda de su nombre que permite contraerlos o expandirlos. De forma predeterminada, los nodos se expanden hasta 8 niveles de profundidad en esquemas con 750 nodos o menos, y hasta 5 niveles en esquemas con más de 750 nodos. Todos los nodos debajo de un nodo de destino se pueden expandir a la vez mediante la opción Expandir todos los nodos debajo de este nodo del menú de acciones del esquema (véase Nodos de destino en Modo de mapeo). Si expande o contrae nodos, Integration Studio recuerda el último estado de expansión que estaba usando la próxima vez que acceda a la transformación.
Una vez expandidos, los nodos muestran los nodos secundarios y campos que contienen. Los nodos pueden considerarse carpetas con nodos secundarios como subcarpetas. Los campos están contenidos dentro de los nodos y se listan con su tipo de dato (boolean, integer, double, binary, string).
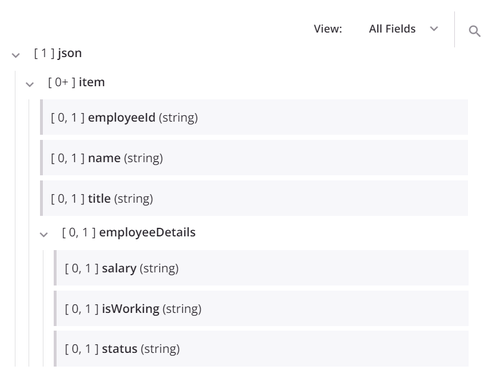
Por ejemplo, en la estructura de destino que se muestra a continuación, el nodo json incluye el nodo hijo item, que contiene los campos employeeId, name, y title. El nodo item También contiene el nodo hijo employeeDetails, que contiene los campos salary, isWorking, y status.
Visualización de campos mapeados
Una asignación de transformación consta de campos o nodos de destino y sus secuencias de comandos correspondientes. Estos secuencias de comandos pueden contener referencias a campos o nodos de origen, a componentes del proyecto, usar funciones o contener otra lógica de secuencia de comandos válida. Una asignación no incluye campos de destino que no estén asignados.
Cuando se definen objetos y variables de origen dentro del campo de destino, aparecen como bloques dentro de este. El campo de destino asignado se muestra con una línea vertical morada a la izquierda del bloque.
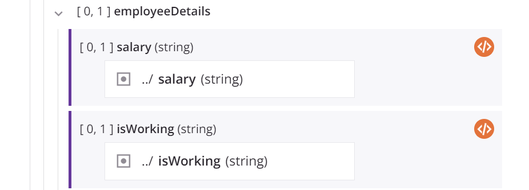
Cuando está en modo de mapeo y tanto un esquema de origen como uno de destino son visibles en la pantalla, una línea gris clara visual muestra la conexión con el objeto de origen cuando pasa el cursor sobre un campo de origen o de destino.
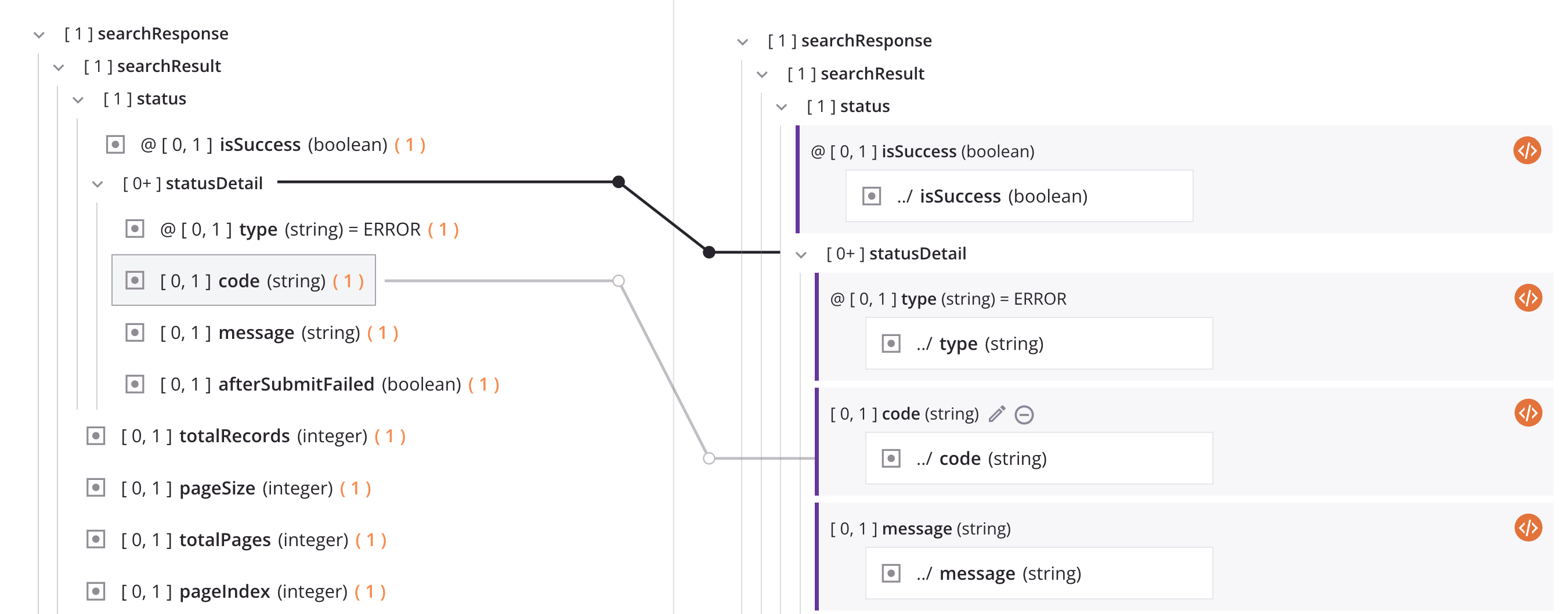
La línea negra continua que se muestra en la imagen superior se explica en la siguiente sección, Nodos de bucle.
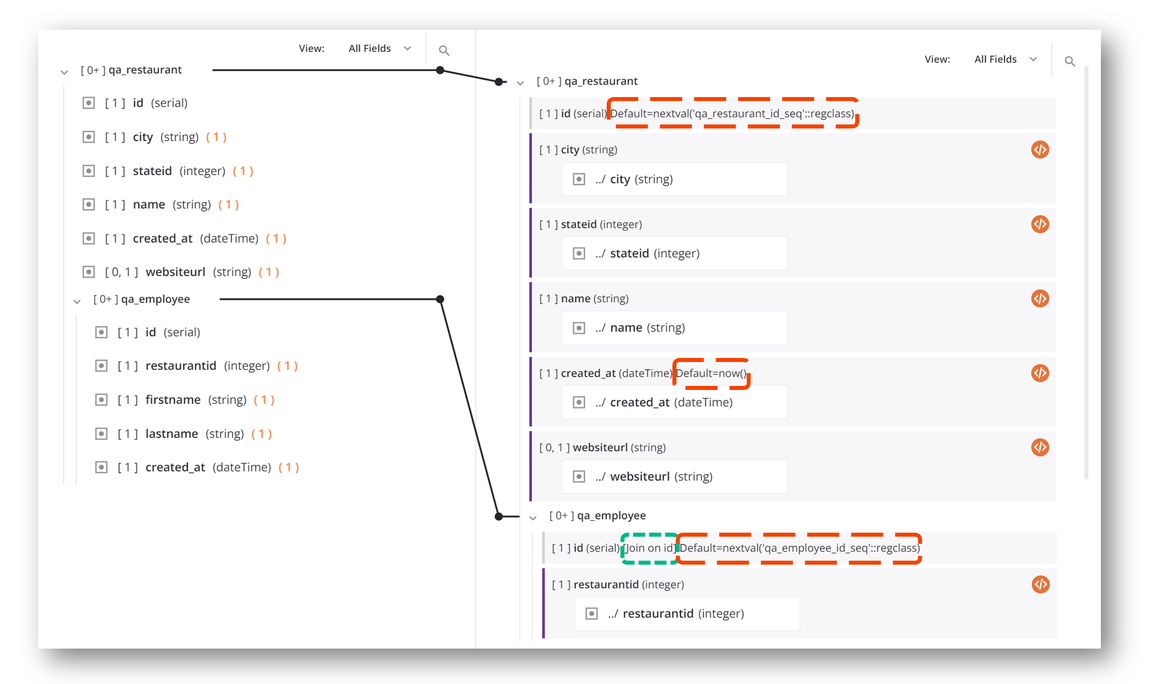
El lado de destino de la asignación también indica si un campo tiene valores predeterminados (señalados en rojo en la imagen a continuación) o uniones (señalados en verde en la imagen a continuación). Por ejemplo, esta transformación inserta datos en una base de datos cuya id Los campos se incrementan automáticamente y cuyos created_at El campo se establece igual a la hora actual de forma predeterminada. También muestra que la tabla secundaria qa_employee Se ha unido en el campo id a su tabla principal. qa_restaurant:
Si un nodo contraído contiene asignaciones de campos de destino, dicho nodo se muestra en negrita para indicar que contiene asignaciones:

Nodos de bucle
Un nodo de bucle es un nodo de origen o destino con valores de datos repetidos, como artículos de línea en una factura o un conjunto de registros de clientes.
Al asignar los campos de nodo de bucle, aparece automáticamente una línea negra sólida de iterador, lo que indica que el proceso de transformación recorrerá el conjunto de datos de origen. La ubicación de las líneas de iterador generadas depende de la multiplicidad de los nodos de bucle de origen correspondientes.
Una transformación puede tener cero o más líneas de iterador. Cuando hay varias líneas de iterador, la precedencia se da de arriba a abajo en la estructura de destino.
Para alternar la visualización de una línea de iterador individual, haga clic directamente en la forma circular más cercana al nodo de destino:
![]()
La línea del nodo de bucle se convierte en un trozo naranja que, al hacer clic de nuevo, muestra la línea completa:
Ejemplo
Como ejemplo de mapeo de nodos de bucle, considere la siguiente estructura jerárquica de origen que contiene un nodo de origen de nivel superior (item) con campos que proporcionan información sobre una empresa. Un nodo de origen secundario, locationDetails, incluye una matriz (json$item.locationDetails$item.) de objetos con campos para múltiples ubicaciones de tiendas dentro de una empresa. Tanto el nodo principal como el secundario se consideran nodos de bucle porque los datos pueden contener múltiples registros de empresa con múltiples registros de ubicación de tienda para cada empresa.
Ahora, considere que estos datos se asignan a una estructura de destino plana, lo que resulta en un registro para cada ubicación de tienda. Al asignar campos, aparece automáticamente una línea de iteración que conecta los nodos de bucle de origen y destino. Esta línea indica que el destino se repetirá tantas veces como conjuntos de datos repetidos haya en el origen o, en este ejemplo, recorrerá cada registro de ubicación de tienda para cada empresa.
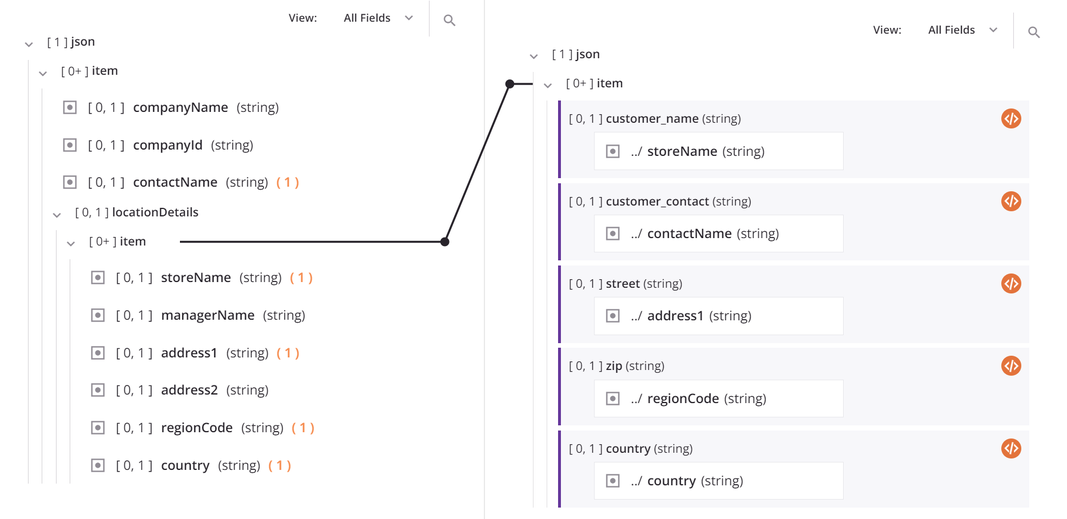
Mapa desde una fuente de múltiples instancias a un destino de instancia única
Cuando el objetivo generado nodo de bucle depende de más de un nodo del bucle de origen, es posible que deba resolver una discrepancia de ocurrencia con la asignación.
Si la estructura de datos de origen es una matriz multiobjeto y se asigna a una estructura de datos de destino con un solo objeto, se muestra este cuadro de diálogo:

Para usar la primera instancia de la fuente en la asignación, seleccione Sí para insertar automáticamente un símbolo de almohadilla. (#) en la ruta de referencia del elemento de datos. Esto significa que solo se asignará el primer registro. Por ejemplo, dada la siguiente asignación, solo el primer registro de cliente de la matriz se asigna a la estructura de destino que contiene un solo cliente. Observe que cada campo de destino asignado ahora contiene un secuencia de comandos, como se indica con el icono de secuencia de comandos.
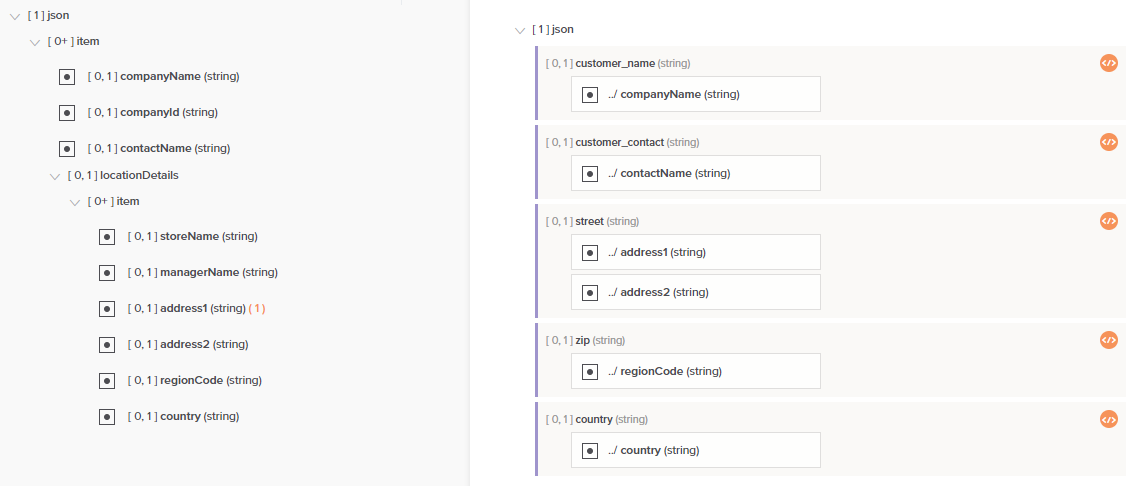
Cuando cambia al modo de secuencia de comandos para cualquier campo asignado, verá que un #1 Se ha añadido una propiedad dentro de la ruta del objeto de origen mapeado para indicar que la primera instancia está mapeada.

Normalización de datos
Si está asignando datos de una estructura plana a una estructura jerárquica, es posible que sea necesario normalizar los datos antes de transformarlos.
De forma predeterminada, Harmony utiliza un algoritmo de normalización para construir el árbol de destino. Esto convierte la estructura plana del origen en una estructura jerárquica del origen que posteriormente puede asignarse a la estructura jerárquica del destino.
En la estructura de destino, el elemento raíz y todos los elementos de instancia múltiple bajo la raíz se utilizan para crear la estructura de elementos fuente secundarios. Los atributos (o campos) de estos elementos fuente secundarios son elementos de datos planos que se utilizan en las asignaciones del elemento de destino correspondiente.
Con la estructura de origen correctamente definida, el proceso de normalización se simplifica para combinar nodos con los mismos padres.
Hay tres opciones para la normalización:
Normalización completa: Todos los elementos con el mismo padre y todos los campos se reducen a un solo elemento. (Esta es la opción predeterminada).
- Normalización parcial: Lo mismo que la normalización completa, excepto que los hijos más bajos no están normalizados.
- Sin normalización: Cada registro plano crea una rama de elementos; no se realiza ninguna reducción de elementos al crear la estructura fuente jerárquica.
La estructura jerárquica puede contener un solo nodo de instancia. En ese caso, solo se conservará el primer elemento de esta raíz y se ignorarán los registros planos que entren en conflicto con este nodo de datos raíz.
Para deshabilitar la normalización, configure la variable Jitterbit jitterbit.transformation.disable_normalization a true (vea Variables de Jitterbit de Transformación)
Mapeo de instancias y múltiples
El mapeo de Transformación es el proceso utilizado para definir la relación entre las entradas y la salida resultante. Según el tipo de estructura de datos utilizado, el mapeo de transformación puede describirse como mapeo de instancias o mapeo múltiple.
Mapeo de instancias
El mapeo de instancias describe cuándo el mapeo de una instancia de destino depende posiblemente de más de una instancia de origen. El mapeo de instancias puede ser de plano a plano (uno a uno) o de jerárquico a plano (muchos a uno).
Mapeo múltiple
El mapeo múltiple describe el mapeo de dos estructuras de datos jerárquicas o el mapeo desde una única estructura plana de naturaleza jerárquica, cuyos segmentos inferiores contienen múltiples conjuntos de valores, como pares nombre-valor. El mapeo múltiple puede ser de jerárquico a jerárquico (muchos a muchos) o de plano a jerárquico (uno a muchos).
Ejemplos
Se pueden encontrar ejemplos de situaciones tanto para la asignación de instancias como para la asignación múltiple en la documentación de Design Studio:
- Mapeo de instancias
- Mapeo Múltiple
Aunque estos ejemplos son para Design Studio, los mismos conceptos se pueden aplicar en Integration Studio.
Para obtener módulos de capacitación práctica que tienen ejemplos de mapeo de archivos de bases de datos, texto y XML simples y complejos, consulte Introducción a Jitterbit Integration Studio.