Integration project methodology for Jitterbit Studio
Introduction
Let's face it: integration projects can be tough, with many potential landmines. If integration is "data in motion," there are times when the data isn't interested in moving. Integration projects are highly dependent on endpoints and therefore can have risks that are outside the control of the integrator.
In the ideal world, endpoints are stable, have well-documented APIs, and have clear error responses. There are readily available SMEs (subject matter experts), and non-production environments are available for both development and testing. Also, the project is well-funded, is an absolute priority for management, and there is adequate time for testing. If this sounds like your project, congratulations! For the rest of us, read on.
Approach
When you know there is a field full of landmines, you have two choices:
-
Move very carefully and deliberately, survey the entire landscape down to the smallest detail, and build only when everything is known.
-
Get going as soon as possible, identify any landmines early and celebrate the detonations…because uncovering problems early is far superior to uncovering them later.
Right, so number 2 it is. Strap in, we're going to move fast.
Audience
The target audience is a project manager (PM) or technical lead who has general IT experience and now is leading an integration project using Jitterbit iPaaS.
This includes those with roles such as a Jitterbit partner doing general integration work, an application vendor also taking on the task of building the integrations from your product to all the customer's endpoints, or a customer PM, implementing Jitterbit iPaaS alone or with help from Jitterbit Professional Services.
Focus
The focus of this document is not how to use Jitterbit technically (check out the other documentation for the technical nitty-gritty) but instead addresses the key items a PM for an integration project should know. This guide shows how to organize your team, gather and validate requirements clearly and concisely, and leverage the strengths of Jitterbit iPaaS to deliver a successful project.
Scoping
Scoping is a two-part process involving gathering information, outlining the boundaries of the project, and getting the basic information needed to implement the project:
- Rough order of magnitude: Estimate a high-level Rough Order of Magnitude (ROM) for the work (can be skipped for certain endpoints).
- Scope of work: Refine the estimate by detailing a Scope of Work (SOW) for delivering the project.
This process is sensitive to the concept of GIGO — Garbage In, Garbage Out — so don't short-change it. The spreadsheet below is used as a starting point for the scoping process. Specific terminology used in this spreadsheet will be defined later in the Rough order of magnitude and Scope of work subsections.
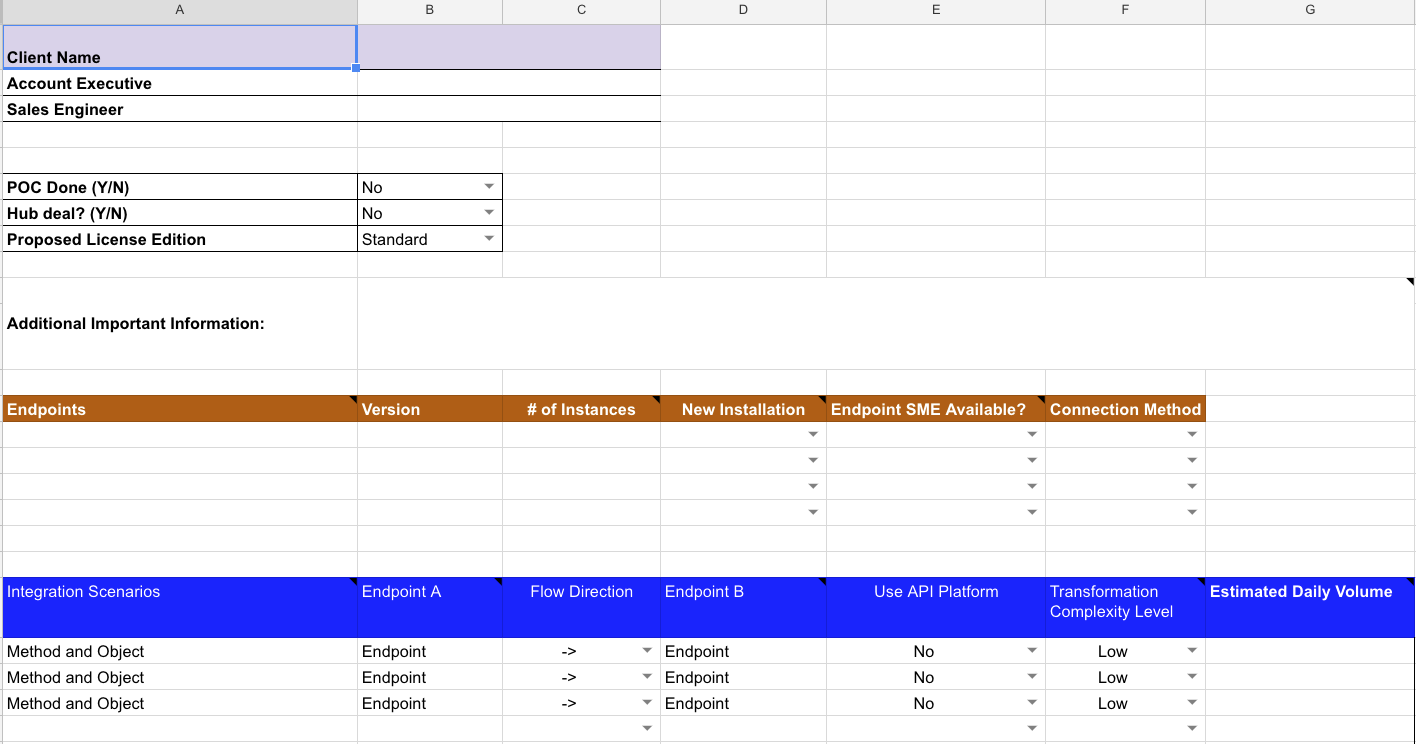
Rough order of magnitude (ROM)
Going into this step, there is a presumption that there has been enough analysis by the customer to determine what interfaces need to be built. At a high level, interfaces are needed when a business process crosses application boundaries. If the business processes are not firm, then neither is the integration, and it may be too early to estimate.
The Rough Order of Magnitude (ROM) is designed to stay high-level and facilitate quick turnaround to support customer planning and decision making. ROM estimates rely on these elements:
- Endpoints: This is the "thing" that Jitterbit iPaaS will interact with to read/write data to/from. This can be an application with a set of remote methods, a file-based system such as FTP or internal file systems, a database, or a web application exposing APIs.
- Integration Scenario: This is the description of the movement of data needed to accomplish the integration goal. "Synchronize Accounts," "Create Purchase Orders," or "Get Shipment Information" are examples.
- Object: This can be an SFDC (Salesforce) object (such as account or product), a database table, or a virtual business object, such as purchase orders in an EDI document.
- Method: This is what is being done with the data, such as CRUD (create, read, update, and delete).
- Transformation Complexity Level: This can be one of these levels:
- Low: Uses endpoint connectors, a low number of transformations, and one or two operations to the scenario.
- Medium: May or may not use endpoint connectors, uses a number of transformations and external lookups, and uses several operations per scenario.
- High: No endpoint connectors, numerous scenario steps, and the endpoint is known to be challenging.
Heuristics are used to generate hours. Formulas are used based on the number of scenarios and complexity to arrive at an estimate, which can easily be off by as much as 15–20%. Think of this as a budget number to be used early in the process.
The ROM estimate assumes a Jitterbit iPaaS expert is doing the work with some light project management. It also is end-to-end: from initiation through post–go-live. The time to build an integration does not correspond one-for-one with elapsed time. Actual timing will depend on staffing levels, the stability of customer endpoints, availability of customer SMEs, etc. Erring on the side of caution, we assume a 3:1 ratio of calendar duration to estimated hours.
Scope of work (SOW)
The Scope of Work (SOW) is designed to provide more details in order to get a clearer picture of the project and to provide a check or recalculation of the ROM estimate. For certain endpoints (such as SAP) or types of project (such as Hub deals), you can skip the ROM process and go straight to the SOW step.
During this step, you should arrange a scoping session to finalize details and answer open questions. Ideal attendees include business users (and all process owners) and endpoint SMEs. Including the latter is key, since otherwise it can be difficult to get into the details.
This is the best chance to clarify the risk profile of the project, so listen carefully and ask questions. Cover these topics:
-
Endpoints
-
Versions: Versions to be used or encountered.
-
On/off-premises: If on-premises, be sure to cover the use of Cloud versus private agents. A common concern is network security, such as opening up the firewall for private agents, so assure the customer and stakeholders that this is not a security concern. Provide a link to the Jitterbit security and architecture white paper and the Host system requirements for private agents.
-
Support: How the endpoint(s) are supported (internally/externally).
-
Lifecycle stages: In development/pre-production, maintenance, undergoing upgrades, sunset.
-
-
Endpoint Expertise
- Internal vs. external expertise: If a complex endpoint, like an ERP or CRM, there is usually either in-house expertise in the IT department, or implementation partner and/or help desk. Of course, if you have internal expertise, then all the better.
- Boundaries/roles: Sometimes customers are not clear on the role of the integrator and assume that endpoint customization is done by Jitterbit; if that topic arises, make the boundaries clear.
- Availability and quality of documentation: With the proliferation of cloud services and APIs, some vendors are simply listing their APIs but documentation can be scant. If this is your situation, you must build in time for discovery, feasibility, and testing.
-
Integration Scenarios
- Method and endpoint objects: Define these for each scenario. Examples:
- "Periodically query for new customers in Endpoint X into account in Endpoint Y on a batch basis, and update the new account number to Customer."
- "Receive a real-time request from Endpoint X that contains order information to send to Endpoint Y create order method, respond with new order number."
- "Query Database Table X and update 200,000 stock balance values to Endpoint Y Inventory API."
- Potential blockers: The scenarios are used for the time estimate. Expect that the development of each scenario (unless extremely simple) will encounter blockers. These can range from technical (bad credentials, inaccessible endpoint, opaque API) to procedural (business needs to define a new process, customization is required, SMEs are unavailable).
- Method and endpoint objects: Define these for each scenario. Examples:
-
Timeframe
- Important dates: Typically a customer knows their go-live, but there are other important dates.
-
User Acceptance Testing (UAT) dates: When does UAT start? (This may take explaining if the customer is not used to phased development.)
-
Endpoint readiness: If using new endpoints, when will the environments be ready for integration development and testing?
-
SME availability: Are there any constraints on SME availability?
Caution
Be careful when trying to accelerate an integration project. Adding more developers does not make development happen faster unless there are very clear and separate scenarios.
-
-
Resources
-
Approaches: Customers have varying approaches to project resources:
-
Mostly outsource: The customer provides a business point of contact or SME, and handles requirements, escalation, UAT, and external resource coordination. All other resources (primarily development) are provided by Jitterbit Professional Services and/or the Jitterbit Partner.
-
Mostly insource: The customer will learn to use Jitterbit iPaaS and just wants access to a Jitterbit SME for guidance and best practices.
-
In/outsource: The customer wants Jitterbit Professional Services or the Jitterbit Partner to build a number of integrations and gradually hand them off to customer resources. This part is difficult to estimate. The recommended approach is to estimate all the work, then subtract a percentage of hours.
Note
The customer may not realize that they will be spending a great deal of time on the project regardless, and that shifting the development from external to internal will not have a great impact (since the majority of it is limited to a single phase), and may even slow down progress because of knowledge-transfer (KT).
-
-
Level of involvement: This diagram illustrates the relative level of involvement of the project manager (PM), customer resources, and development resources. Note that development resources are most involved during the development phase, with their involvement tailing off afterwards. Customer resources (usually business users) are very involved during the UAT (User Acceptance Testing) phase, something that is commonly overlooked.
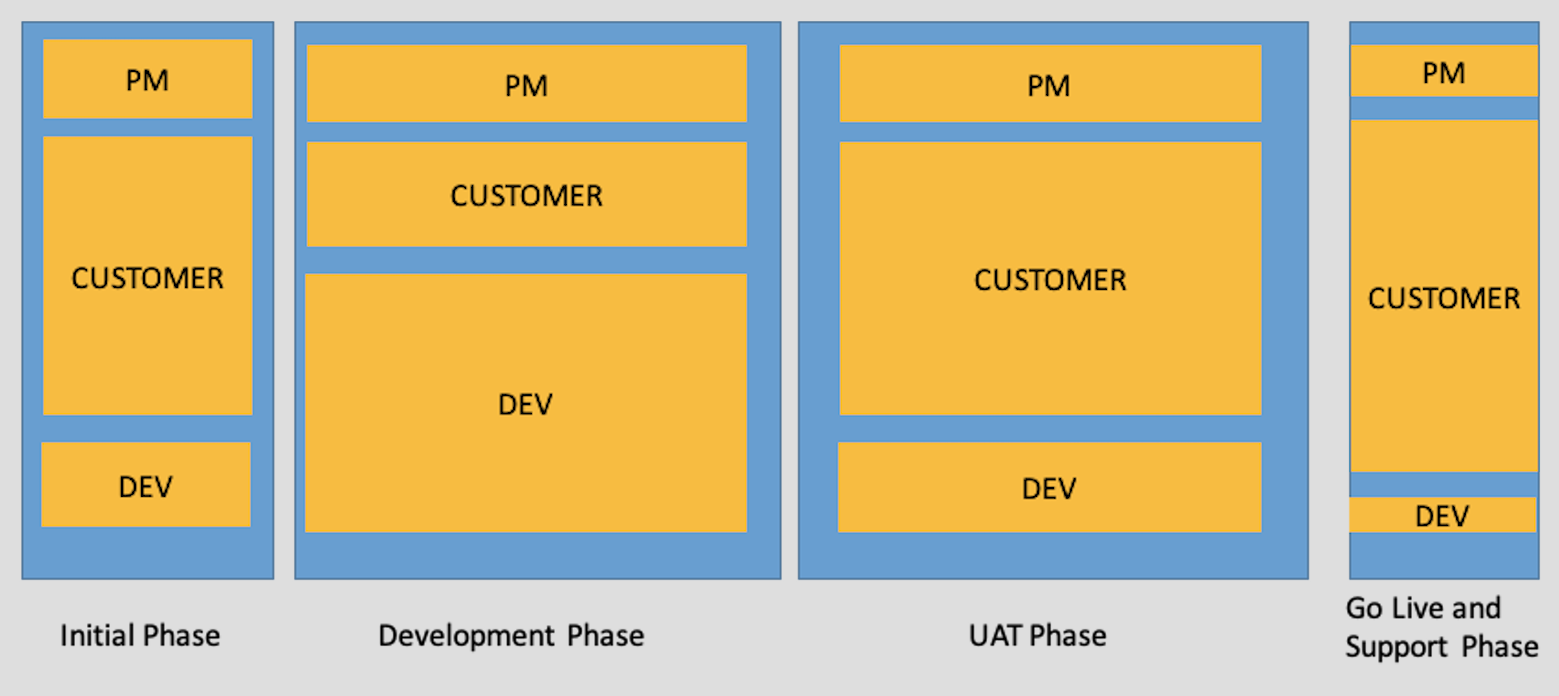
-
Staffing
These general guidelines are for staffing of resources with Jitterbit technical and PM skills. They exclude resources such as client business process SMEs and endpoint owners. Based on the size of the project, these staffing levels are recommended:
-
Small projects: Projects with 2 endpoints and fewer than 12 scenarios can be handled by a single part-time Jitterbit-skilled technical resource and a part-time project manager.
-
Medium projects: Projects with 2-4 endpoints and 12-20 scenarios can have the same staffing level as small projects, with a more involved staff.
-
Large projects: Projects with 5+ endpoints and 20+ scenarios have a lot of dependencies when determining staffing.
The PM role may be near 100% involvement over the course of the project if any of these statements are true:
-
The customer requires detailed status reporting (such as reporting to a project management office).
-
Numerous external SMEs have to configure the customer's endpoints to enable integration.
-
The customer is likely to struggle with getting detailed integration requirements.
-
The PM is inexperienced or absent, and the customer expects you to manage the entire project.
Exercise strict scope and change management in these situations! Make it clear to the customer that the success of the project is dependent on the customer clearing any blockers and on all project resources meeting the deadlines.
When using multiple development resources, make these considerations:
-
Having more than one developer in a single Jitterbit project requires a high degree of coordination (more work for the PM) since it is easy to deploy changes and overwrite someone else's work.
-
Strive to assign the developers to different integration scenarios, or break the work into different Jitterbit projects.
-
Use cross-developer design and code reviews.
-
If possible, ramp up resources during the development phase, and then ramp down during UAT and go-live phases.
Kickoff meeting
The purpose of the kickoff meeting is to bring together the key participants in the project, typically the key business user(s), SMEs, endpoint owners, and integration architects. This time is used for everyone to get on the same page and to clarify the roles and responsibilities. During the kickoff meeting, these tasks should be completed:
- Key dates: Review all key dates (not just the go-live date).
- Information sharing: Share contact information and documents.
- Integration scenario review: Review the integration scenarios from scoping.
- This is a good time to confirm if anything has changed from the last scoping session.
- If necessary, set up a detailed scoping review meeting.
- Roles and responsibilities: Building integration with Jitterbit is very fast, but keep in mind that the single biggest factor delaying an integration project are the non-technical dependencies. This is a good time to emphasize that point. Clarify the responsibilities for each role:
- PM
- Works with the customer and technical team to obtain and organize detailed integration requirements, including field-level mappings. Field-level mappings are needed by both the Jitterbit development resource(s) and the endpoint SMEs.
- Organizes the availability of business and endpoint SMEs to the project and promptly addresses open items for the integration, such as who is who, their level of project commitment, calendars, etc.
- Communicates to the customer and technical team the integration development progress and the open items to be resolved.
- Jitterbit Developer
- Achieves an understanding of the requirements to design the integration architecture, and works with the customer on design considerations (batch/real-time, APIs, master-data management, security requirements, etc.).
- Takes the detailed requirements and uses the tool to develop the operation scenarios, following Jitterbit best practices.
- Quickly surfaces any blockers, and takes the initiative in getting them solved.
- Ideally, the Jitterbit developer is in direct communication with the customer. Isolating the Jitterbit developer from SMEs and customers is a bad practice and leads to communication breakdowns and delay. The project resources must be a team and must communicate fluidly.
- Endpoint SME
- Provides deep expertise about the exposed interfaces.
- Understands the integration requirements, and if there are potential issues — such as needing a change in an endpoint or if a requirement is infeasible — proactively alerts the team.
- Is highly available to assist with unit testing. This can include providing test data, providing prompt feedback on the results of integration testing, and interpreting error responses.
- PM
- Licensing and entitlements: Review Jitterbit licensing and entitlements and the process for requesting entitlements.
- Harmony architecture: Consider these points regarding the Harmony architecture:
- If private agents are used, prioritize the installation of the technical architecture and connectivity to the endpoints, primarily for development.
- If working with on-premises systems, there are many steps that can take time to finish, such as hardware acquisition, private agent installation, network connectivity, integration user credentials, and the testing cycle. Since this can involve multiple groups, get this started as soon as possible for the development environment.
- Expect that lessons learned in setting up the development environment will accelerate non-development environment setup, so get this step out of the way as soon as reasonable.
- Harmony memberships: Make sure that the development resources are added to the Harmony organization with an Admin permission (see Jitterbit organizations).
- API Manager APIs: If APIs are used, review dependencies. Check the API default URL. If the customer started using a trial, it is possible that the default URL still includes the word "trial." Escalate to Jitterbit licensing to have that removed before building any APIs.
- Future meetings: Set the future meeting cadence.
- If integration is part of an endpoint implementation, then join those meetings.
- Otherwise, short, frequent meetings (daily is not uncommon) are preferred. An instant messaging platform, such as Slack, can also be set up.
Integration project plan
As mentioned before, integration has many dependencies. Project plans tend to come in two types:
- Part of the implementation of a new endpoint, such as an ERP.
- Standalone, where the endpoints are relatively stable.
In the first case, the integration project tasks can (and will need to) be interleaved with the overall project. For example, integration development will have to wait on the endpoint objects being configured.
In the second (standalone) case, a project plan just for building the integration can be set up.
Regardless of the integration tasks being part of another plan or standalone, the tasks are the same. Here's an example from a standalone project plan:

Note that the project plan starts with the basic building blocks, then iterates through each scenario. The UAT (User Acceptance Testing) section can be postponed until after all the scenarios have reached a point of readiness.
Requirements gathering and development
This section starts by covering the general approach for requirements gathering and development, then dives into the details of mapping, development, managing the development process, reuse, and logging and error handling.
General approach
Jitterbit's low-code and graphical development front-end (Studio) lends itself to an iterative model. This approach is not waterfall, where all the requirements are documented before development begins. These key steps describe the general iterative model:
-
Start with the master data scenarios. Since the approach is to iterate quickly through a define-build-test cycle, we need to have the endpoints populated with master data before working with transactional data.
-
Understand which systems are SOR (Systems of Record) and which are SOE (Systems of Engagement):
- SOR (Systems of Record): The authoritative source for master data, usually an ERP.
- SOE (Systems of Engagement): The customer- or salesperson-facing system, such as a system for buying a product.
-
Understand the key data fields and which are shared (external or foreign keys).
- Typically the SOR's master data keys are stored in the SOE to facilitate updates back to the SOR. For example, if SAP is the SOR and SFDC is the SOE, then SAP customer numbers are stored as external IDs in SFDC.
- Since shared keys can require customization (which can become a time blocker), it is important to get this area handled up front.
This diagram shows an example using Salesforce as the SOE (System of Engagement) and SAP as the SOR (System of Record), in a uni-directional master data flow with a write-back.
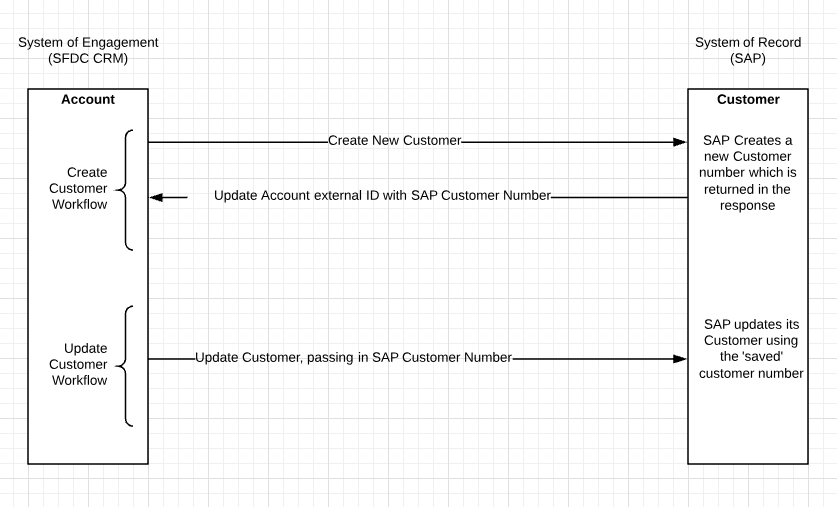
If dealing with bi-directional master data updates, recognize that this can be a complicated integration:
- You can encounter race conditions, logic to exclude updates from the integration user separate from business users, and mutual shared keys.
- Frequently, the business rules for master data are not the same in the endpoints, and either the integration layer has to accommodate them, or the endpoints need to be customized. This can be a blocker, so work through the scenarios in detail for these types of integrations.
Mapping
The PM should have the customer start working on the detailed field-level mappings. These are needed by both the Jitterbit development resource(s) and the endpoint SMEs.
The customer may be used to looking at the systems from the point of view of the user interface and may not be able to produce mappings based on the point of view of the schemas. In that case, get the schemas into the mapping spreadsheet, if possible. This may require the help from the SME, online documentation, or the use of Jitterbit iPaaS to connect to the endpoint and pull out the schemas.
If the mapping is straightforward, you can do the mapping "live" by using Jitterbit iPaaS to pull in the endpoint schemas into a transformation during a customer meeting.
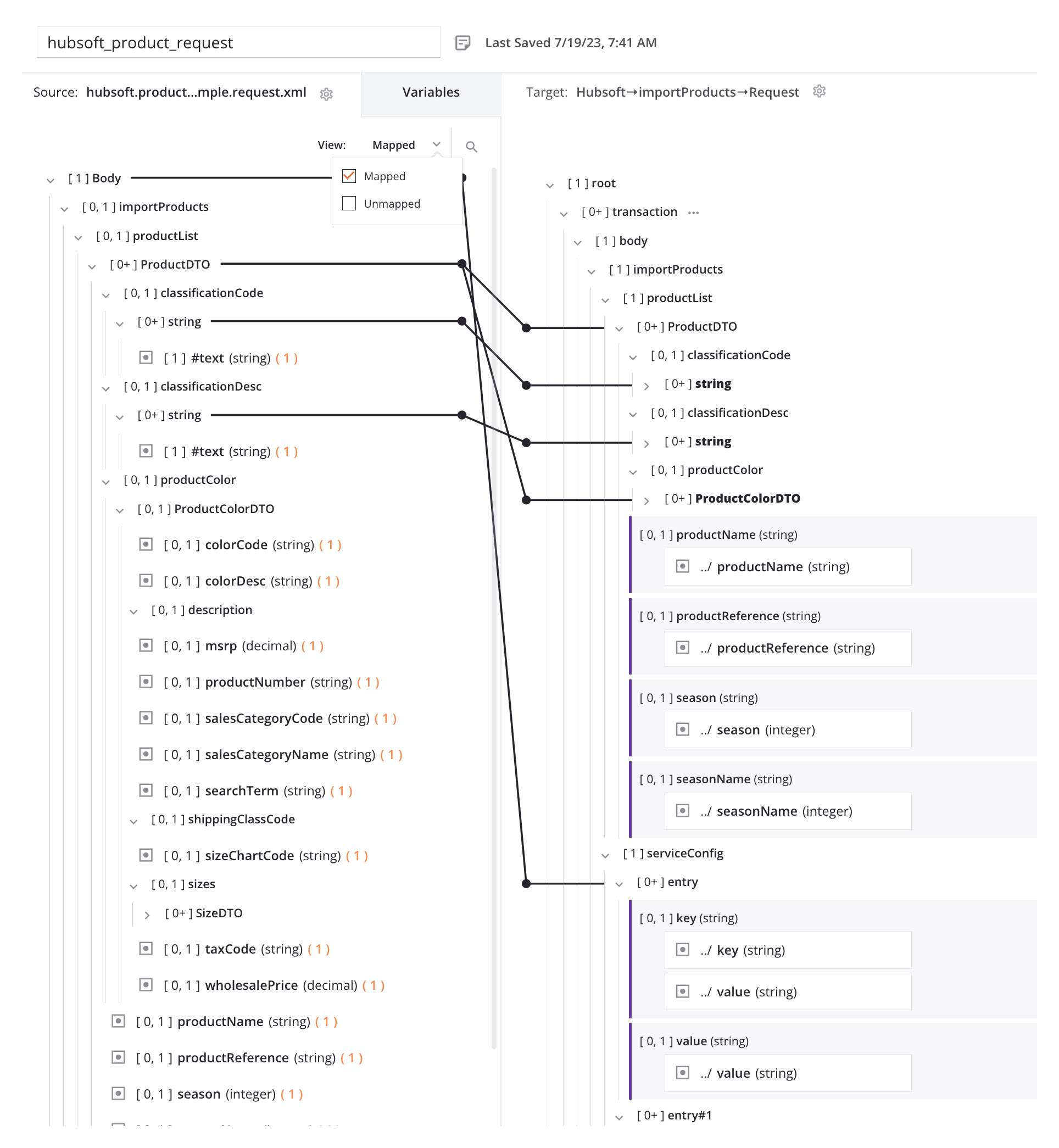
This spreadsheet demonstrates an example of field-level mappings:
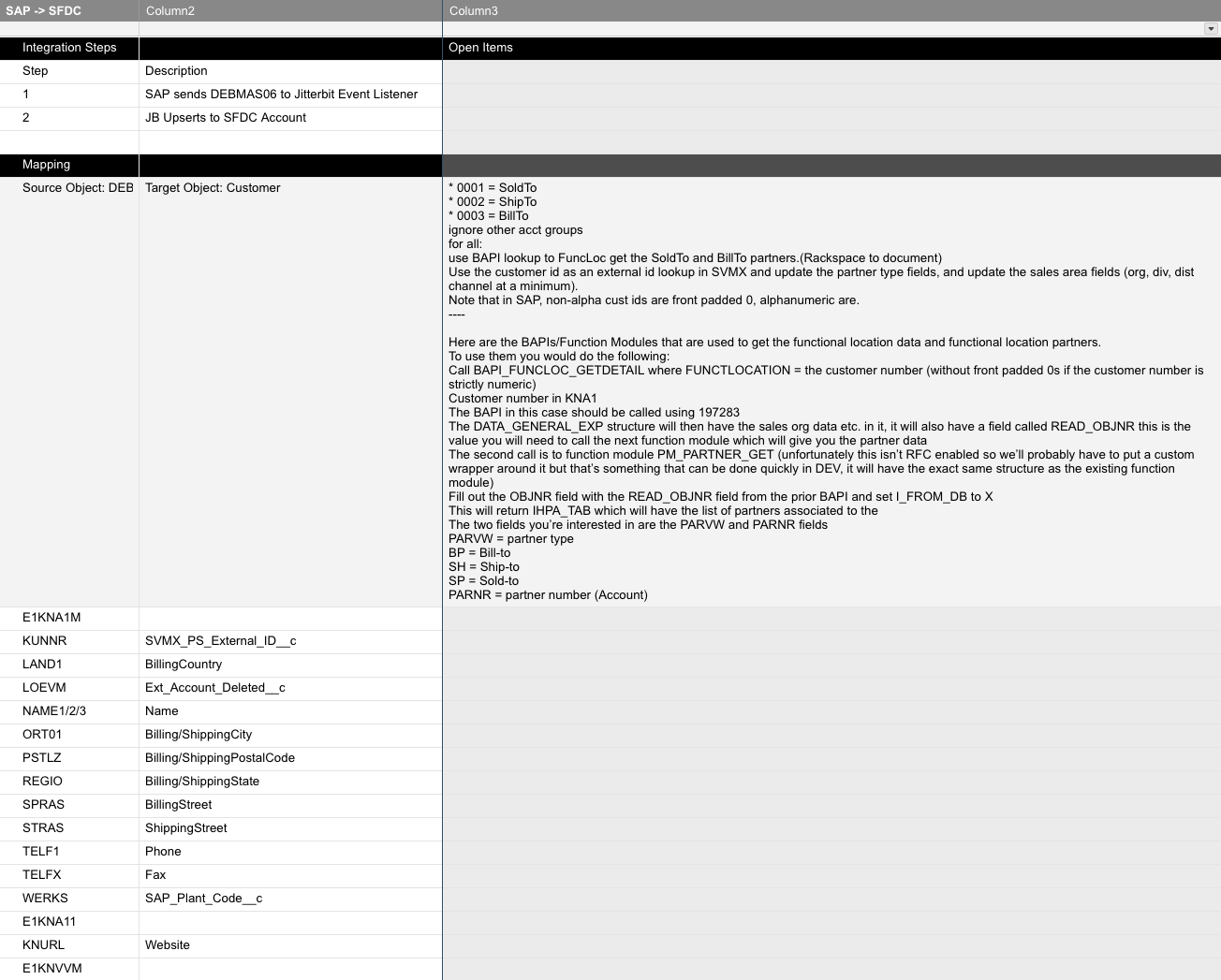
When there is enough scenario definition to get started, aim to build the integration in Jitterbit iPaaS and test as soon as possible to identify any blockers.
As the customer works through the mapping spreadsheet, pay close attention to which mappings will be more difficult. The transformation is where the rubber meets the road, meaning this is where we map the exposed integration methods between systems. It is important to find out which scenarios will be harder than others, since there is a high time multiplier for those. Easy mappings can take only minutes, while complex mappings can take days, so look for these situations and prioritize:
-
External system lookups: For some systems, you may need to look up values by executing queries. The danger here is performance impact: be aware that the transformation executes on a per-record basis. If processing 200 records, and the transformation is doing a lookup on each record, that is 200 queries. This is not a big deal if the target is a database, but if the target is an API, that can also be 200 logins/logouts. Consider using a dictionary to query the data in a pre-operation script, thereby doing a single query.
-
Complex schemas: The transformation is "iteration-based." For example, if the source and target schemas are flat (such as a customer name and home address), then the transformation will iterate one time per record, like this:

In the next example (below), both the source and target schemas are complex, and the transformation has to repeatedly process the child sections. To make things more complicated, it may have to process the child sections conditionally:
Frequently, to make quick progress on complex mappings, the endpoint SMEs have to be brought together to hammer out the requirements, which may even require business input and may lead to endpoint customization, all of which can delay the overall project. It is vitally important to identify complex integration requirements as soon as possible and clear up dependencies quickly to keep the project moving ahead.
Development
As mentioned before, the development work can start shortly after kickoff:
- Get the endpoints connected.
- Identify and implement easy scenarios, particularly if master data.
- For complex integrations, even if not completely mapped, take steps to get the exposed integration methods into a transformation.
- Schemas (usually) apply only when dealing with databases and web services.
- When dealing with files, they can have a hierarchical format, which have to be built manually in Jitterbit. This can be laborious, so get that moving early.
- For database endpoints, it will be more efficient to build views than to have the integration project join tables. A stored procedure can be a better approach than performing complex updates.
- When working with endpoint connectors, use the Jitterbit iPaaS wizards and be sure that all the objects in scope are available. This is a good way to validate that the integration user has all the permissions it needs to work.
- The developer should look over the source and target schemas in order to ask "intelligent" mapping questions, such as these:
- "Do we have all the mandatory fields?"
- "If we pass a record ID, will the endpoint automatically update a record or will it try to create it?"
- "How many records can be passed in one call?"
- "This SAP IDoc schema uses German abbreviations. Anyone Sprechen Sie Deutsch?"
- Don't overlook reviewing the response schema (if a web service), particularly as to how errors are handled. Some schemas indicate success or failure overall, while others provide codes that need to be evaluated.
Managing the development process
A good approach to managing the development process is to take the scenarios captured during scoping and track milestones related to each scenario. This is an example spreadsheet used to track key milestones in an integration development:
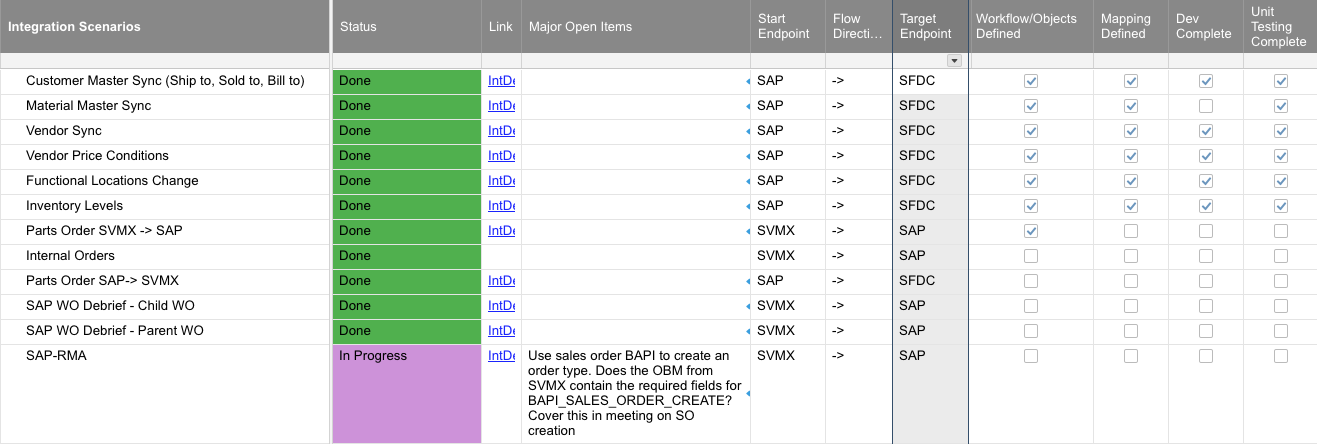
Treat each scenario as a mini-development iteration, starting with data dependencies (such as master data). Then build operations, build transformations, fetch some test data, push to an endpoint, handle the response. Don't go for perfection. Aim for moving simple test data from point A to point B and then move on to the next scenario. Then, iterate the integration scenario development, surfacing blockers until the main success scenario as well as error scenarios have been developed and unit tested.
The first set of integrations will be the ones that run into the most problems, such as connectivity, permissions, missing fields, etc. So the faster we get to this point and clear the blockers, the better. We're not looking for perfection right off the bat.
Start with a small set of test data. This can be hard-coded in scripts or use a query that is limited to just a few records.
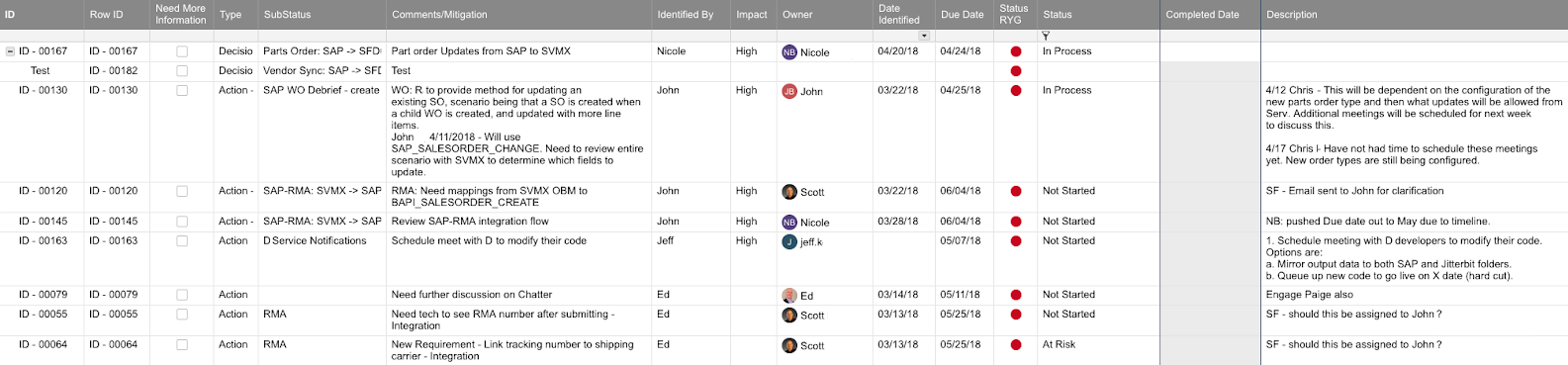
If there is a minor blocker, document it, assign the resolution to the right person, and go on to another scenario. Again, the point is to rapidly find the landmines so that they can be cleared, and that responsibility is usually the customer's and/or the SME's responsibility.
Here is an example of an issue tracking spreadsheet:
Reuse
Like any other software development platform, development can be accelerated if you don't reinvent the wheel. Jitterbit iPaaS has several ways of enabling this:
- Scripts
- Entire custom functions can be built and called from many operations. The general rule of thumb is that if you have to write the same script twice, make it a callable script.
- Source and Targets
- Pass in global and/or project variables instead of hard-coding things such as file paths or FTP hosts.
- Use a global variable as an intermediate work space instead of operation-specific sources and targets.
- Operations
- Single task operations can be built once and used many times, particularly ones dealing with error handling and logging.
- Operations in one project can be called from another. Be aware that the logs will appear in the native (called) projects. But since the scope of global variables is the operation chain (which can be called from more than one project), it is possible to get the results of the remote operation and log it in the calling project.
Logging and error handling
A frequently overlooked set of requirements has to do with logging and error handling. The customer may not have specific requirements, especially if this is their first integration project, so the customer will need help with best practices in this area. The key points are these:
- Jitterbit iPaaS does operation logging out-of-the-box.
- It is easy to log additional data, which is very useful for troubleshooting.
- Here is where it may dawn on the customer that their integration scenarios will require internal support.
- When a problem is identified in an endpoint, if a possible root cause is the integration, then a resource will need to inspect the logs. The clearer and more informative the logs, the faster the troubleshooting process.
- There are two broad classes of alerting: data-related alerts and technical failure alerts, which may or may not need to go to the same group. Technical failure is an easy configuration, but data-related logging is all custom, and is easier to include during the integration development instead of being added in later.
- Studio can use email quite easily, where the email service is treated like an endpoint to the customer's email service, using Studio email notifications. While this is generally easy to set up, this step should not be left for last.
- The Jitterbit Management Console can be used to configure additional organization-related notifications.
For detailed information, see the Error handling best practices tech talk and the Alerts page.
Business rule handling
The big debate: to include — or to not include — business rules.
Many customers start out thinking "I don't want to include business rules in the middleware; I want to keep things simple," but then provide the exact opposite requirements!
The ideal middleware architecture has it that the integration layer should be as lean as possible, focusing on its strengths: data transformation, scenario processing and orchestration, endpoint connection, and logging and alerting. Adding cumbersome business rules will only mar the perfection of this architecture by spreading the business rule support across the endpoint boundaries. That is, if a business rule changes, it not only changes in the application; it changes in the middleware too. Moreover, because middleware is muddy, murky, and mystical, rule maintenance is mind-numbing.
Reality rudely intrudes, as Jitterbit iPaaS has to work with what applications expose:
- The data is presented poorly, and the only way to process it is to apply business rules ("if value = a, department = sales, if b, department = ops, if c, department = support").
- The source data is incomplete ("if country = US, fiscal year is calendar, if country = UK, fiscal year is April - March")
- The integration scenario is data-driven ("if work order contains lines using third party, process that line as an AP entry, otherwise update as a service order")
Yes, all of the above could be handled by the endpoint. But this assumes that the customer has the resources and time to customize the endpoint or change an API. If all that is available, then by all means do that. However, the usual case is that the endpoints are harder to change and maintain than the integration project.
When business rules must be handled, the best practices are these:
- Externalize where possible. For example, have data in a table where it can be maintained by a user.
- Use project variables. These are exposed in the Jitterbit Management Console along with specific documentation. The main use case is for environment-specific endpoint credentials, but these can also be used to drive orchestration logic and query conditions.
- Add detailed custom logging and data error handling, so if and when the business rules change, the effect on the integration will be obvious.
Agents and environments
The Jitterbit agent is the integration workhorse. Studio does not actually run any operation processes. Everything happens on a Jitterbit agent. A key early decision is what kind of agent to use: either private or cloud (see Jitterbit agents).
If any of these is true, then the project must be run on a private agent:
- An endpoint is behind the customer's firewall. This can be an application or a network share.
- A connector or driver is required that is not available in the cloud agents. For example, the Excel driver is available only on private agents.
- The customer's security requirements as such that no data is allowed outside their firewall.
Otherwise, cloud agents are an option. From a project timeline perspective, this is ideal, since this avoids all the steps related to a customer having to procure server hardware and install the Jitterbit agent software. However, regardless of whether you use cloud or private agents, you still have to set up members and environments.
Depending on the license level, a customer will have two or more private agent licenses. Also, the customer will be entitled to a number of environments, which are typically set up following the standard software development lifecycle categories (development, quality, staging, production, support, etc.). Jitterbit's migration tool works with environments to enable promotion of integration projects.
Regarding agents and environments, note these important points:
-
Identifying an environment as "production" does not confer anything special. It does not run any faster or is any more resilient. One environment is pretty much like any other.
-
A Harmony environment can be used in many ways. If the customer is providing integration for third parties, an environment can be used as a container for dedicated company projects.
-
A single private agent can run more than one environment.
-
A frequent question is if any network firewall rules need to be changed. Usually the answer is "no," unless the customer is restricting outbound HTTP traffic from servers and/or ports. The Harmony-to-agent communication is all outbound from the agent to Harmony.
An agent group is a mandatory part of the agent architecture. Aside from being the virtual container that holds the private agents, it plays another important role. Unlike traditional server management tools that require additional applications such as load balancers, Harmony makes it easy to achieve server resiliency through load-balancing and fail-over. Simply by adding an agent to a group, the agent automatically becomes part of a server cluster.
To be clear, when running an operation on an agent group with multiple agents, only one agent is running that operation. The operation is not broken up and run across all the agents in the group. Adding agents to a group will not (usually) make the operations run any faster. The exception is a design that calls for a group of agents to service high-traffic inbound APIs, in which case spreading the load across multiple agents is a good idea.
To begin development, all that is needed is a single private agent and a single environment. Additional agents can be added to groups, and new environments can be added as the project progresses (all within license limits, of course).
If procuring even a single agent is problematic, a Jitterbit private agent can be run on a workstation. The best way to do this is to use the Docker agent to avoid desktop conflicts.
Batch and event-driven processing
For each integration scenario, you determine the operation trigger: batch processing (scheduled) or event-driven processing (real-time).
Batch processing
Batch processing collects and processes data at scheduled intervals (hourly, daily, etc.) To implement this approach, you can configure the following elements:
-
Schedule configuration: Define when operations run using operation schedules. For information on configuring and deploying scheduled operations, see Operation schedules and Deploy and execute an operation.
Note
For transferred projects, you must manage schedule activation and deactivation (either at the operation level or schedule level) across environments.
-
Change tracking: Implement scripting logic to identify modified records since the last run. For example, you can implement timestamp-based queries (using fields like
last_modified_date).Tip
When querying for changed records, exclude records modified by the integration user account to prevent circular updates.
Batch processing is beneficial when source systems don't support real-time triggers, or you need to process large data volumes during low-traffic periods.
For operations processing large data volumes, consider using chunking to break datasets into smaller batches. For information on configuration details, see Enable Chunking.
Tip
Avoid running batch operations at very short intervals (for example, every minute). This approach creates excessive system load and difficult-to-analyze logs, while most cycles process no new data. If business requirements demand minimal latency, implement event-driven processing instead.
Event-driven processing
Event-driven processing triggers operations immediately when events occur in source systems. This typically happens through API calls or webhooks. This approach provides the following benefits:
- Eliminates schedule management and timestamp tracking.
- Processes data as it becomes available.
- Reduces operational complexity.
- Places trigger responsibility on the source system.
Event-driven processing can be implemented using one of these methods:
-
API Manager APIs: Source systems call API Manager APIs when events occur, which triggers immediate processing. For information on deploying and executing API-triggered operations, see Use an API trigger.
-
Listening service: The listening service runs on private agents and can trigger operations when events occur on specific endpoints. This service supports certain connectors and activities, and provides load balancing across agent clusters. For more information on deploying listener-triggered operations, see Use a listener.
Tip
For high-volume scenarios such as bulk operations, consider queueing mechanisms (such as Jitterbit Message Queue) to temporarily store incoming API data and prevent target system overload.
Project transfer
Depending on the customer's process, the project will need to be transferred to a QA environment before UAT, or testing is done in a development environment and the project is then transferred to a production environment.
-
If possible, do not transfer into the next higher environment until the project is nearly complete. Once a migration happens, you then need to remember to transfer them to other environments.
-
Avoid making changes in a "higher" environment to quickly solve a problem, thinking that you will sync up the environments later. Instead, make the fix in the "lower" environment and transfer it. There is no fool-proof way to identify granular differences between projects, so it is easy to lose track of changes.
User acceptance testing (UAT)
All the scenarios are built, all the unit tests are successful, and users are lined up to test the integration. Time to turn users loose on the integration, and now you'll find out what the real requirements are!
This phase can be a smooth process, or very intense. It really depends on the quality of the previous steps. Keep these tips in mind during the UAT phase:
-
Be prepared to react quickly as issues come up. If you've done your job well, most of the problems will be data-related, not technical. So be sure that the endpoint SMEs are available to triage problems.
-
Where possible, have the user take the lead in troubleshooting: reacting to alerts, reading logs, tracing the integration logic. Ideally, the person who will be doing this job in production will do it during this phase.
-
Keep close track of the issues that come up during UAT and how they are solved. A frequent situation is that problems affect endpoint data, and while the integration problem is fixed, the data is not and becomes a recurring issue with testing.
-
Plan on frequent meetings with all concerned to resolve any blockers.
-
As time permits, start documentation.
-
Develop your cut-over plan.
-
In the production environment, perform connection tests and any other testing you can get away with or that are allowed.
Post-production and monitoring
UAT done! User sign-off done! It's time to light this rocket!
In this stage, the final migration to production should be complete. If you are using schedules, be aware that you can transfer them to production and turn them off in the Jitterbit Management Console. It can then be up to the customer to turn the schedules on.
Expect to meet with the customer periodically to make sure things are going smoothly, anticipating a few questions.
Plan for a "wrap-up" meeting to deliver the project documentation and perform any final knowledge transfer.