Metodología de proyecto de integración para Jitterbit Design Studio
Introducción
Enfrentémoslo: los proyectos de integración pueden ser difíciles, con muchas posibles trampas. Si la integración es "datos en movimiento", hay momentos en que los datos no están interesados en moverse. Los proyectos de integración dependen en gran medida de los puntos finales y, por lo tanto, pueden tener riesgos que están fuera del control del integrador.
En un mundo ideal, los puntos finales son estables, tienen APIs bien documentadas y respuestas de error claras. Hay expertos en la materia (SMEs) disponibles, y hay entornos no productivos disponibles tanto para desarrollo como para pruebas. Además, el proyecto está bien financiado, es una prioridad absoluta para la dirección y hay tiempo adecuado para las pruebas. Si esto suena como tu proyecto, ¡felicitaciones! Para el resto de nosotros, sigamos leyendo.
Enfoque
Cuando sabes que hay un campo lleno de trampas, tienes dos opciones:
-
Moverte con mucho cuidado y deliberación, inspeccionar todo el paisaje hasta el más mínimo detalle y construir solo cuando todo esté claro.
-
Ponerte en marcha lo antes posible, identificar cualquier trampa temprano y celebrar las detonaciones… porque descubrir problemas temprano es muy superior a descubrirlos más tarde.
Bien, entonces la opción 2 es. Abróchate el cinturón, vamos a movernos rápido.
Audiencia
La audiencia objetivo es un gerente de proyecto (PM) o líder técnico que tiene experiencia general en TI y ahora está liderando un proyecto de integración utilizando Jitterbit iPaaS.
Esto incluye a aquellos con roles como un socio de Jitterbit que realiza trabajos de integración general, un proveedor de aplicaciones que también asume la tarea de construir las integraciones de tu producto a todos los puntos finales del cliente, o un PM del cliente, implementando Jitterbit iPaaS solo o con ayuda de los Servicios Profesionales de Jitterbit.
Enfoque
El enfoque de este documento no es cómo usar Jitterbit técnicamente (consulta la otra documentación para los detalles técnicos) sino que aborda los elementos clave que un PM para un proyecto de integración debe conocer. Esta guía muestra cómo organizar tu equipo, recopilar y validar requisitos de manera clara y concisa, y aprovechar las fortalezas de Jitterbit iPaaS para entregar un proyecto exitoso.
Alcance
El alcance es un proceso de dos partes que implica recopilar información, delinear los límites del proyecto y obtener la información básica necesaria para implementar el proyecto:
- Orden de Magnitud Aproximado: Estimar un Orden de Magnitud Aproximado (ROM) de alto nivel para el trabajo (se puede omitir para ciertos puntos finales).
- Alcance del Trabajo: Refinar la estimación detallando un Alcance del Trabajo (SOW) para la entrega del proyecto.
Este proceso es sensible al concepto de GIGO — Basura entra, basura sale — así que no lo subestimes. La hoja de cálculo a continuación se utiliza como punto de partida para el proceso de alcance. La terminología específica utilizada en esta hoja de cálculo se definirá más adelante en las subsecciones de Orden de magnitud aproximado y Alcance del trabajo.
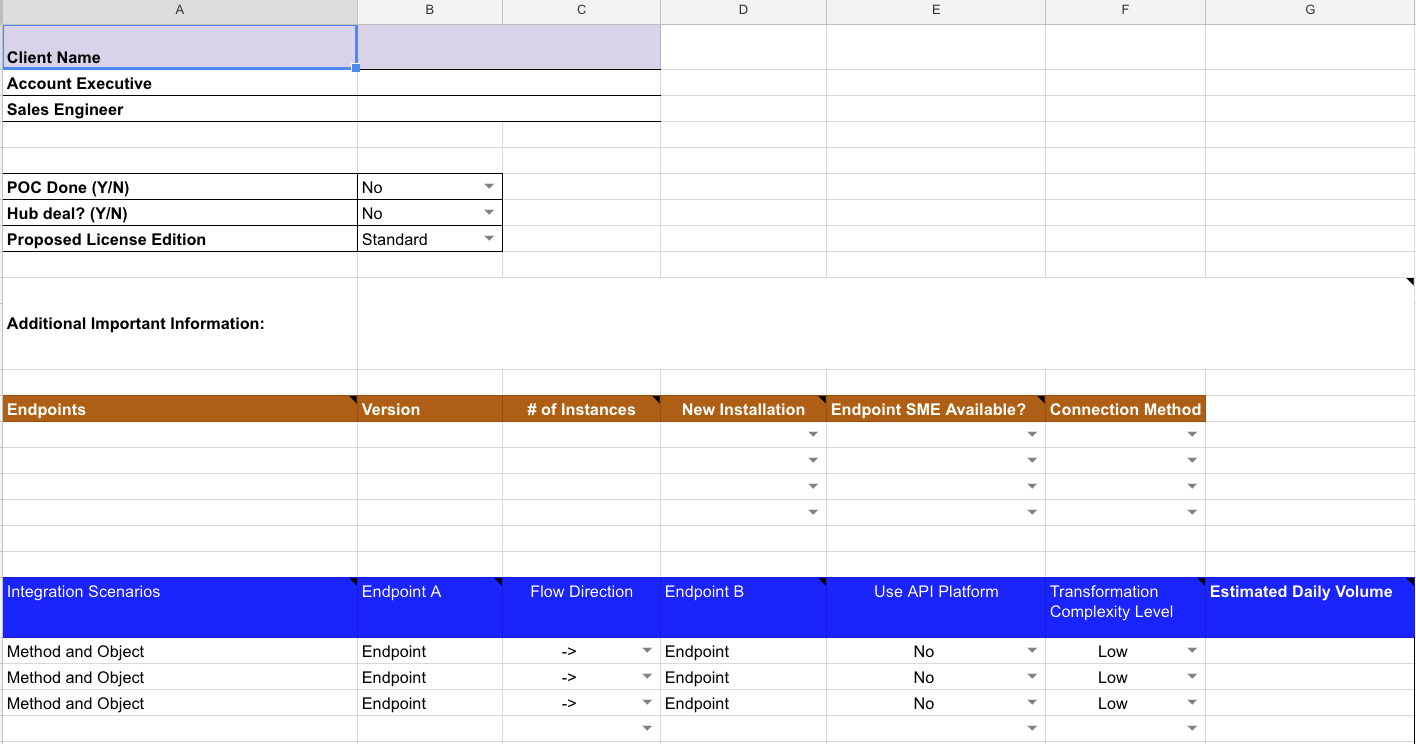
Orden de magnitud aproximado (ROM)
Al entrar en este paso, se presume que ha habido suficiente análisis por parte del cliente para determinar qué interfaces necesitan ser construidas. A un alto nivel, se necesitan interfaces cuando un proceso de negocio cruza los límites de las aplicaciones. Si los procesos de negocio no son firmes, entonces tampoco lo es la integración, y puede ser demasiado pronto para estimar.
El Orden de Magnitud Aproximado (ROM) está diseñado para mantenerse a un alto nivel y facilitar una rápida respuesta para apoyar la planificación y la toma de decisiones del cliente. Las estimaciones de ROM se basan en estos elementos:
- Puntos finales: Este es el "elemento" con el que Jitterbit iPaaS interactuará para leer/escribir datos. Esto puede ser una aplicación con un conjunto de métodos remotos, un sistema basado en archivos como FTP o sistemas de archivos internos, una base de datos o una aplicación web que expone APIs.
- Escenario de Integración: Esta es la descripción del movimiento de datos necesario para lograr el objetivo de integración. "Sincronizar Cuentas", "Crear Órdenes de Compra" o "Obtener Información de Envío" son ejemplos.
- Objeto: Este puede ser un objeto SFDC (Salesforce) (como cuenta o producto), una tabla de base de datos o un objeto de negocio virtual, como órdenes de compra en un documento EDI.
- Método: Esto es lo que se está haciendo con los datos, como CRUD (crear, leer, actualizar y eliminar).
- Nivel de Complejidad de Transformación: Este puede ser uno de estos niveles:
- Bajo: Utiliza conectores de puntos finales, un bajo número de transformaciones y una o dos operaciones en el escenario.
- Medio: Puede o no utilizar conectores de puntos finales, utiliza un número de transformaciones y búsquedas externas, y utiliza varias operaciones por escenario.
- Alto: Sin conectores de puntos finales, numerosos pasos en el escenario, y se sabe que el punto final es desafiante.
Las heurísticas se utilizan para generar horas. Se emplean fórmulas basadas en el número de escenarios y la complejidad para llegar a una estimación, que puede estar fácilmente desviada hasta en un 15–20%. Piensa en esto como un número de presupuesto que se utilizará al principio del proceso.
La estimación ROM asume que un experto en Jitterbit iPaaS está realizando el trabajo con una ligera gestión de proyectos. También es de extremo a extremo: desde la iniciación hasta el post-lanzamiento. El tiempo para construir una integración no corresponde uno a uno con el tiempo transcurrido. El tiempo real dependerá de los niveles de personal, la estabilidad de los puntos finales del cliente, la disponibilidad de los expertos en la materia del cliente, etc. Errando por el lado de la precaución, asumimos una relación de 3:1 entre la duración del calendario y las horas estimadas.
Alcance del trabajo (SOW)
El Alcance del Trabajo (SOW) está diseñado para proporcionar más detalles con el fin de obtener una imagen más clara del proyecto y para proporcionar un chequeo o recálculo de la estimación ROM. Para ciertos puntos finales (como SAP) o tipos de proyectos (como acuerdos de Hub), puedes omitir el proceso ROM y pasar directamente al paso del SOW.
Durante este paso, debes organizar una sesión de alcance para finalizar detalles y responder preguntas abiertas. Los asistentes ideales incluyen usuarios de negocio (y todos los propietarios de procesos) y expertos en la materia de los puntos finales. Incluir a estos últimos es clave, ya que de lo contrario puede ser difícil entrar en los detalles.
Esta es la mejor oportunidad para aclarar el perfil de riesgo del proyecto, así que escucha atentamente y haz preguntas. Cubre estos temas:
-
Puntos finales
-
Versiones: Versiones que se utilizarán o encontrarán.
-
En/on-premises: Si es en las instalaciones, asegúrate de cubrir el uso de agentes en la nube versus agentes privados. Una preocupación común es la seguridad de la red, como abrir el firewall para los agentes privados, así que asegura al cliente y a las partes interesadas que esto no es una preocupación de seguridad. Proporciona un enlace al documento técnico sobre seguridad y arquitectura de Jitterbit y a los requisitos del sistema del host para agentes privados.
-
Soporte: Cómo se soportan los endpoint(s) (internamente/externamente).
-
Etapas del ciclo de vida: En desarrollo/pre-producción, mantenimiento, en proceso de actualizaciones, descontinuación.
-
-
Experiencia en Endpoint
- Experiencia interna vs. externa: Si se trata de un endpoint complejo, como un ERP o CRM, generalmente hay experiencia interna en el departamento de TI, o un socio de implementación y/o mesa de ayuda. Por supuesto, si tienes experiencia interna, mucho mejor.
- Límites/roles: A veces los clientes no tienen claro el rol del integrador y asumen que la personalización del endpoint la realiza Jitterbit; si surge ese tema, aclara los límites.
- Disponibilidad y calidad de la documentación: Con la proliferación de servicios en la nube y APIs, algunos proveedores simplemente están listando sus APIs, pero la documentación puede ser escasa. Si esta es tu situación, debes incluir tiempo para descubrimiento, viabilidad y pruebas.
-
Escenarios de Integración
- Método y objetos de endpoint: Define estos para cada escenario. Ejemplos:
- "Consultar periódicamente nuevos clientes en el Endpoint X para la cuenta en el Endpoint Y de manera batch, y actualizar el nuevo número de cuenta al Cliente."
- "Recibir una solicitud en tiempo real del Endpoint X que contiene información del pedido para enviar al método de creación de pedido del Endpoint Y, responder con el nuevo número de pedido."
- "Consultar la Tabla de Base de Datos X y actualizar 200,000 valores de saldo de inventario al API de Inventario del Endpoint Y."
- Bloqueadores potenciales: Los escenarios se utilizan para la estimación de tiempo. Espera que el desarrollo de cada escenario (a menos que sea extremadamente simple) encuentre bloqueadores. Estos pueden variar desde técnicos (credenciales incorrectas, endpoint inaccesible, API opaca) hasta procedimentales (la empresa necesita definir un nuevo proceso, se requiere personalización, los expertos no están disponibles).
- Método y objetos de endpoint: Define estos para cada escenario. Ejemplos:
-
Plazo
- Fechas importantes: Típicamente un cliente conoce su fecha de lanzamiento, pero hay otras fechas importantes.
-
Fechas de Pruebas de Aceptación del Usuario (UAT): ¿Cuándo comienza UAT? (Esto puede requerir explicación si el cliente no está acostumbrado al desarrollo por fases.)
-
Preparación del endpoint: Si se utilizan nuevos endpoints, ¿cuándo estarán listos los entornos para el desarrollo y prueba de integración?
-
Disponibilidad de SME: ¿Existen restricciones en la disponibilidad de SME?
Caution
Tenga cuidado al intentar acelerar un proyecto de integración. Agregar más desarrolladores no hace que el desarrollo ocurra más rápido a menos que haya escenarios muy claros y separados.
-
-
Recursos
-
Enfoques: Los clientes tienen diferentes enfoques respecto a los recursos del proyecto:
-
Principalmente subcontratado: El cliente proporciona un punto de contacto comercial o SME, y maneja requisitos, escalamiento, UAT y coordinación de recursos externos. Todos los demás recursos (principalmente desarrollo) son proporcionados por Jitterbit Professional Services y/o el socio de Jitterbit.
-
Principalmente interno: El cliente aprenderá a usar Jitterbit iPaaS y solo quiere acceso a un SME de Jitterbit para orientación y mejores prácticas.
-
Mixto: El cliente desea que Jitterbit Professional Services o el socio de Jitterbit construyan varias integraciones y las entreguen gradualmente a los recursos del cliente. Esta parte es difícil de estimar. El enfoque recomendado es estimar todo el trabajo y luego restar un porcentaje de horas.
Note
El cliente puede no darse cuenta de que estará dedicando una gran cantidad de tiempo al proyecto de todos modos, y que trasladar el desarrollo de externo a interno no tendrá un gran impacto (ya que la mayor parte está limitada a una sola fase), e incluso puede ralentizar el progreso debido a la transferencia de conocimiento (KT).
-
-
Nivel de participación: Este diagrama ilustra el nivel relativo de participación del gerente de proyecto (PM), los recursos del cliente y los recursos de desarrollo. Tenga en cuenta que los recursos de desarrollo están más involucrados durante la fase de desarrollo, con su participación disminuyendo después. Los recursos del cliente (generalmente usuarios comerciales) están muy involucrados durante la fase de UAT (Pruebas de Aceptación del Usuario), algo que comúnmente se pasa por alto.
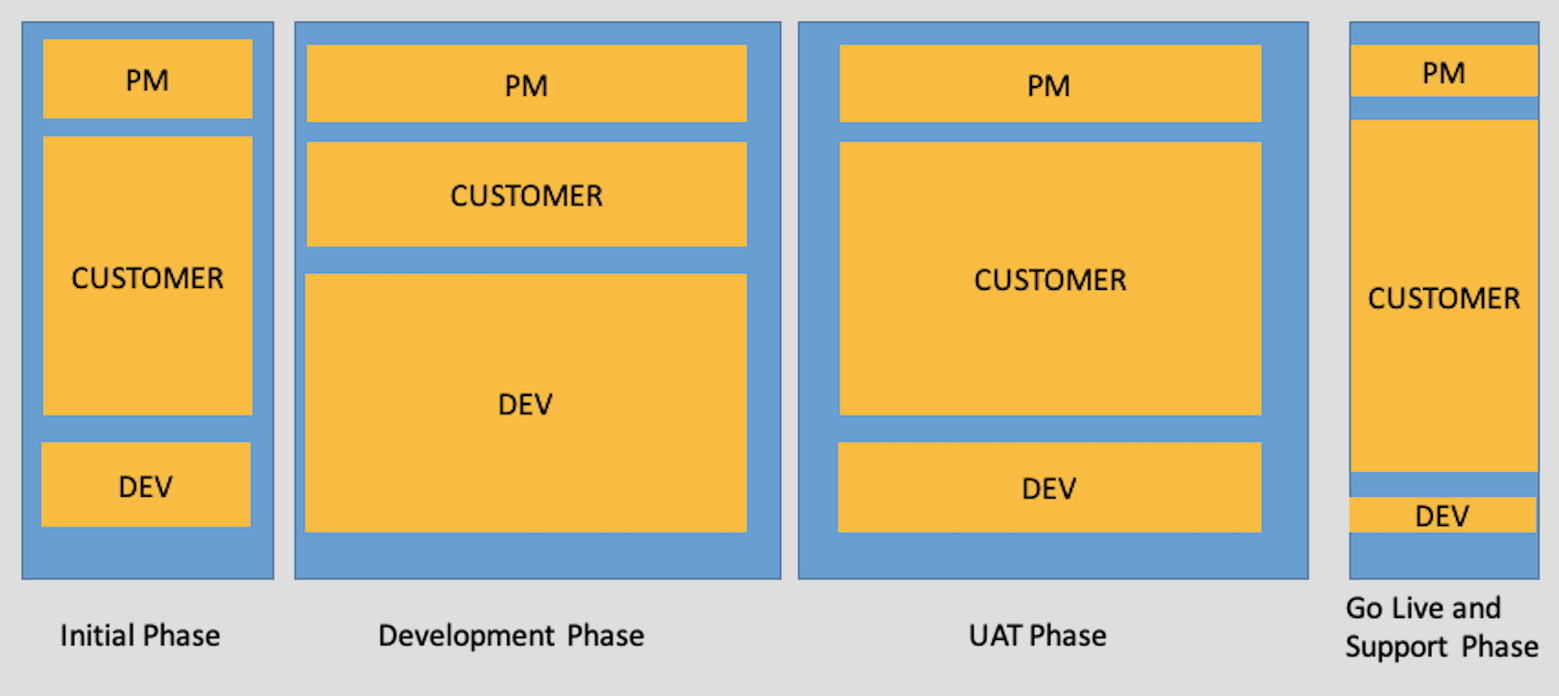
-
Personal
Estas pautas generales son para la asignación de recursos con habilidades técnicas y de gestión de proyectos de Jitterbit. Excluyen recursos como expertos en procesos de negocio del cliente y propietarios de puntos finales. Según el tamaño del proyecto, se recomiendan los siguientes niveles de personal:
-
Proyectos pequeños: Proyectos con 2 puntos finales y menos de 12 escenarios pueden ser manejados por un solo recurso técnico con habilidades en Jitterbit a tiempo parcial y un gerente de proyecto a tiempo parcial.
-
Proyectos medianos: Proyectos con 2-4 puntos finales y 12-20 escenarios pueden tener el mismo nivel de personal que los proyectos pequeños, con un personal más involucrado.
-
Proyectos grandes: Proyectos con 5 o más puntos finales y 20 o más escenarios tienen muchas dependencias al determinar el personal.
El rol del gerente de proyecto puede requerir una participación cercana al 100% a lo largo del proyecto si alguna de estas afirmaciones es verdadera:
-
El cliente requiere informes de estado detallados (como informes a una oficina de gestión de proyectos).
-
Numerosos expertos externos deben configurar los puntos finales del cliente para habilitar la integración.
-
Es probable que el cliente tenga dificultades para obtener requisitos de integración detallados.
-
El gerente de proyecto es inexperto o está ausente, y el cliente espera que usted gestione todo el proyecto.
¡Ejercite una estricta gestión del alcance y de cambios en estas situaciones! Deje claro al cliente que el éxito del proyecto depende de que el cliente elimine cualquier bloqueo y de que todos los recursos del proyecto cumplan con los plazos.
Al utilizar múltiples recursos de desarrollo, considere lo siguiente:
-
Tener más de un desarrollador en un solo proyecto de Jitterbit requiere un alto grado de coordinación (más trabajo para el gerente de proyecto) ya que es fácil implementar cambios y sobrescribir el trabajo de otra persona.
-
Esfuércese por asignar a los desarrolladores a diferentes escenarios de integración, o divida el trabajo en diferentes proyectos de Jitterbit.
-
Utilice revisiones de diseño y código entre desarrolladores.
-
Si es posible, aumente los recursos durante la fase de desarrollo y luego redúzcalos durante las fases de UAT y de puesta en marcha.
Reunión de inicio
El propósito de la reunión de inicio es reunir a los participantes clave del proyecto, típicamente los usuarios de negocio clave, expertos en la materia (SMEs), propietarios de los puntos finales y arquitectos de integración. Este tiempo se utiliza para que todos estén en la misma página y para aclarar los roles y responsabilidades. Durante la reunión de inicio, se deben completar las siguientes tareas:
- Fechas clave: Revisar todas las fechas clave (no solo la fecha de lanzamiento).
- Compartir información: Compartir información de contacto y documentos.
- Revisión de escenarios de integración: Revisar los escenarios de integración desde la definición del alcance.
- Este es un buen momento para confirmar si ha cambiado algo desde la última sesión de definición del alcance.
- Si es necesario, programar una reunión detallada de revisión del alcance.
- Roles y responsabilidades: Construir integraciones con Jitterbit es muy rápido, pero ten en cuenta que el mayor factor que retrasa un proyecto de integración son las dependencias no técnicas. Este es un buen momento para enfatizar ese punto. Aclara las responsabilidades de cada rol:
- PM
- Trabaja con el cliente y el equipo técnico para obtener y organizar los requisitos de integración detallados, incluidos los mapeos a nivel de campo. Los mapeos a nivel de campo son necesarios tanto para los recursos de desarrollo de Jitterbit como para los SMEs de los puntos finales.
- Organiza la disponibilidad de los SMEs de negocio y de los puntos finales para el proyecto y aborda rápidamente los elementos abiertos para la integración, como quién es quién, su nivel de compromiso con el proyecto, calendarios, etc.
- Comunica al cliente y al equipo técnico el progreso del desarrollo de la integración y los elementos abiertos que deben resolverse.
- Desarrollador de Jitterbit
- Logra entender los requisitos para diseñar la arquitectura de integración y trabaja con el cliente en consideraciones de diseño (por lotes/en tiempo real, APIs, gestión de datos maestros, requisitos de seguridad, etc.). El desarrollador debe estar familiarizado con la documentación de cómo hacer en el Estudio de Diseño de Jitterbit.
- Toma los requisitos detallados y utiliza la herramienta para desarrollar los escenarios de operación, siguiendo las mejores prácticas de Jitterbit.
- Supera rápidamente cualquier bloqueo y toma la iniciativa para resolverlos.
- Idealmente, el desarrollador de Jitterbit está en comunicación directa con el cliente. Aislar al desarrollador de Jitterbit de los SMEs y los clientes es una mala práctica y conduce a fallos en la comunicación y retrasos. Los recursos del proyecto deben ser un equipo y deben comunicarse fluidamente.
- SME de punto final
- Proporciona una profunda experiencia sobre las interfaces expuestas.
- Entiende los requisitos de integración y, si hay problemas potenciales —como la necesidad de un cambio en un punto final o si un requisito es inviable— alerta proactivamente al equipo.
- Está altamente disponible para ayudar con las pruebas unitarias. Esto puede incluir proporcionar datos de prueba, ofrecer retroalimentación rápida sobre los resultados de las pruebas de integración e interpretar las respuestas de error.
- PM
- Licencias y derechos: Revisar las licencias y derechos de Jitterbit y el proceso para solicitar derechos.
- Arquitectura de Harmony: Considerar estos puntos respecto a la arquitectura de Harmony:
- Si se utilizan agentes privados, priorizar la instalación de la arquitectura técnica y la conectividad a los puntos finales, principalmente para el desarrollo.
- Si se trabaja con sistemas locales, hay muchos pasos que pueden tardar en finalizar, como la adquisición de hardware, instalación de agentes privados, conectividad de red, credenciales de usuario de integración y el ciclo de pruebas. Dado que esto puede involucrar a múltiples grupos, comienza esto lo antes posible para el entorno de desarrollo.
- Espera que las lecciones aprendidas al configurar el entorno de desarrollo aceleren la configuración del entorno no de desarrollo, así que completa este paso tan pronto como sea razonable.
- Membresías de Harmony: Asegúrate de que los recursos de desarrollo estén añadidos a la organización de Harmony con permisos de Administrador (ver organizaciones de Jitterbit).
- APIs del Administrador de API: Si se utilizan APIs, revisar las dependencias. Verifica la URL predeterminada de la API de Jitterbit. Si el cliente comenzó a usar una prueba, es probable que la URL predeterminada aún incluya la palabra "prueba". Escalar a la licencia de Jitterbit para que se elimine antes de construir cualquier API (ver Administrador de API de Jitterbit).
- Reuniones futuras: Establecer la cadencia de reuniones futuras.
- Si la integración es parte de una implementación de punto final, entonces unirse a esas reuniones.
- De lo contrario, se prefieren reuniones cortas y frecuentes (diarias no son infrecuentes). También se puede configurar una plataforma de mensajería instantánea, como Slack.
Plan de proyecto de integración
Como se mencionó anteriormente, la integración tiene muchas dependencias. Los planes de proyecto tienden a venir en dos tipos:
- Parte de la implementación de un nuevo endpoint, como un ERP.
- Independiente, donde los endpoints son relativamente estables.
En el primer caso, las tareas del proyecto de integración pueden (y necesitarán) entrelazarse con el proyecto general. Por ejemplo, el desarrollo de la integración tendrá que esperar a que se configuren los objetos del endpoint.
En el segundo caso (independiente), se puede establecer un plan de proyecto solo para construir la integración.
Independientemente de si las tareas de integración son parte de otro plan o son independientes, las tareas son las mismas. Aquí hay un ejemplo de un plan de proyecto independiente:

Tenga en cuenta que el plan de proyecto comienza con los bloques de construcción básicos y luego itera a través de cada escenario. La sección de UAT (Pruebas de Aceptación del Usuario) se puede posponer hasta que todos los escenarios hayan alcanzado un punto de preparación.
Recolección de requisitos y desarrollo
Esta sección comienza cubriendo el enfoque general para la recolección de requisitos y el desarrollo, y luego se adentra en los detalles de mapeo, desarrollo, gestión del proceso de desarrollo, reutilización y manejo de registros y errores.
Enfoque general
El front-end de desarrollo gráfico y de bajo código de Jitterbit (Design Studio) se presta a un modelo iterativo. Este enfoque no es en cascada, donde todos los requisitos se documentan antes de que comience el desarrollo. Estos pasos clave describen el modelo iterativo general:
-
Comience con los escenarios de datos maestros. Dado que el enfoque es iterar rápidamente a través de un ciclo de definir-construir-probar, necesitamos tener los endpoints poblados con datos maestros antes de trabajar con datos transaccionales.
-
Comprenda qué sistemas son SOR (Sistemas de Registro) y cuáles son SOE (Sistemas de Compromiso):
- SOR (Sistemas de Registro): La fuente autorizada para datos maestros, generalmente un ERP.
- SOE (Sistemas de Compromiso): El sistema orientado al cliente o vendedor, como un sistema para comprar un producto.
-
Comprender los campos de datos clave y cuáles son compartidos (claves externas o foráneas).
- Típicamente, las claves de datos maestros del SOR se almacenan en el SOE para facilitar las actualizaciones de regreso al SOR. Por ejemplo, si SAP es el SOR y SFDC es el SOE, entonces los números de cliente de SAP se almacenan como IDs externas en SFDC.
- Dado que las claves compartidas pueden requerir personalización (lo que puede convertirse en un obstáculo de tiempo), es importante manejar esta área desde el principio.
Este diagrama muestra un ejemplo utilizando Salesforce como el SOE (Sistema de Compromiso) y SAP como el SOR (Sistema de Registro), en un flujo de datos maestros unidireccional con una escritura de regreso.
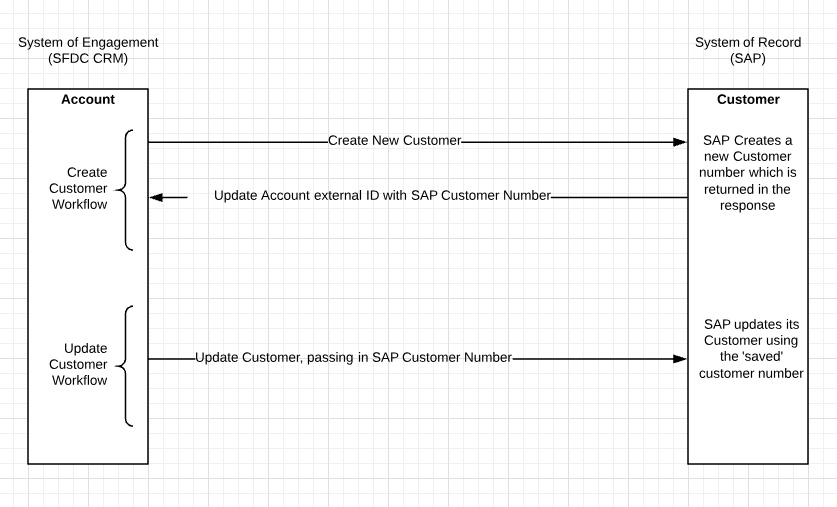
Si se trata de actualizaciones de datos maestros bidireccionales, reconozca que esto puede ser una integración complicada:
- Puede encontrar condiciones de carrera, lógica para excluir actualizaciones del usuario de integración separado de los usuarios de negocio, y claves compartidas mutuas.
- Frecuentemente, las reglas de negocio para los datos maestros no son las mismas en los puntos finales, y o bien la capa de integración tiene que acomodarlas, o los puntos finales necesitan ser personalizados. Esto puede ser un obstáculo, así que trabaje a fondo los escenarios para estos tipos de integraciones.
Mapeo
El PM debe hacer que el cliente comience a trabajar en los mapeos detallados a nivel de campo. Estos son necesarios tanto para los recursos de desarrollo de Jitterbit como para los SMEs de los puntos finales.
El cliente puede estar acostumbrado a ver los sistemas desde el punto de vista de la interfaz de usuario y puede no ser capaz de producir mapeos basados en el punto de vista de los esquemas. En ese caso, obtenga los esquemas en la hoja de cálculo de mapeo, si es posible. Esto puede requerir la ayuda del SME, documentación en línea, o el uso de Jitterbit iPaaS para conectarse al punto final y extraer los esquemas.
Si el mapeo es sencillo, puede hacer el mapeo "en vivo" utilizando Jitterbit iPaaS para incorporar los esquemas del punto final en una transformación durante una reunión con el cliente.
Esta hoja de cálculo demuestra un ejemplo de mapeos a nivel de campo:
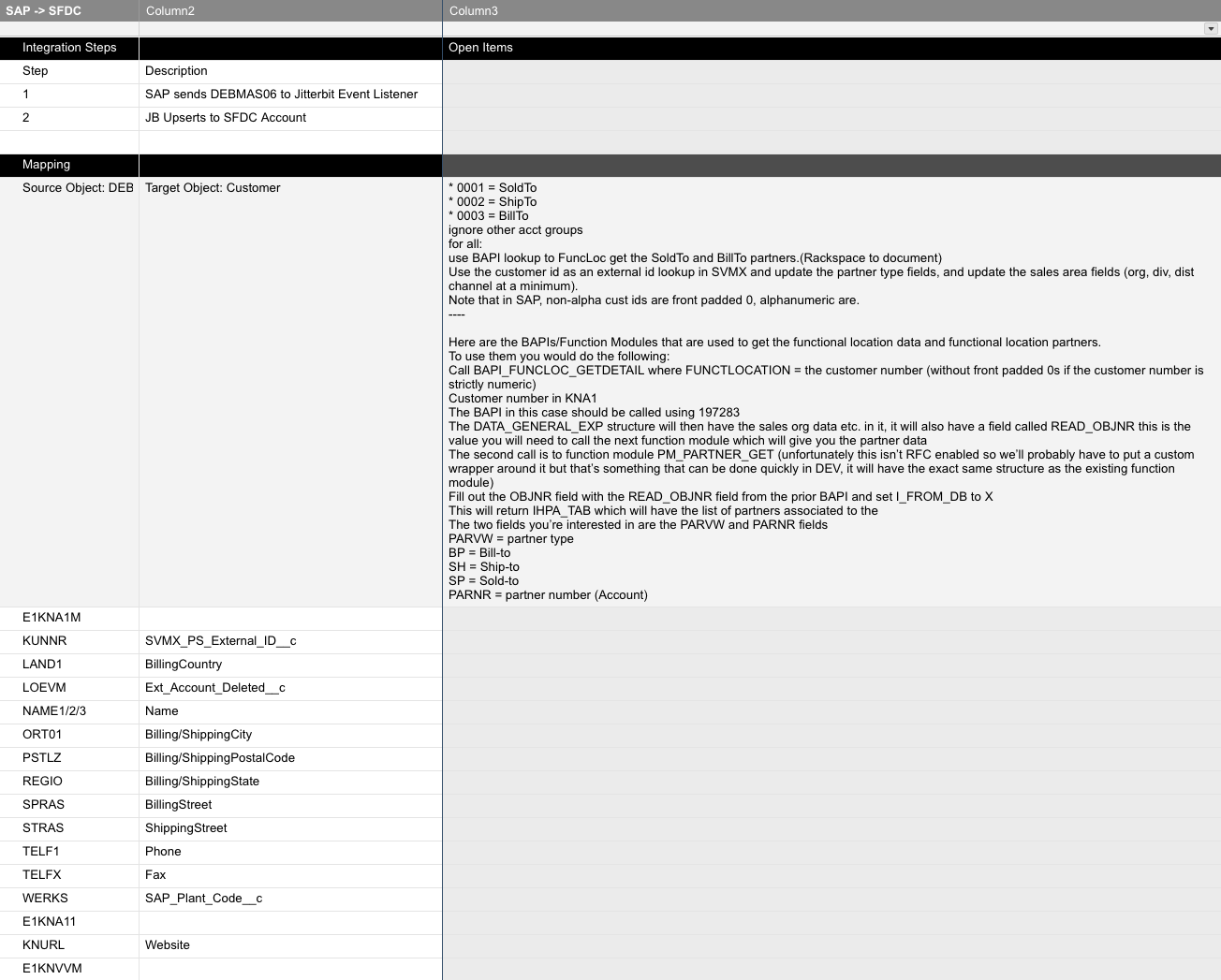
Cuando haya suficiente definición de escenario para comenzar, el objetivo es construir la integración en Jitterbit iPaaS y probar lo antes posible para identificar cualquier obstáculo.
A medida que el cliente trabaja en la hoja de cálculo de mapeo, preste especial atención a qué mapeos serán más difíciles. La transformación es donde se encuentra la realidad, lo que significa que aquí es donde mapeamos los métodos de integración expuestos entre sistemas. Es importante averiguar qué escenarios serán más difíciles que otros, ya que hay un alto multiplicador de tiempo para esos. Los mapeos fáciles pueden tardar solo minutos, mientras que los mapeos complejos pueden tardar días, así que busque estas situaciones y priorice:
-
Búsquedas en sistemas externos: Para algunos sistemas, puede que necesite buscar valores ejecutando consultas. El peligro aquí es el impacto en el rendimiento: tenga en cuenta que la transformación se ejecuta por cada registro. Si se procesan 200 registros, y la transformación está haciendo una búsqueda en cada registro, eso son 200 consultas. Esto no es un gran problema si el destino es una base de datos, pero si el destino es una API, eso también puede ser 200 inicios/cierres de sesión. Considere usar un diccionario para consultar los datos en un script de pre-operación, realizando así una única consulta.
-
Esquemas complejos: La transformación es "basada en iteraciones". Por ejemplo, si los esquemas de origen y destino son planos (como un nombre de cliente y una dirección de casa), entonces la transformación iterará una vez por registro, así:
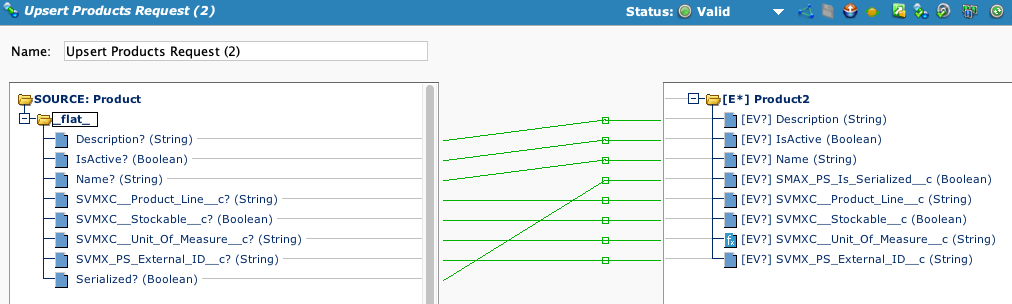
En el siguiente ejemplo (a continuación), tanto los esquemas de origen como los de destino son complejos, y la transformación tiene que procesar repetidamente las secciones secundarias. Para complicar aún más las cosas, puede que tenga que procesar las secciones secundarias de manera condicional:
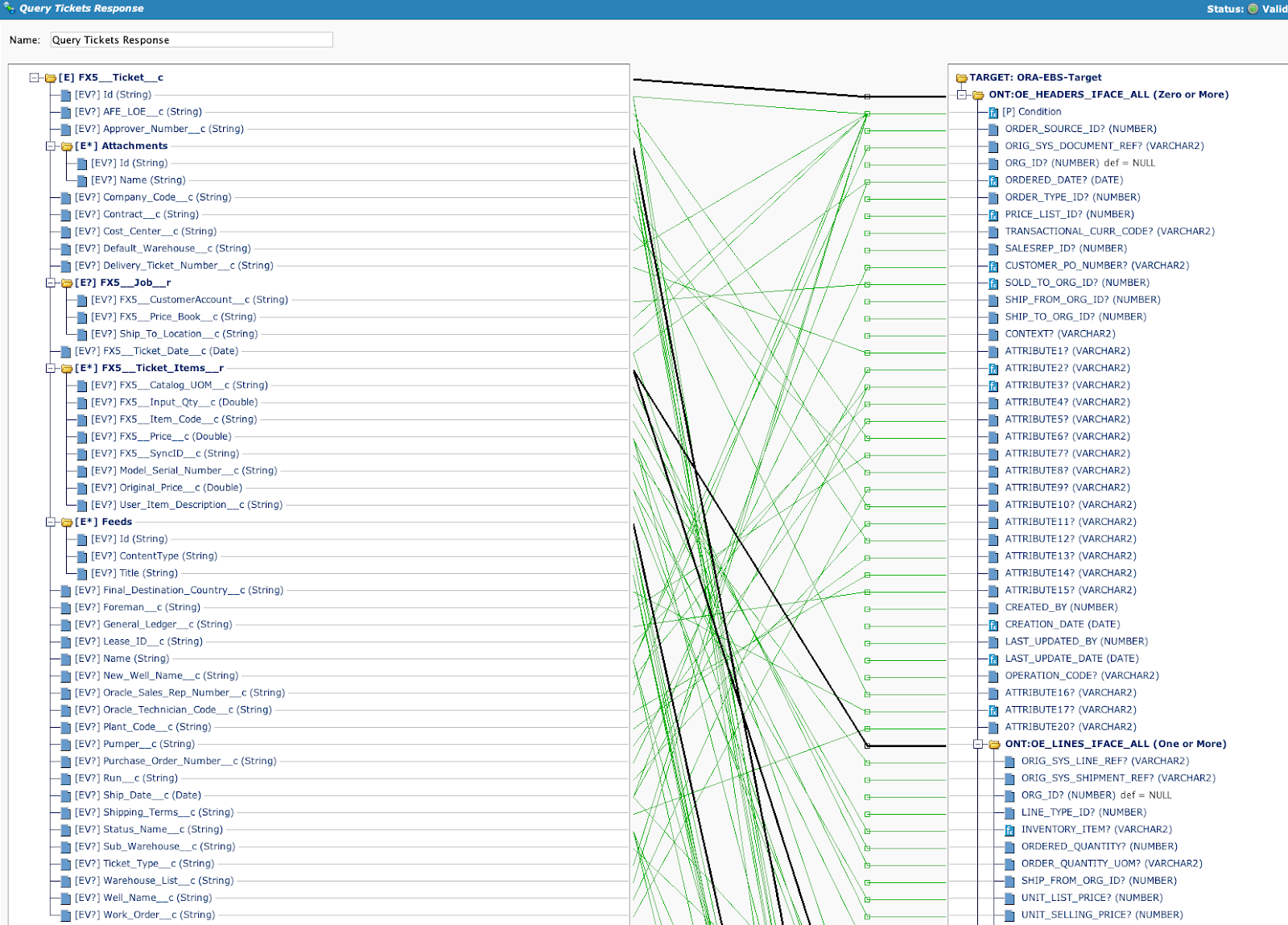
Con frecuencia, para avanzar rápidamente en mapeos complejos, es necesario reunir a los expertos en la materia (SMEs) de los puntos finales para definir los requisitos, lo que puede incluso requerir la participación del negocio y puede llevar a la personalización del punto final, todo lo cual puede retrasar el proyecto en general. Es vital identificar los requisitos de integración complejos lo antes posible y aclarar las dependencias rápidamente para mantener el proyecto en marcha.
Desarrollo
Como se mencionó anteriormente, el trabajo de desarrollo puede comenzar poco después del inicio:
- Conectar los endpoints.
- Identificar e implementar escenarios sencillos, particularmente si son datos maestros.
- Para integraciones complejas, incluso si no están completamente mapeadas, tomar medidas para llevar los métodos de integración expuestos a una transformación.
- Los esquemas (por lo general) solo se aplican al tratar con bases de datos y servicios web.
- Al trabajar con archivos, pueden tener un formato jerárquico, que debe construirse manualmente en Jitterbit. Esto puede ser laborioso, así que comienza con eso temprano.
- Para endpoints de bases de datos, será más eficiente construir vistas que hacer que el proyecto de integración una tablas. Un procedimiento almacenado puede ser un mejor enfoque que realizar actualizaciones complejas.
- Al trabajar con conectores de endpoints, utiliza los asistentes de Jitterbit iPaaS y asegúrate de que todos los objetos en alcance estén disponibles. Esta es una buena manera de validar que el usuario de integración tiene todos los permisos necesarios para trabajar.
- El desarrollador debe revisar los esquemas de origen y destino para hacer preguntas de mapeo "inteligentes", como estas:
- "¿Tenemos todos los campos obligatorios?"
- "Si pasamos un ID de registro, ¿el endpoint actualizará automáticamente un registro o intentará crearlo?"
- "¿Cuántos registros se pueden pasar en una llamada?"
- "Este esquema de IDoc de SAP utiliza abreviaturas en alemán. ¿Alguien Sprechen Sie Deutsch?"
- No pases por alto la revisión del esquema de respuesta (si es un servicio web), particularmente en cuanto a cómo se manejan los errores. Algunos esquemas indican éxito o fracaso en general, mientras que otros proporcionan códigos que necesitan ser evaluados.
Gestión del proceso de desarrollo
Un buen enfoque para gestionar el proceso de desarrollo es tomar los escenarios capturados durante la definición y rastrear hitos relacionados con cada escenario. Este es un ejemplo de hoja de cálculo utilizada para rastrear hitos clave en un desarrollo de integración:
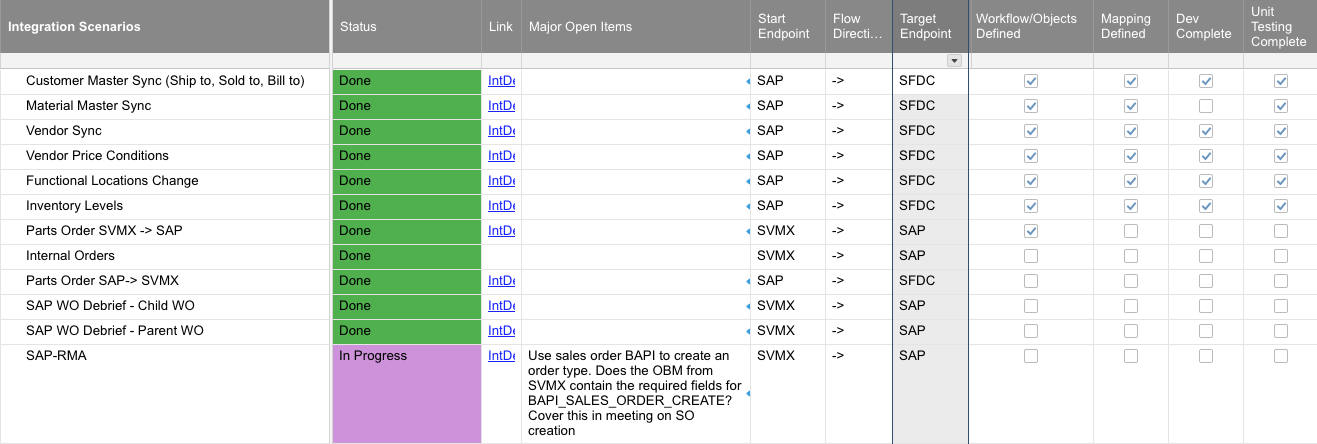
Trata cada escenario como una mini-iteración de desarrollo, comenzando con las dependencias de datos (como los datos maestros). Luego construye operaciones, construye transformaciones, obtiene algunos datos de prueba, envía a un endpoint, maneja la respuesta. No busques la perfección. Apunta a mover datos de prueba simples del punto A al punto B y luego pasa al siguiente escenario. Luego, itera el desarrollo del escenario de integración, identificando bloqueos hasta que se hayan desarrollado y probado unitariamente tanto el escenario de éxito principal como los escenarios de error.
El primer conjunto de integraciones será el que enfrente más problemas, como conectividad, permisos, campos faltantes, etc. Así que cuanto más rápido lleguemos a este punto y despejemos los bloqueos, mejor. No estamos buscando la perfección desde el principio.
Comienza con un pequeño conjunto de datos de prueba. Esto puede estar codificado en los scripts o usar una consulta que esté limitada a solo unos pocos registros.
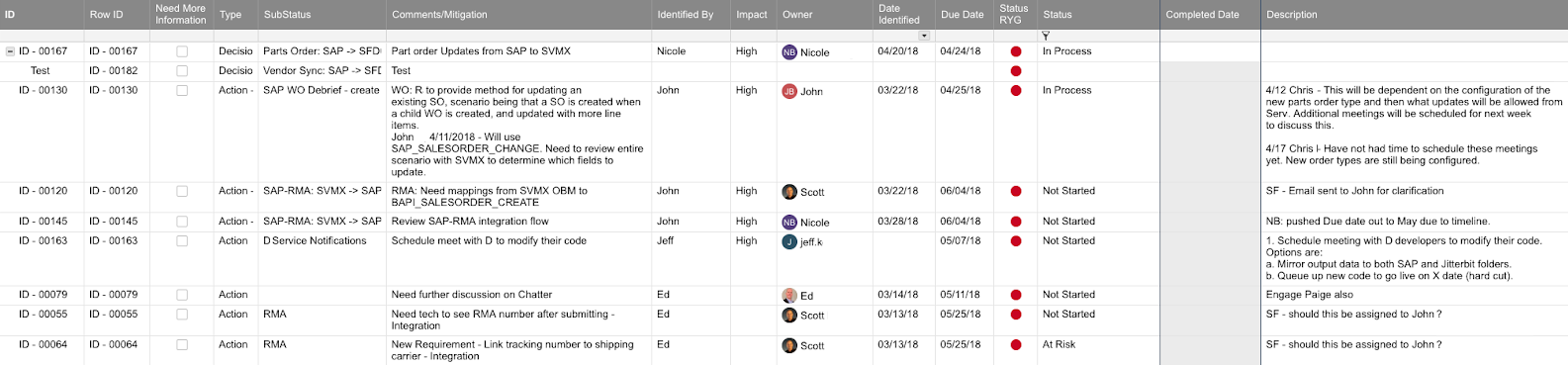
Si hay un bloqueo menor, documéntalo, asigna la resolución a la persona adecuada y continúa con otro escenario. Nuevamente, el objetivo es encontrar rápidamente las minas terrestres para que puedan ser despejadas, y esa responsabilidad suele ser del cliente y/o del SME.
Aquí hay un ejemplo de una hoja de cálculo para el seguimiento de problemas:
Reutilización
Como cualquier otra plataforma de desarrollo de software, el desarrollo puede acelerarse si no reinventas la rueda. Jitterbit iPaaS tiene varias formas de habilitar esto:
- Scripts
- Se pueden construir funciones personalizadas completas y llamarlas desde muchas operaciones. La regla general es que si tienes que escribir el mismo script dos veces, conviértelo en un script llamable.
- Fuentes y Destinos
- Pasa variables globales y/o del proyecto en lugar de codificar cosas como rutas de archivos o hosts FTP.
- Usa una variable global como un espacio de trabajo intermedio en lugar de fuentes y destinos específicos de la operación.
- Operaciones
- Las operaciones de tarea única se pueden construir una vez y usar muchas veces, particularmente aquellas que manejan el manejo de errores y el registro.
- Las operaciones en un proyecto pueden ser llamadas desde otro. Ten en cuenta que los registros aparecerán en los proyectos nativos (llamados). Pero dado que el alcance de las variables globales es la cadena de operaciones (que puede ser llamada desde más de un proyecto), es posible obtener los resultados de la operación remota y registrarlos en el proyecto que llama.
Registro y manejo de errores
Un conjunto de requisitos que a menudo se pasa por alto tiene que ver con el registro y el manejo de errores. El cliente puede no tener requisitos específicos, especialmente si este es su primer proyecto de integración, por lo que el cliente necesitará ayuda con las mejores prácticas en esta área. Los puntos clave son los siguientes:
- Jitterbit iPaaS realiza el registro de operaciones de forma predeterminada.
- Es fácil registrar datos adicionales, lo cual es muy útil para la resolución de problemas.
- Aquí es donde puede darse cuenta el cliente de que sus escenarios de integración requerirán soporte interno.
- Cuando se identifica un problema en un endpoint, si una posible causa raíz es la integración, entonces un recurso necesitará inspeccionar los registros. Cuanto más claros e informativos sean los registros, más rápido será el proceso de resolución de problemas.
- Hay dos clases amplias de alertas: alertas relacionadas con datos y alertas de fallos técnicos, que pueden o no necesitar ir al mismo grupo. La configuración de fallos técnicos es fácil, pero el registro relacionado con datos es completamente personalizado y es más fácil incluirlo durante el desarrollo de la integración en lugar de agregarlo después.
- Design Studio puede usar el correo electrónico con bastante facilidad, donde el servicio de correo se trata como un endpoint del servicio de correo del cliente, utilizando un objetivo de correo electrónico de Design Studio. Aunque esto generalmente es fácil de configurar, este paso no debe dejarse para el final.
- La Consola de Administración de Jitterbit se puede usar para configurar notificaciones adicionales relacionadas con la organización.
Para información detallada, consulte Configurar alertas, registro y manejo de errores y la página de Alertas.
Manejo de reglas de negocio
El gran debate: incluir — o no incluir — reglas de negocio.
Muchos clientes comienzan pensando "no quiero incluir reglas de negocio en el middleware; quiero mantener las cosas simples", ¡pero luego proporcionan los requisitos exactamente opuestos!
La arquitectura ideal del middleware establece que la capa de integración debe ser lo más ágil posible, enfocándose en sus fortalezas: transformación de datos, procesamiento de escenarios y orquestación, conexión de endpoints, y registro y alertas. Agregar reglas de negocio engorrosas solo empañará la perfección de esta arquitectura al dispersar el soporte de reglas de negocio a través de los límites de los endpoints. Es decir, si una regla de negocio cambia, no solo cambia en la aplicación; también cambia en el middleware. Además, debido a que el middleware es confuso, turbio y místico, el mantenimiento de reglas es agotador.
La realidad irrumpe de manera brusca, ya que Jitterbit iPaaS tiene que trabajar con lo que las aplicaciones exponen:
- Los datos se presentan de manera deficiente, y la única forma de procesarlos es aplicar reglas de negocio ("si el valor = a, departamento = ventas, si b, departamento = operaciones, si c, departamento = soporte").
- Los datos de origen están incompletos ("si el país = EE. UU., el año fiscal es calendario, si el país = Reino Unido, el año fiscal es de abril a marzo")
- El escenario de integración está impulsado por datos ("si la orden de trabajo contiene líneas que utilizan un tercero, procesa esa línea como una entrada de cuentas por pagar, de lo contrario, actualiza como una orden de servicio")
Sí, todo lo anterior podría ser manejado por el endpoint. Pero esto asume que el cliente tiene los recursos y el tiempo para personalizar el endpoint o cambiar una API. Si todo eso está disponible, entonces, por supuesto, hazlo. Sin embargo, el caso habitual es que los endpoints son más difíciles de cambiar y mantener que el proyecto de integración.
Cuando se deben manejar reglas de negocio, las mejores prácticas son las siguientes:
- Externalizar donde sea posible. Por ejemplo, tener datos en una tabla donde un usuario pueda mantenerlos.
- Usar variables de proyecto. Estas se exponen en la Consola de Administración de Jitterbit junto con documentación específica. El caso de uso principal es para credenciales de endpoint específicas del entorno, pero también se pueden usar para impulsar la lógica de orquestación y las condiciones de consulta.
- Agregar registro detallado personalizado y manejo de errores de datos, para que si y cuando cambien las reglas de negocio, el efecto en la integración sea obvio.
Agentes y entornos
El agente de Jitterbit es el caballo de batalla de la integración. Design Studio no ejecuta realmente ningún proceso de operación. Todo sucede en un agente de Jitterbit. Una decisión clave temprana es qué tipo de agente utilizar: ya sea Privado o en la Nube (ver agentes de Jitterbit).
Si alguna de estas afirmaciones es verdadera, entonces el proyecto debe ejecutarse en un agente privado:
- Un endpoint está detrás del firewall del cliente. Esto puede ser una aplicación o un recurso compartido de red.
- Se requiere un conector o controlador que no está disponible en los agentes en la nube. Por ejemplo, el controlador de Excel está disponible solo en agentes privados.
- Los requisitos de seguridad del cliente son tales que no se permite que los datos salgan de su firewall.
De lo contrario, los agentes en la nube son una opción. Desde la perspectiva de la línea de tiempo del proyecto, esto es ideal, ya que evita todos los pasos relacionados con que un cliente tenga que adquirir hardware de servidor e instalar el software del agente de Jitterbit. Sin embargo, independientemente de si se utilizan agentes en la nube o privados, aún se deben configurar miembros y entornos.
Dependiendo del nivel de licencia, un cliente tendrá dos o más licencias de agente privado. Además, el cliente tendrá derecho a un número de entornos, que generalmente se configuran siguiendo las categorías estándar del ciclo de vida del desarrollo de software (desarrollo, calidad, preproducción, producción, soporte, etc.). La herramienta de transferencia de Jitterbit trabaja con entornos para permitir la promoción de proyectos de integración.
Con respecto a los agentes y entornos, tenga en cuenta estos puntos importantes:
-
Identificar un entorno como "producción" no confiere nada especial. No se ejecuta más rápido ni es más resistente. Un entorno es prácticamente igual a cualquier otro.
-
Un entorno de Harmony se puede utilizar de muchas maneras. Si el cliente está proporcionando integración para terceros, un entorno se puede utilizar como un contenedor para proyectos dedicados de la empresa.
-
Un solo agente privado puede ejecutar más de un entorno.
-
Una pregunta frecuente es si es necesario cambiar alguna regla de firewall de red. Por lo general, la respuesta es "no", a menos que el cliente esté restringiendo el tráfico HTTP saliente desde servidores y/o puertos. La comunicación de Harmony a agente es completamente saliente desde el agente hacia Harmony.
Un grupo de agentes es una parte obligatoria de la arquitectura del agente. Aparte de ser el contenedor virtual que alberga a los agentes privados, desempeña otro papel importante. A diferencia de las herramientas de gestión de servidores tradicionales que requieren aplicaciones adicionales como equilibradores de carga, Harmony facilita lograr la resiliencia del servidor a través del equilibrio de carga y la conmutación por error. Simplemente al agregar un agente a un grupo, el agente se convierte automáticamente en parte de un clúster de servidores.
Para ser claros, al ejecutar una operación en un grupo de agentes con múltiples agentes, solo un agente está ejecutando esa operación. La operación no se divide y se ejecuta en todos los agentes del grupo. Agregar agentes a un grupo no hará que las operaciones se ejecuten más rápido (por lo general). La excepción es un diseño que requiere un grupo de agentes para atender API de entrada de alto tráfico, en cuyo caso distribuir la carga entre múltiples agentes es una buena idea.
Para comenzar el desarrollo, solo se necesita un agente privado y un entorno. Se pueden agregar agentes adicionales a grupos, y se pueden añadir nuevos entornos a medida que avanza el proyecto (todo dentro de los límites de la licencia, por supuesto).
Si obtener incluso un solo agente es problemático, se puede ejecutar un agente privado de Jitterbit en una estación de trabajo. La mejor manera de hacerlo es utilizar el agente de Docker para evitar conflictos en el escritorio.
Procesamiento por lotes y basado en eventos (en tiempo real)
Para cada escenario de integración, hay una gran decisión: ¿Cómo se activará la integración?
Básicamente, hay dos formas: un enfoque por lotes, como por medio de un horario, o activado por un evento, como a través de una API.
Desde la perspectiva de un proyecto de integración, implementar el procesamiento basado en eventos requiere mucho menos esfuerzo que el procesamiento por lotes. ¿Por qué es eso?
-
Aunque Jitterbit admite una función de programación, la mayoría de los procesos por lotes requieren un proceso de obtención de datos basado en una "fecha de última modificación", lo que requiere scripting personalizado para recuperar la última vez que se ejecutó la operación, decidir si la operación se ejecutó con éxito y luego actualizar el repositorio de marcas de tiempo. En el camino, se deben manejar zonas horarias de puntos finales potencialmente diferentes, horario de verano y formatos de fecha. No olvides: solo consulta los datos que han cambiado por todos los usuarios excepto por el usuario de integración. Y, al migrar a otros entornos, debes manejar la activación y desactivación de horarios según el plan del proyecto. Ninguno de estos son grandes desafíos, pero claramente se está imponiendo una carga de responsabilidad de desarrollo y gestión en la capa de integración.
-
Compara el procesamiento por lotes con el basado en eventos: la operación se ejecuta solo cuando es llamada por el punto final. Sin horarios, sin marcas de tiempo, sin zonas horarias. La responsabilidad recae claramente en el punto final.
-
El principal mecanismo de procesamiento basado en eventos de Jitterbit iPaaS es a través de las APIs del API Manager. Aunque hay un costo de licencia más alto, vale la pena.
-
Obviamente, si el punto final no admite la llamada a una API, entonces el procesamiento por lotes es tu única opción. Además, el cliente puede mostrarse reacio a utilizar una API si el procesamiento por lotes es una opción.
Luego está esa extraña quimera, la opción de "lote rápido", donde el requisito empresarial es obtener datos en un destino lo más rápido posible, pero el cliente no quiere implementar una API. La conversación es algo así:
Jitterbit: Para el escenario de pedidos, ¿cuándo quieres que aparezcan los pedidos en el ERP?
Cliente: Lo antes posible.
Jitterbit: Entonces queremos en tiempo real y usar APIs.
Cliente: No, no quiero hacer eso. ¿No podemos hacer un lote realmente rápido?
Jitterbit: ¿Te refieres a verificar cada 10 minutos si hay nuevos pedidos?
Cliente: No, más rápido que eso. ¿Cuál es el tiempo mínimo para un horario?
Jitterbit: Um… un minuto.
Cliente: ¡Genial! ¡Consulta el sistema de pedidos cada minuto! ¡Hecho!
Jitterbit: Espera. Te das cuenta de que estarás golpeando el sistema de pedidos, donde la mayor parte del tiempo no hay datos para procesar. Tendrás muchos ciclos desperdiciados, y revisar los registros de operación será un dolor. Si tu requisito empresarial es realmente mover datos lo más rápido posible, entonces necesitas usar una API. Además, hay una serie de otros beneficios…
Y aquí el cliente, fortalecido con esta información, hace lo correcto y aprueba el uso de una API. Pero si no eres lo suficientemente convincente, contacta a nuestro equipo de marketing; ellos tienen esto cubierto.
Ten en cuenta estas consideraciones para usar APIs:
- Asegúrate de entender los requisitos máximos de procesamiento de la API.
- Entiendes que la API se llama cuando un usuario cambia un registro. ¡Fácil! El diseño es para que la operación se llame directamente y luego actualice inmediatamente el destino.
- Pero lo que el cliente olvidó decirte (y tú olvidaste preguntar) es que cuando hay una actualización masiva de registros, en lugar de obtener un registro cada 10 minutos, obtienes 10,000. Jitterbit hará su trabajo y generará tantos hilos como el servidor pueda manejar y encolará el resto del tráfico entrante, y comenzará a actualizar el destino. Esto podría abrumar al sistema de destino.
- Verifica la salida máxima y considera agregar una cola JMS, una base de datos o incluso un archivo temporal para mantener los datos de la API entrantes antes de procesarlos en el destino.
- Las APIs están licenciadas independientemente de los entornos. Así que si se usa una API para cada uno de los entornos de desarrollo, QA y producción, eso son tres licencias de API, no una.
Transferencia
Dependiendo del proceso del cliente, el proyecto necesitará ser transferido a un entorno de QA antes de UAT, o las pruebas se realizan en un entorno de desarrollo y luego el proyecto se transfiere a un entorno de producción.
-
Si es posible, no transfieras al siguiente entorno superior hasta que el proyecto esté casi completo. Una vez que se realiza una transferencia, debes recordar transferirlo a otros entornos.
-
Evita hacer cambios en un entorno "superior" para resolver rápidamente un problema, pensando que sincronizarás los entornos más tarde. En su lugar, realiza la corrección en el entorno "inferior" y transfórmalo. No hay una forma infalible de identificar diferencias granulares entre proyectos, por lo que es fácil perder el rastro de los cambios.
Pruebas de aceptación del usuario (UAT)
Todos los escenarios están construidos, todas las pruebas unitarias son exitosas y los usuarios están listos para probar la integración. ¡Es hora de dejar que los usuarios interactúen con la integración, y ahora descubrirás cuáles son los requisitos reales!
Esta fase puede ser un proceso fluido o muy intenso. Realmente depende de la calidad de los pasos anteriores. Ten en cuenta estos consejos durante la fase de UAT:
-
Prepárate para reaccionar rápidamente a medida que surjan problemas. Si has hecho bien tu trabajo, la mayoría de los problemas estarán relacionados con los datos, no con la parte técnica. Así que asegúrate de que los SMEs del endpoint estén disponibles para clasificar los problemas.
-
Siempre que sea posible, haz que el usuario tome la iniciativa en la solución de problemas: reaccionando a alertas, leyendo registros, rastreando la lógica de integración. Idealmente, la persona que realizará este trabajo en producción lo hará durante esta fase.
-
Mantén un seguimiento cercano de los problemas que surjan durante UAT y cómo se resuelven. Una situación frecuente es que los problemas afectan los datos del endpoint, y mientras se soluciona el problema de integración, los datos no lo son y se convierten en un problema recurrente con las pruebas.
-
Planea reuniones frecuentes con todos los involucrados para resolver cualquier bloqueo.
-
A medida que el tiempo lo permita, comienza la documentación.
-
Desarrolla tu plan de transición.
-
En el entorno de producción, realiza pruebas de conexión y cualquier otra prueba que puedas realizar o que esté permitida.
Post-producción y monitoreo
¡UAT completado! ¡Aprobación del usuario realizada! ¡Es hora de encender este cohete!
En esta etapa, la transferencia final a producción debería estar completa. Si se están utilizando horarios, ten en cuenta que puedes transferirlos a producción y desactivarlos en la Consola de Gestión de Jitterbit. Luego, puede ser responsabilidad del cliente activar los horarios.
Espera reunirte con el cliente periódicamente para asegurarte de que las cosas vayan bien, anticipando algunas preguntas.
Planifica una reunión de "cierre" para entregar la documentación del proyecto y realizar cualquier transferencia final de conocimiento.