Agente de Conhecimento Jitterbit
Visão Geral
O Agente de Conhecimento Jitterbit (Agente de Conhecimento) é um agente de IA fornecido através do Jitterbit Marketplace que tem como objetivo permitir que a equipe interna da sua organização obtenha respostas inteligentes a partir dos dados internos da organização. Este agente utiliza a técnica de Geração Aumentada por Recuperação (RAG), que combina o raciocínio de LLM com acesso a ferramentas externas e fontes de dados. Ele faz o seguinte:
-
Conecta-se e busca informações das seguintes fontes usando o Jitterbit Studio:
- Páginas do Atlassian Confluence
- Problemas do Atlassian Jira
- Documentos do Google Drive
- Casos de suporte do Salesforce (do objeto
Case)
-
Integra-se com o Azure OpenAI para alimentar um chatbot inteligente de IA usando dados das fontes acima acessados por meio de uma API personalizada criada com o Jitterbit API Manager.
Este documento explica como configurar e operar este agente de IA. Ele abrange arquitetura e pré-requisitos, exemplos de prompts que mostram o que o agente pode fazer, e etapas para instalar, configurar e operar o agente de IA.
Arquitetura do agente de IA
O diagrama a seguir ilustra a arquitetura implementada no Agente de Conhecimento:
Fluxo de dados do agente
Slack app/bot) JB_CUSTOM_API(
Jitterbit API Manager
custom API) REQ_AZURE_OPENAI(Request to
Azure OpenAI) SLACK_API_REQ_H(Slack
API request handler
workflow) RES_AZURE_OPENAI(Response from Azure OpenAI) TIMEOUT(Timeout handling) subgraph LIVE_AGENT_DATA_FLOW[ ] direction RL subgraph EXTAPP[**External app**] SLACKAPP end JB_CUSTOM_API subgraph STUDIO[ **Jitterbit Studio**] REQ_AZURE_OPENAI RES_AZURE_OPENAI SLACK_API_REQ_H TIMEOUT end end SLACKAPP -->|Request| JB_CUSTOM_API JB_CUSTOM_API -->|Request| SLACK_API_REQ_H JB_CUSTOM_API -->|Response| SLACKAPP SLACK_API_REQ_H -->|Response|JB_CUSTOM_API SLACK_API_REQ_H --> REQ_AZURE_OPENAI REQ_AZURE_OPENAI --> RES_AZURE_OPENAI RES_AZURE_OPENAI --> SLACK_API_REQ_H REQ_AZURE_OPENAI --> TIMEOUT --> SLACK_API_REQ_H classDef Clear fill:white, stroke:white, stroke-width:0px, rx:15px, ry:15px classDef Plain fill:white, stroke:black, stroke-width:3px, rx:15px, ry:15px class LIVE_AGENT_DATA_FLOW Clear class EXTAPP,APIM,STUDIO Plain
Carregamento inicial de dados e fluxos de trabalho de manutenção de dados
Pré-requisitos
Para usar o Agente de Conhecimento, os seguintes componentes são necessários ou assumidos no design do agente.
Componentes do Harmony
É necessário ter uma licença do Jitterbit Harmony com acesso aos seguintes componentes:
- Jitterbit Studio
- Jitterbit API Manager
- Agente de Conhecimento Jitterbit adquirido como um complemento de licença
Endpoints suportados
Os seguintes endpoints estão incorporados ao design do agente.
Modelo de linguagem grande (LLM)
O agente de IA utiliza Azure OpenAI como o provedor de LLM. Para usar o Azure OpenAI, é necessário ter uma assinatura do Microsoft Azure com permissões para criar e gerenciar os seguintes recursos:
- Recurso do Azure OpenAI com um modelo
gpt-4oougpt-4.1implantado. - Armazenamento do Azure com um contêiner Blob para armazenar dados recuperados.
- Pesquisa de IA do Azure com um serviço de pesquisa que pode ser configurado com um índice e indexador.
Dica
Para informações sobre preços, consulte camadas de preços do Azure AI Search.
Base de conhecimento
Você pode usar qualquer um ou todos esses endpoints como a base de conhecimento para este agente de IA:
- Atlassian Confluence: A fonte das páginas do Confluence.
- Atlassian Jira: A fonte dos problemas do Jira.
- Google Drive: A fonte dos arquivos armazenados em um drive compartilhado do Google.
- Salesforce: A fonte dos casos de suporte ao cliente do objeto
Case.
Interface de chat
O design do agente incorpora o Slack como a interface de chat para interagir com o agente de IA. Se você quiser usar um aplicativo diferente como interface de chat, um fluxo de trabalho separado e instruções para uma configuração de API genérica estão incluídos neste agente de IA.
Exemplos de prompts
Aqui estão exemplos de prompts que o Agente de Conhecimento pode lidar com acesso aos dados apropriados. O agente pode encontrar informações em qualquer um ou todos os endpoints conectados.
- "Estou tendo um problema com o componente 'ABC'. Você pode ajudar com isso?"
- "Como posso me conectar a um banco de dados MySQL usando JDBC?"
- "Você pode me dar detalhes sobre o ticket do Jira número 123?"
- "Existem tickets do Jira relacionados ao conector SQL?"
- "Qual é a política de segurança para instalar software no meu computador de trabalho?" (Pode haver um documento no Google Drive ou uma página do Confluence sobre este tópico.)
Instalação, configuração e operação
Siga estas etapas para instalar, configurar e operar este agente de IA:
- Baixar personalizações e instalar o projeto do Studio.
- Revisar fluxos de trabalho do projeto.
- Criar recursos do Microsoft Azure.
- Criar o aplicativo Slack.
- Configurar uma conta de serviço do Google e unidade compartilhada.
- Configurar variáveis do projeto.
- Testar conexões.
- Implantar o projeto.
- Criar a API personalizada do Jitterbit.
- Revisar fluxos de trabalho do projeto.
- Acionar os fluxos de trabalho do projeto.
- Solução de problemas.
Baixar personalizações e instalar o projeto
Siga estas etapas para baixar arquivos de personalização e instalar o projeto do Studio:
-
Faça login no portal Harmony em https://login.jitterbit.com e abra Marketplace.
-
Localize o agente de IA chamado Agente de Conhecimento Jitterbit. Para localizar o agente, você pode usar a barra de pesquisa ou, no painel Filtros sob Tipo, selecionar Agente de IA para limitar a exibição aos agentes de IA disponíveis.
-
Clique no link Documentação do agente de IA para abrir sua documentação em uma nova aba. Mantenha a aba aberta para consultar depois de iniciar o projeto.
-
Clique em Iniciar Projeto para abrir um diálogo de configuração em duas etapas para baixar personalizações e importar o agente de IA como um projeto do Studio.
Nota
Se você ainda não comprou o agente de IA, Obter este agente será exibido em vez disso. Clique nele para abrir um diálogo informativo, em seguida, clique em Enviar para que um representante entre em contato com você sobre a compra do agente de IA.
-
No passo de configuração 1, Baixar Personalizações, os seguintes arquivos são fornecidos para facilitar a configuração do índice e do indexador no Azure AI Search e para criar o aplicativo Slack. Selecione os arquivos e clique em Baixar Arquivos:
-
Arquivos de definição JSON do índice e indexador do Azure AI Search
Azure_AI_Search_Datasource_Definition.jsonAzure_AI_Search_Index_Definition.jsonAzure_AI_Search_Indexer_Definition.json
-
Arquivo de manifesto do aplicativo Slack
slack_app_manifest.json
Dica
O diálogo de configuração inclui um aviso para não importar o modelo antes de aplicar as personalizações do endpoint. Esse aviso não se aplica a este agente de IA e pode ser ignorado. Siga a ordem recomendada de etapas nesta documentação.
Clique em Próximo.
-
-
No passo de configuração 2, Criar um Novo Projeto, selecione um ambiente onde deseja criar o projeto no Studio e, em seguida, clique em Criar Projeto.
-
Um diálogo de progresso é exibido. Depois que ele indicar que o projeto foi criado, use o link do diálogo Ir para o Studio ou abra o projeto diretamente na página Projetos do Studio.
Criar recursos do Microsoft Azure
Crie os seguintes recursos do Microsoft Azure e mantenha as seguintes informações para configurar o agente de IA. Para criar e gerenciar esses recursos, você deve ter uma assinatura do Microsoft Azure com as permissões apropriadas.
Contêiner do Azure Blob
Você deve criar um contêiner do Azure Blob para armazenar os detalhes do cliente. Os dados do contêiner Blob serão indexados no Azure AI Search usando um índice e um indexador.
Você precisará da URL SAS do contêiner para usar na determinação dos valores das variáveis do projeto do Azure Blob Storage. Para gerar a URL SAS:
- No portal do Azure, navegue até Contas de armazenamento e abra a conta de armazenamento específica.
- No menu de recursos sob Armazenamento de dados, selecione Contêineres e abra o contêiner específico.
- No menu de recursos sob Configurações, selecione Tokens de acesso compartilhado.
-
Use o menu Permissões para verificar se a URL da assinatura de acesso compartilhado (SAS) para este contêiner possui, no mínimo, permissões de Leitura e Gravação:
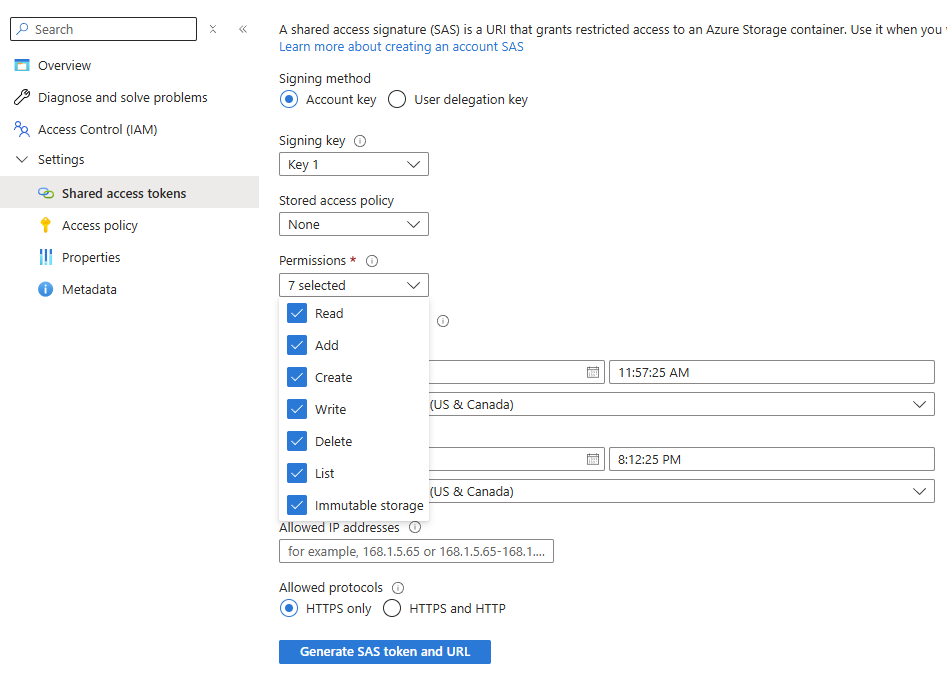
-
Clique em Gerar token e URL SAS.
- Copie o Blob SAS URL exibido na parte inferior.
- Determine os valores das variáveis do projeto do Azure Blob Storage a partir do URL SAS. O URL SAS está no formato
{{ azure_blob_base_url }}/{{ Azure_Blob_Container_Name }}?{{ azure_blob_sas_token }}.
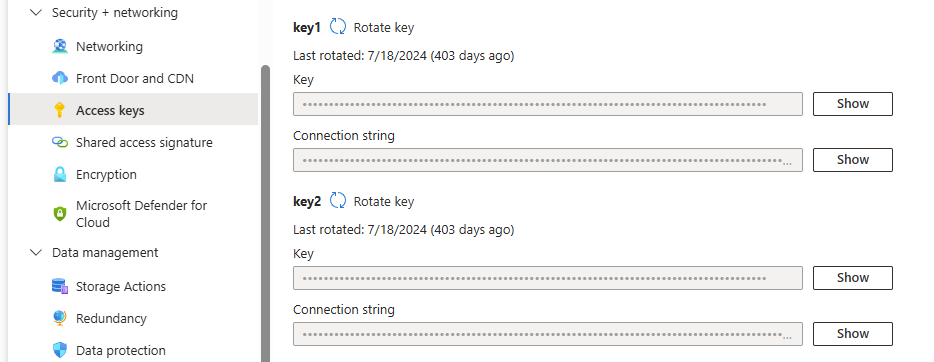
Se estiver usando os arquivos de definição JSON incluídos nos arquivos de personalização do agente de IA para gerar o índice e o indexador, você também precisará da chave da conta do Azure Blob Storage. Para visualizar as chaves de acesso da conta:
- No portal do Azure, navegue até Contas de armazenamento e abra a conta de armazenamento específica.
- No menu de recursos sob Segurança + rede, selecione Chaves de acesso.
-
Clique em Mostrar chaves para revelar a chave de acesso a ser usada durante a configuração do Azure AI Search.
Serviço Azure AI Search
Você deve criar um serviço Azure AI Search e configurar seu índice e indexador para processar os dados do contêiner Blob.
Você precisará da URL e da chave da API do serviço Azure AI Search para determinar os valores das variáveis do projeto Azure AI Search:
- URL: Para obter o valor a ser usado para
azure_ai_search_url, consulte a documentação do Azure Obter informações do serviço. - Chave da API: Para obter o valor a ser usado para
azure_ai_search_api_key, consulte a documentação do Azure Configurar acesso baseado em função.
Você pode usar os arquivos de definição JSON incluídos nos arquivos de personalização do agente de IA para gerar o índice e o indexador, ou pode criá-los você mesmo.
Se você estiver usando os arquivos de definição fornecidos, deve substituir os seguintes espaços reservados pelos seus próprios valores de configuração:
Azure_AI_Search_Indexer_Definition.json
| Espaço Reservado | Descrição |
|---|---|
{{Seu Nome do Serviço de Pesquisa Azure AI}} |
O nome do serviço de pesquisa Azure AI. |
Azure_AI_Search_Datasource_Definition.json
| Espaço Reservado | Descrição |
|---|---|
{{Seu Nome do Serviço de Pesquisa Azure AI}} |
O nome do serviço de pesquisa Azure AI. |
{{Seu Nome da Conta de Blob Azure}} |
O nome da conta de Blob Azure. |
{{Sua Chave de Conta de Blob Azure}} |
A chave de acesso para a conta de Armazenamento Blob Azure, obtida conforme descrito em contêiner Blob Azure acima. |
{{seu_nome_do_contêiner_blob_azure}} |
O nome do contêiner Blob Azure. |
Recurso Azure OpenAI
Você deve criar um recurso Azure OpenAI e implantar um modelo gpt-4o ou gpt-4.1 através do portal Azure AI Foundry.
Você precisará do nome da implantação, da URL do endpoint Azure OpenAI e da chave da API para determinar os valores das variáveis do projeto Azure OpenAI. Para encontrar esses valores:
- No portal Azure AI Foundry, abra o recurso OpenAI específico.
-
Os valores a serem usados para a URL do endpoint (
azure_openai_base_url) e a chave da API (azure_openai_api_key) são exibidos na página inicial do recurso: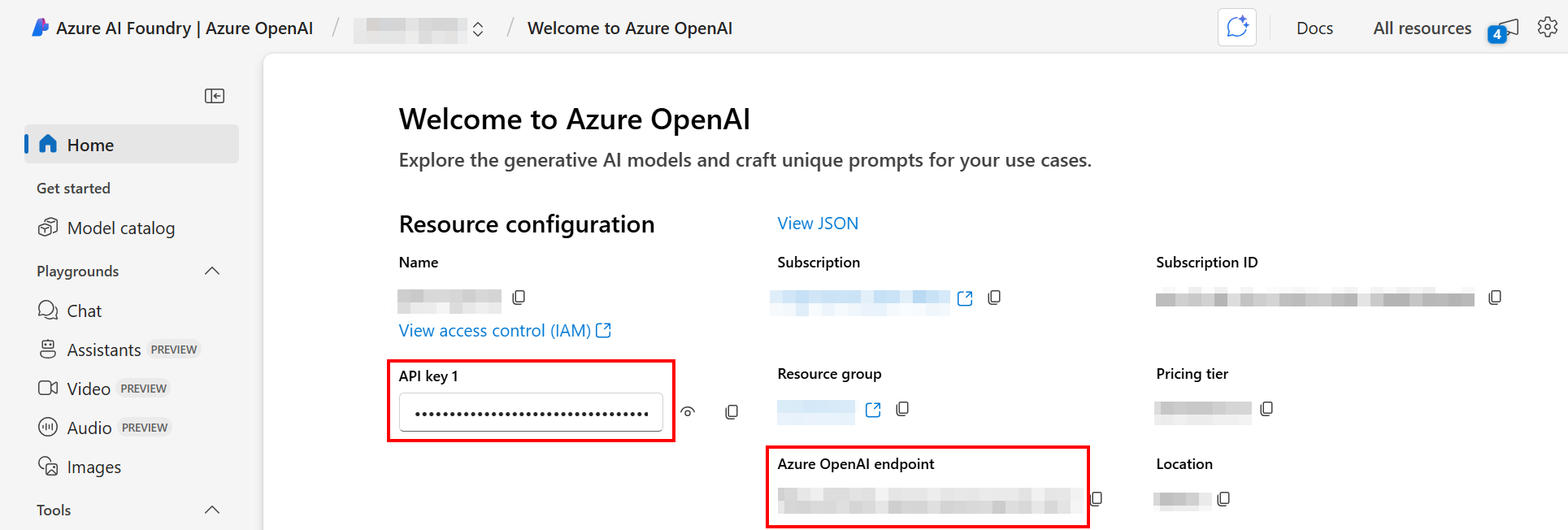
-
No menu de navegação sob Recursos compartilhados, selecione Implantações. O nome da implantação (
Azure_OpenAI_Deployment_Name) é exibido.
Criar o aplicativo Slack
Para criar a interface de chat do Knowledge Agent no Slack, siga estas etapas:
-
Crie um aplicativo Slack usando o arquivo de manifesto do aplicativo Slack (
slack_app_manifest.json) fornecido com os arquivos de personalização deste agente de IA. Alternativamente, crie o aplicativo do zero. -
Se você usar o arquivo de manifesto fornecido, substitua os seguintes espaços reservados pelos seus próprios valores de configuração:
Espaço reservado Descrição {{Substitua pelo nome do bot Slack}}O nome que você deseja que seu bot Slack tenha, conforme exibido para os usuários. Substitua este valor em dois lugares no manifesto. {{Substitua pela URL da API Jitterbit}}A URL do serviço da API personalizada Jitterbit que você criou em Criar a API personalizada Jitterbit. -
Instale o aplicativo no seu espaço de trabalho Slack.
-
Obtenha o token do bot (para o campo Token OAuth do Usuário do Bot da conexão Slack) e insira seu valor na variável de projeto
slack_bot_oauth_user_token. -
Configure a variável de projeto
slack_channel_namecom o canal onde as notificações devem ser enviadas. -
Insira o valor do token do bot na variável de projeto
slack_bot_oauth_user_tokene o nome do canal na variável de projetoslack_channel_name. Você configurará esses valores na próxima etapa.
Configurar uma conta de serviço do Google e um drive compartilhado
Essa configuração é necessária apenas se você estiver usando o fluxo de trabalho Data upload Utility - Google Drive to Azure Blob. É necessário ter um projeto ativo no Google Cloud para prosseguir. Se você não tiver um, pode criar um seguindo as instruções do Google.
Criar uma conta de serviço do Google
Siga os passos abaixo para criar uma chave para a conta de serviço do Google, permitindo que a ferramenta acesse seus arquivos do Google Drive de forma segura:
-
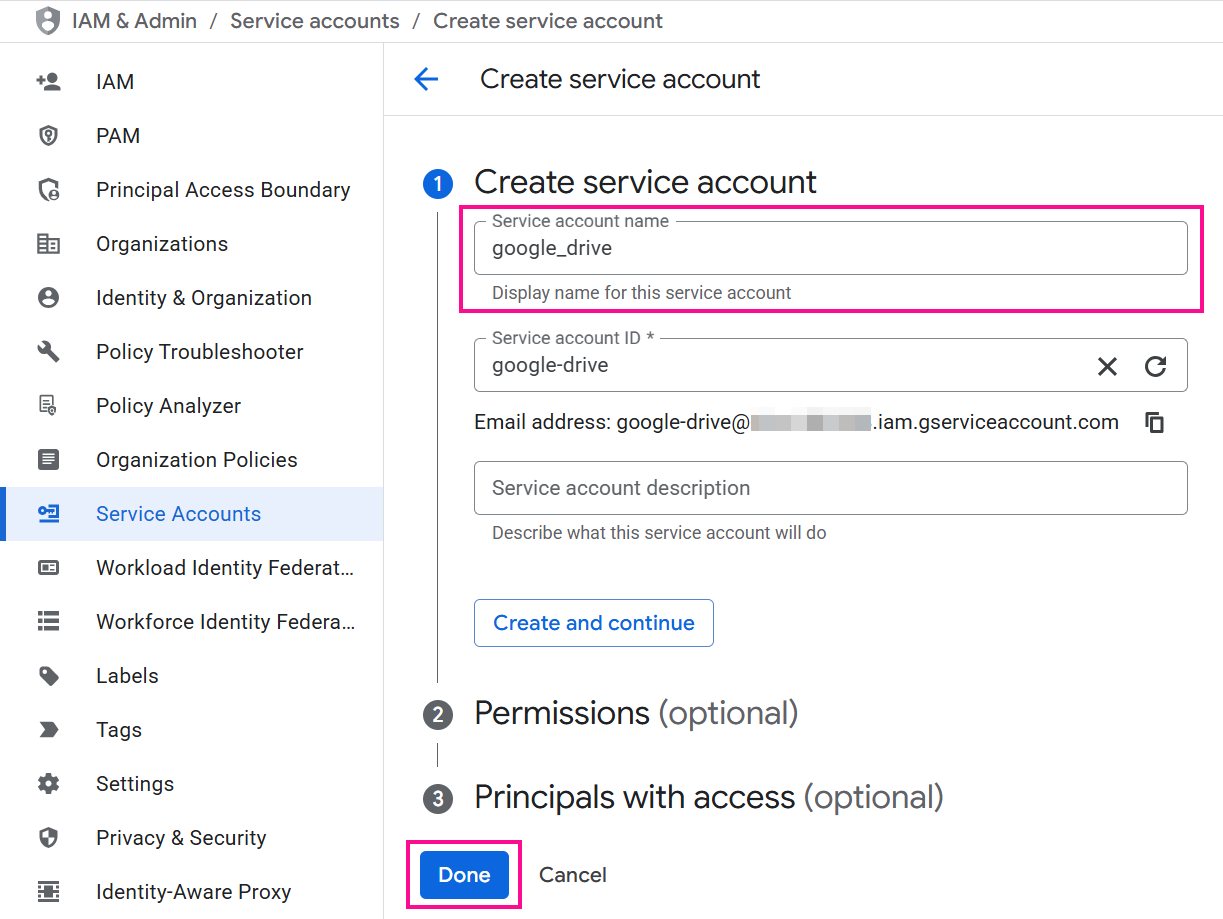
No console do Google Cloud, use a barra de pesquisa para encontrar e navegar até a página Contas de Serviço.
-
Se você já tiver uma conta de serviço que deseja usar, prossiga para o passo 3. Caso contrário, clique em Criar conta de serviço, forneça um nome e clique em Concluído. Nenhuma permissão ou acesso adicional é necessário.
-
Selecione a conta de serviço para abrir os Detalhes da conta de serviço:
-
Navegue até a aba Chaves e use o menu Adicionar chave para selecionar Criar nova chave.
-
Escolha JSON como o tipo de chave e clique em Criar. Um arquivo JSON contendo as credenciais será baixado para o seu computador.
-
Abra o arquivo JSON baixado para encontrar os seguintes valores necessários para configurar as variáveis do projeto Google Drive:
client_email: Este é o valor para a variável de projetoGoogle_Client_Emaile necessário para configurar o drive compartilhado do Google na próxima seção.private_key: Este é o valor para a variável de projetoGoogle_Private_Key.
-
Ative a API do Google Drive na sua conta do Google Cloud:
-
No console do Google Cloud, use a barra de pesquisa para encontrar e navegar até a página APIs e Serviços.
-
Acesse a Biblioteca de APIs e selecione a API do Google Drive:
-
Clique no botão Ativar:

-
Configurar a unidade compartilhada do Google
A unidade compartilhada do Google deve ser configurada da seguinte forma para permitir que a utilidade acesse quaisquer arquivos que você enviar para ela:
-
Crie uma unidade compartilhada do Google se você ainda não tiver uma.
-
Abra a unidade compartilhada e copie seu ID da URL do navegador. O ID é a longa sequência de caracteres no final. Por exemplo, se a URL for
https://drive.google.com/drive/folders/dftg-LbGrP7hdfd, o ID édftg-LbGrP7hdfd. Este ID é o valor da variável de projetoGoogle_Drive_IDao configurar variáveis de projeto do Google Drive. -
Clique no nome da unidade compartilhada na parte superior da página e selecione Gerenciar membros. Um diálogo aparece.
-
No campo Adicionar pessoas e grupos, cole o valor do
client_emaildo arquivo JSON que você baixou anteriormente. -
Atribua o papel de Gerente de conteúdo à conta de serviço e confirme a ação.
Configurar variáveis de projeto
No projeto do Studio instalado anteriormente via Marketplace, você deve definir valores para as seguintes variáveis de projeto.
Isso pode ser feito usando o menu de ações do projeto para selecionar Variáveis de Projeto e abrir uma gaveta na parte inferior da página onde você pode revisar e definir os valores.
Salesforce
| Nome da variável | Descrição |
|---|---|
SF_Login_URL |
Host do Servidor na conexão do Salesforce |
SF_Password |
Senha na conexão do Salesforce |
SF_Security_Token |
Token de segurança na conexão do Salesforce |
SF_User_Name |
Nome de usuário na conexão do Salesforce |
SF_Cases_Incremental_Run |
Flag para controlar se deve buscar apenas casos novos ou atualizados do Salesforce desde a última execução. Quando true, apenas casos incrementais (novos ou atualizados) são buscados do Salesforce desde a última execução. Quando false, uma busca completa é realizada a partir da data e hora padrão (SF_Cases_Default_Modified_Date). |
SF_Cases_Default_Modified_Date |
A data e hora padrão a partir da qual os casos do Salesforce são buscados. Usado durante a primeira execução ou quando SF_Cases_Incremental_Run é false. Formato: yyyy-MM-dd'T'HH:mm:ss.SSS'Z'. Exemplo: 2024-09-11T13:00:02.000Z. Se esta data não for definida, um erro será gerado. |
Jira
| Nome da variável | Descrição |
|---|---|
JIRA_Username |
O endereço de email associado à conta Jira para autenticação. |
JIRA_Token |
Token da API usado para autenticação com a instância JIRA. Para o Atlassian Cloud, você pode gerar esse token nas configurações da sua conta. |
JIRA_Projects |
Chaves de projetos Jira para buscar problemas, usando o formato keys=PROJECT1&keys=PROJECT2. Exemplo: keys=SUPPORT&keys=ITHELP. |
JIRA_Issue_Types |
Lista de tipos de problemas Jira a serem buscados, separados por vírgulas. Cada valor deve estar entre aspas simples. Exemplo: 'Story','Bug','Task'. |
Jira_Default_Modified_Date |
A data e hora padrão a partir da qual os problemas Jira são buscados. Usado durante a primeira execução ou quando JIRA_IncrementalRun é false. Formato: yyyy-MM-dd HH:mm. Exemplo: 2025-08-07 10:00. Se essa data não estiver definida, um erro será gerado. |
JIRA_Incremental_Run |
Flag para controlar se apenas novos ou problemas Jira atualizados devem ser buscados desde a última execução. Quando true, apenas problemas incrementais (novos ou atualizados) são buscados do Jira desde a última execução. Quando false, uma busca completa é realizada a partir da data e hora padrão (Jira_Default_Modified_Date). |
JIRA_Base_URL |
A URL base da instância Jira à qual se conectar. Não inclua uma barra no final. Exemplo: https://yourdomain.atlassian.net. |
Confluence
| Nome da variável | Descrição |
|---|---|
Confluence_Wiki_UserName |
O nome de usuário do wiki Confluence. |
Confluence_Wiki_Password |
A senha do wiki Confluence. |
Confluence_Wiki_Base_Url |
A URL raiz do wiki Confluence para chamadas de API e recuperação de conteúdo. Exemplo: https://yourcompany.atlassian.net/wiki. |
Google Drive
| Nome da variável | Descrição |
|---|---|
Google_Client_Email |
O email do cliente da conta de serviço do Google usado para autenticação ao acessar o Google Drive. |
Google_Drive_Default_Modified_Date |
A data e hora padrão a partir da qual os arquivos do Google Drive são lidos. Usado durante a primeira execução ou quando a leitura incremental está desativada. Formato: yyyy-MM-dd'T'HH:mm:ss. Exemplo: 2024-05-28T11:32:47. Se esta data não estiver definida, um erro será gerado. |
Google_Drive_ID |
O ID do Google Drive compartilhado do qual os arquivos serão lidos. Por exemplo, se a URL do drive compartilhado for https://drive.google.com/drive/folders/1KTXaKx_FG7Ud8sWHf8QgG67XHy, o ID do drive é 1KTXaKx_FG7Ud8sWHf8QgG67XHy. |
Google_Drive_Incremental_Run |
Flag para controlar se apenas novos arquivos ou arquivos atualizados do Google Drive devem ser buscados desde a última execução. Quando true, apenas arquivos incrementais (novos ou atualizados) são buscados do Google Drive desde a última execução. Quando false, uma busca completa é realizada a partir da data e hora padrão (Google_Drive_Default_Modified_Date). |
Google_Oauth_Scopes |
O escopo OAuth necessário para conceder à conta de serviço do Google acesso ao Google Drive. Para este agente de IA, insira: https://www.googleapis.com/auth/. |
Google_Private_Key |
A chave privada da conta de serviço do Google Cloud usada para autenticar a busca de arquivos do Google Drive. |
Armazenamento de Blob do Azure
| Nome da variável | Descrição |
|---|---|
Azure_Blob_Container_Name |
O nome do contêiner de Armazenamento de Blob do Azure onde os dados recuperados são armazenados ou de onde são recuperados. Esta é a parte da URL SAS imediatamente após o domínio da conta de armazenamento. Exemplo: Em https://myaccount.blob.core.windows.net/mycontainer/myblob.txt?sv=..., o nome do contêiner é mycontainer. |
azure_blob_sas_token |
O token SAS usado para autenticar o acesso ao contêiner de Blob do Azure Azure_Blob_Container_Name. Apenas a parte após ? na URL completa do blob deve ser armazenada. Exemplo de token: sv=2025-08-01&ss=b&srt=sco&sp=rl&se=2025-08-30T12:00:00Z&st=2025-08-25T12:00:00Z&spr=https&sig=AbCdEfGhIjKlMnOpQrStUvWxYz1234567890. |
azure_blob_base_url |
A URL base da conta de Armazenamento de Blob do Azure usada para acessar contêineres e blobs. Em uma URL SAS como https://myaccount.blob.core.windows.net/mycontainer/myblob.txt?sv=..., a URL base é https://myaccount.blob.core.windows.net/. |
Dica
Esses valores podem ser derivados da URL SAS, que está no formato de {{azure_blob_base_url}}/{{Azure_Blob_Container_Name}}?{{azure_blob_sas_token}}.
Pesquisa AI do Azure
| Nome da variável | Descrição |
|---|---|
Azure_AI_Search_Index_Name |
O nome do índice do Azure que armazena informações dos clientes a partir de formulários de pedido. |
azure_ai_search_indexer |
O nome do indexador de Pesquisa AI do Azure usado para preencher e atualizar o índice de pesquisa Azure_AI_Search_Index_Name. |
azure_ai_search_url |
A URL do endpoint do seu serviço de Pesquisa AI do Azure. Não inclua uma barra no final. Exemplo: https://<seu-serviço-de-pesquisa>.search.windows.net. |
azure_ai_search_api_key |
A chave da API usada para autenticar solicitações à Pesquisa AI do Azure. |
Azure OpenAI
| Nome da variável | Descrição |
|---|---|
Azure_OpenAI_Deployment_Name |
O nome da implantação do Azure OpenAI usada para acessar o modelo. |
azure_openai_base_url |
A URL base para acessar o serviço Azure OpenAI. Exemplo: https://<seu-nome-de-recurso>.openai.azure.com. |
azure_openai_api_key |
A chave da API usada para autenticar solicitações ao serviço Azure OpenAI. |
Slack
| Nome da variável | Descrição |
|---|---|
Slack_Bot_Token |
O token do bot do Slack que é obtido após criar o aplicativo Slack, usado para o token de acesso OAuth do usuário Bot na conexão do Slack. |
Nota
O aplicativo Slack é criado em uma etapa posterior. Por enquanto, você pode deixar esta variável em branco.
Comum
| Nome da variável | Descrição |
|---|---|
html_regex |
Regex para remover tags HTML. Use o valor padrão: <(?:"[^"]*"['"]*|'[^']*'['"]*|[^'">])+> |
AI_Prompt |
O texto de entrada ou instrução fornecida ao modelo de IA que orienta como ele deve gerar uma resposta. Para este agente, você pode usar o seguinte prompt:
|
Testar conexões
Testar as configurações de endpoint para verificar a conectividade usando os valores de variáveis de projeto definidos.
Para testar conexões, vá para a aba Endpoints e conectores do projeto no painel de componentes de design, passe o mouse sobre cada endpoint e clique em Testar.
Implantar o projeto
Implantar o projeto do Studio.
Para implantar o projeto, use o menu de ações do projeto para selecionar Implantar.
Implantar o projeto
Implantar o projeto do Studio. Isso pode ser feito usando o menu de ações do projeto para selecionar Implantar.
Criar a API personalizada do Jitterbit
Criar uma API personalizada usando o API Manager para um dos seguintes:
- Manipulador de solicitações da API do bot Slack: Necessário se estiver usando a notificação do Slack incluída no design deste agente de IA.
- Manipulador de solicitações da API genérica: Opcional. Use para manipular solicitações de API de qualquer aplicativo.
Criar o manipulador de solicitações da API do bot Slack
Esta API personalizada do Jitterbit acionará a operação Manipulador de Solicitações da API do Bot Slack. Configure e publique a API personalizada com as seguintes configurações:
- Serviço da API:
Manipulador de Solicitações da API do Bot Slack - Caminho:
/ - Projeto: Selecione o projeto do Studio criado a partir do
Agente de Conhecimento Jitterbitno Marketplace - Operação a Acionar:
Manipulador de Solicitações da API do Bot Slack - Método:
POST - Tipo de Resposta:
Variável do Sistema
Mantenha a URL do serviço da API publicada para uso na criação do aplicativo Slack. A URL do serviço pode ser encontrada na gaveta de detalhes da API na aba Serviços, passando o mouse sobre a coluna Ações do serviço e clicando em Copiar URL do serviço da API.
Manipulador de requisições API genérico
Esta API personalizada do Jitterbit acionará a operação Manipulador de requisições API genérico. Não é obrigatório. Crie esta API se você estiver usando outros aplicativos para processar requisições HTTP API. Configure e publique a API personalizada com as seguintes configurações:
- Nome do serviço:
Manipulador de requisições API genérico - Projeto: Selecione o projeto do Studio criado a partir do
Agente de Conhecimento Jitterbitno Marketplace - Operação:
Manipulador de requisições API genérico - Método:
POST - Tipo de resposta:
Variável do Sistema
Dica
Você também pode adicionar um perfil de segurança para autenticação.
{
"username": "johnr",
"prompt": "How to connect to mysql using a connector?"
}
{
"message": "To connect to a MySQL database using the Database connector, follow these steps: - Use the MySQL JDBC driver that ships with the agent for additional features like manual queries.",
"references": [],
"status_code": 200
}
Revisar fluxos de trabalho do projeto
No projeto do Studio aberto, revise os fluxos de trabalho juntamente com as descrições abaixo para entender o que eles fazem.
Nota
Os primeiros quatro fluxos de trabalho são fluxos de trabalho do Utilitário de upload de dados cujo objetivo é buscar dados a serem usados como a base de conhecimento para o agente de IA. Você pode usar qualquer um ou todos esses fluxos de trabalho para buscar dados. Pelo menos uma fonte é necessária como a base de conhecimento para o agente de IA.
Esses fluxos de trabalho devem ser executados primeiro para carregar conhecimento no agente antes de interagir com ele. Você pode configurar um cronograma para obter dados atualizados regularmente conforme suas necessidades. Isso pode ser feito a partir do menu de ações da primeira operação em Configurações > Cronogramas.
-
Utilitário de upload de dados - Ticket JIRA para Índice Azure
Este fluxo de trabalho busca problemas do Jira, em seguida, executa o fluxo de trabalho
Utilitário - Upload de Dados Azure e Índicepara fazer upload dos problemas para o Azure Blob Storage e indexá-los no índice de pesquisa de IA do Azure.A operação inicial é
Principal - upload de tickets JIRA. Os seguintes campos são buscados:"fields": [ "summary", "status", "assignee", "description", "reporter", "created", "updated", "priority", "issuetype", "components", "comment" ]Este fluxo de trabalho pode ser configurado para buscar todos os problemas, ou apenas problemas novos e atualizados, usando as variáveis do projeto Jira.
-
Utilitário de Upload de Dados - Casos do SF para Índice do Azure
Este fluxo de trabalho recupera casos de suporte do Salesforce e, em seguida, executa o fluxo de trabalho
Utility - Azure Data Upload and Indexpara fazer o upload dos casos para o Azure Blob Storage e indexá-los no índice de pesquisa do Azure AI.A operação inicial é
Main - SF Cases Upload.Na configuração da atividade de consulta do Salesforce, a seguinte consulta recupera informações de casos de suporte por agente. Se sua organização Salesforce não usar esses objetos e campos, ou se as informações dos casos de suporte estiverem armazenadas em objetos e campos diferentes, este fluxo de trabalho não funcionará corretamente. Personalize a consulta neste fluxo de trabalho para alinhar-se ao modelo de dados da sua organização Salesforce:
SELECT Account.Name, Owner.Email, Owner.Name, (SELECT CreatedBy.Email, CreatedBy.Name, Id, CommentBody, CreatedDate, LastModifiedDate, LastModifiedBy.Email, LastModifiedBy.Name FROM CaseComments), Id, CaseNumber, CreatedDate, Description, LastModifiedDate, Origin, Priority, Reason, Status, Subject, Type, CreatedBy.Email, CreatedBy.Name, LastModifiedBy.Email, LastModifiedBy.Name FROM CaseEste fluxo de trabalho pode ser configurado para buscar todos os casos ou apenas casos novos e atualizados, usando as variáveis de projeto do Salesforce.
-
Utilitário de Upload de Dados - Páginas do Confluence para Índice do Azure
Este fluxo de trabalho recupera páginas do Confluence e, em seguida, executa o fluxo de trabalho
Utility - Azure Data Upload and Indexpara fazer o upload de documentos para o Azure Blob Storage e indexá-los no índice de pesquisa do Azure AI.A operação inicial é
Main - Load Confluence Pages.Este fluxo de trabalho busca todas as páginas do Confluence em cada execução.
-
Utilitário de Upload de Dados - Google Drive para Azure Blob
Este fluxo de trabalho recupera arquivos do Google Drive e, em seguida, executa o fluxo de trabalho
Utility - Azure Data Upload and Indexpara indexá-los no índice de pesquisa do Azure AI.A operação inicial é
Main - Google Drive Upload.Os tipos de arquivo suportados incluem Google Docs, Google Spreadsheets e aqueles suportados pela indexação de blobs do Azure Storage.
Os tamanhos máximos de arquivo suportados estão listados como o tamanho máximo de blob nos limites do Indexador do Azure AI Search para o seu nível de serviço de pesquisa AI. Por exemplo, para o nível básico, o limite é de 16 MB; para S1, o limite é de 128 MB.
Este fluxo de trabalho pode ser configurado para buscar todos os arquivos ou apenas arquivos novos e atualizados, usando as variáveis de projeto do Google Drive.
-
Utilitário - Upload de Dados para Azure e Indexação
Este é um fluxo de trabalho utilitário comum usado pelos fluxos de trabalho
Utilitário de upload de dadospara enviar dados para o Azure Blob Storage e indexá-los no Azure AI Search. -
Entrada Principal - Manipulador de Solicitações da API do Slack
Este fluxo de trabalho gerencia as solicitações de entrada do bot do Slack. Ele é acionado via uma API personalizada do Jitterbit cada vez que sua equipe interage com a interface de chat do bot do Slack (ou seja, envia uma mensagem para o Slack). A configuração da API personalizada do Jitterbit é descrita em Criar a API personalizada do Jitterbit mais adiante nesta página.
Se você não estiver usando o Slack, este fluxo de trabalho pode ser ignorado e não será acionado. Para usar uma interface de chat diferente para sua equipe interagir, utilize o fluxo de trabalho
Manipulador de Solicitações da API Genérica, também acionado via uma API personalizada do Jitterbit. -
Manipulador de Solicitações da API Genérica
Este fluxo de trabalho processa solicitações de API HTTP de qualquer aplicativo. Para integrar com seus aplicativos, crie uma API personalizada do Jitterbit que acione a operação
Manipulador de Solicitações da API Genérica. A URL dessa API pode então ser usada por qualquer aplicativo para enviar e receber solicitações.A configuração da API personalizada do Jitterbit é descrita em Criar a API personalizada do Jitterbit mais adiante nesta página.
Acionar os fluxos de trabalho do projeto
Para a carga inicial de dados, execute qualquer um ou todos os fluxos de trabalho Utilitário de upload de dados, dependendo de suas fontes de dados. Isso pode ser feito usando a opção Executar mostrada ao passar o mouse sobre a operação. Você precisará executar a operação novamente no futuro se seus dados forem atualizados.
Dica
Você pode querer colocar as operações iniciais nos fluxos de trabalho Utilitário de upload de dados em um cronograma para obter dados atualizados regularmente. Isso pode ser feito no menu de ações da operação em Configurações > Cronogramas.
Os dois outros principais fluxos de trabalho são acionados pelas APIs personalizadas do Jitterbit:
-
Main Entry - Slack API Request Handler: Este fluxo de trabalho é acionado a partir do Slack via a API personalizadaSlack Bot API Request Handler. Enviar uma mensagem direta para o aplicativo Slack iniciará o acionamento da API personalizada. -
Generic API Request Handler: Este fluxo de trabalho é acionado a partir de outro aplicativo via a API personalizadaGeneric API request Handler. Enviar uma solicitação para a API configurada iniciará o acionamento da API personalizada.
Todos os outros fluxos de trabalho são acionados por outras operações e estão a jusante dos listados acima. Eles não são destinados a serem executados sozinhos.
Solução de Problemas
Se você encontrar problemas, revise os seguintes logs para informações detalhadas de solução de problemas:
Para assistência adicional, entre em contato com o suporte do Jitterbit.