Conceitos-chave para transformações no Jitterbit Studio
Esta página explica os conceitos principais a serem compreendidos ao projetar transformações e solucionar problemas.
Esquemas
Um esquema define a estrutura e os tipos de dados dos seus dados de entrada ou saída. Os esquemas especificam quais campos estão disponíveis, seus tipos de dados e como os campos estão organizados:
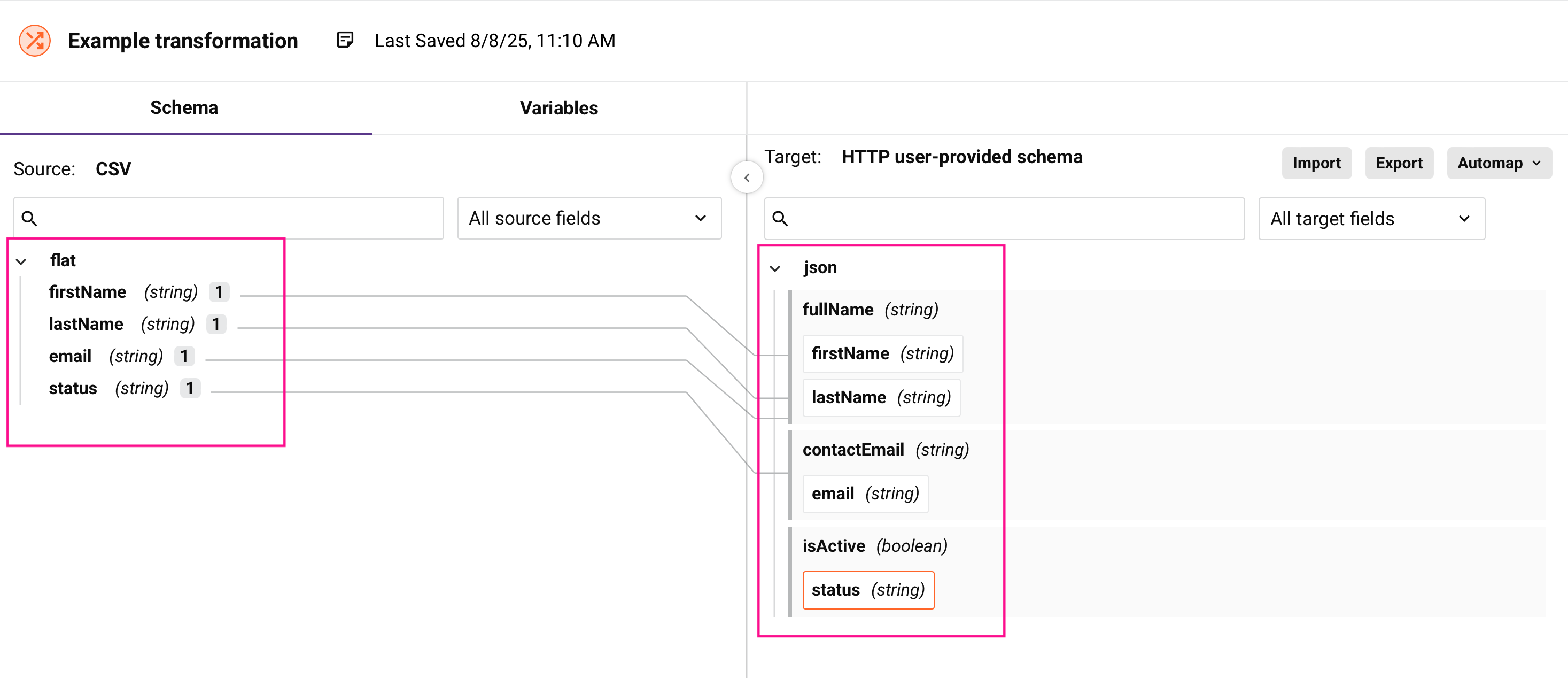
Esquemas de origem
O esquema de origem descreve a estrutura dos dados que entram na sua transformação. Os esquemas de origem podem vir dessas fontes:
-
Esquemas gerados por atividades: Criados automaticamente por atividades de conector, como consultas a bancos de dados ou chamadas de API.
-
Esquemas definidos pelo usuário: Esquemas personalizados que você cria ou faz upload.
Os esquemas de origem são opcionais. Você não precisa de um esquema de origem se estiver usando apenas variáveis, valores personalizados ou lógica scriptada em seus mapeamentos.
Para mais informações, veja Escolher fontes de esquema.
Esquemas de destino
O esquema de destino descreve a estrutura dos dados que saem da sua transformação. Assim como os esquemas de origem, os esquemas de destino podem ser gerados por atividades ou definidos pelo usuário.
Os esquemas de destino são sempre necessários. Toda transformação deve ter um esquema de destino que define a estrutura de saída.
Para orientações detalhadas sobre como criar e configurar esquemas, veja Criar uma transformação e configurar esquemas.
Estruturas de dados
As estruturas de dados definem como as informações estão organizadas dentro dos esquemas.
Estruturas planas
Estruturas planas contêm campos em um único nível, sem aninhamento. Exemplos incluem esses formatos:
- Arquivos CSV com colunas
- Tabelas de banco de dados únicas
- Arquivos XML simples sem elementos aninhados
Exemplo
<customer>
<id>10123</id>
<fullname>ABC Co.</fullname>
<street>1 Main St.</street>
<city>Anytown</city>
<state>NY</state>
<zip>12345</zip>
</customer>
Estruturas hierárquicas
Estruturas hierárquicas contêm relacionamentos aninhados entre campos e registros. Exemplos incluem esses formatos:
- Arquivos XML complexos com elementos aninhados
- Objetos JSON com propriedades aninhadas
- Junções de banco de dados em várias tabelas
Example
<customer>
<id>10123</id>
<name>ABC Co.</name>
<addresses>
<address>
<street>1 Main St.</street>
<city>Anytown</city>
<state>NY</state>
<zip>12345</zip>
</address>
<address>
<street>1 Time Square</street>
<city>New York City</city>
<state>NY</state>
<zip>54321</zip>
</address>
</addresses>
</customer>
Para mais informações sobre como trabalhar com estruturas de dados, veja Mapear dados.
Para cenários de dados hierárquicos complexos, veja Trabalhar com dados hierárquicos.
Nós e campos
Os esquemas são exibidos como estruturas em árvore contendo nós e campos. Nós são contêineres que organizam campos em estruturas hierárquicas. Campos contêm os valores de dados reais.
Cada nó e campo mostra esses indicadores visuais:

- Chave de cardinalidade: Mostra regras de ocorrência entre colchetes.
- Nome: O identificador do elemento do esquema
- Tipo de dado: Apenas para campos (string, inteiro, booleano, etc.)
-
Indicadores de atributo/valor: Algumas estruturas XML incluem símbolos adicionais:
Símbolo Significado @Dados de atributo do elemento, por exemplo @imagem#Dados de texto do elemento, por exemplo #texto
Nós
Nós são contêineres que organizam campos em estruturas hierárquicas:
- Caret: Expande e colapsa nós.
- Nomes em negrito: Indicam nós que contêm mapeamentos quando colapsados.
- Expansão padrão: 8 níveis de profundidade para esquemas com menos de 750 nós, 5 níveis de profundidade para esquemas maiores.
Você não pode mapear dados diretamente para nós. Em vez disso, você mapeia dados para os campos que os nós contêm.
Campos
Campos contêm os valores de dados reais e têm essas propriedades:
- Nome: O identificador do campo.
- Tipo de dado: O tipo de dado, como string, inteiro, booleano, data e outros.
- Formato: Formatação opcional para datas ou moeda.
-
Valores padrão: Quando um esquema XSD ou WSDL especifica um valor padrão para um elemento ou atributo, o valor aparece ao lado do nome do campo na interface de transformação:

Notação de cardinalidade
As chaves de cardinalidade indicam regras de ocorrência usando notação estilo UML:
| Chave de cardinalidade | Definição |
|---|---|
[1] |
Exatamente um elemento (obrigatório) |
[1+] |
Um ou mais elementos (obrigatório, repetível) |
[0,1] |
Zero ou um elemento (opcional) |
[0+] |
Zero ou mais elementos (opcional, repetível) |
Mapeamentos
Um mapeamento conecta dados de origem a campos de destino e define como os dados devem ser transformados.
Tipos de mapeamentos
-
Mapeamentos de campo direto: Conectam campos de origem diretamente a campos de destino. Veja Mapear campos manualmente.
-
Mapeamentos de valor personalizado: Atribuem valores ou expressões estáticas. Veja Usar valores personalizados.
-
Mapeamentos de variável: Referenciam variáveis de projeto ou globais. Veja Mapear variáveis.
-
Mapeamentos de script: Usam funções e lógica para transformar dados. Veja Mapeamento com scripts.
-
Lógica condicional: Aplicam lógica diferente com base em condições. Veja Lógica condicional.
Scripts de mapeamento
Todos os mapeamentos são implementados como scripts em campos de destino. Mesmo mapeamentos visuais como arrastar e soltar criam scripts subjacentes. Você pode editar esses scripts diretamente para transformações complexas.
Para mapeamento automático de estruturas semelhantes, veja Mapear estruturas idênticas.
Nós de loop
Nós de loop lidam com dados repetidos, como múltiplos registros ou arrays. Quando você mapeia campos dentro de nós de loop, a transformação processa cada iteração dos dados.
Geração automática de loops
Os nós de loop são gerados automaticamente quando você mapeia campos de dados de origem repetidos para estruturas de destino repetidas. Uma linha de iterador aparece, mostrando como a transformação irá percorrer os dados.
Definição manual de loops
Você pode definir manualmente os nós de loop quando a geração automática não corresponde às suas necessidades de processamento de dados. Isso é útil quando você tem múltiplos níveis de dados repetidos e precisa controlar qual nível conduz a iteração.
Para orientações abrangentes sobre como trabalhar com dados repetidos, consulte Controlar loops de dados.
Variáveis
As variáveis são projetadas para passar valores, configurações e pequenas quantidades de dados entre diferentes componentes na sua integração. As variáveis são úteis quando você precisa compartilhar informações como IDs de sessão, parâmetros de configuração ou valores calculados entre scripts, transformações e operações. Esses tipos de variáveis estão disponíveis para uso:
| Tipo | Escopo | Melhor para |
|---|---|---|
| Local | Script único | Cálculos e valores temporários |
| Global | Cadeia de operação | Passar dados entre operações |
| Project | Projeto inteiro | Configuração e credenciais |
| Jitterbit | Definido pelo sistema | Informações em tempo de execução |
Para exemplos e informações detalhadas sobre cada tipo de variável, consulte suas páginas de documentação individuais.
Para exemplos práticos de uso de variáveis em transformações, consulte Mapear variáveis.
Fluxo de dados
Os dados fluem através das transformações nesta sequência:
-
Entrada: Uma atividade de origem fornece dados que correspondem ao esquema de origem.
-
Processamento: Uma transformação aplica mapeamentos, funções e lógica de negócios.
-
Saída: Os dados transformados que correspondem ao esquema de destino vão para a atividade de destino.
Compreender este fluxo ajuda a projetar mapeamentos que manipulam dados corretamente e a solucionar problemas quando os dados não se transformam como esperado.
Para orientações sobre validação e solução de problemas, consulte Testar e validar transformações e Resolver conflitos e erros de mapeamento de transformação.