Opções de operação no Jitterbit Studio
Introdução
Configure as opções de operação para controlar timeouts, registro e processamento de dados. A maioria das operações funciona bem com as configurações padrão, mas você pode personalizá-las para necessidades específicas.
Acessar opções de operação
Você pode acessar a opção Configurações para operações a partir destes locais:
- A aba Workflows do painel do projeto (veja Menu de ações do componente na Aba Workflows do painel do projeto).
- A aba Componentes do painel do projeto (veja Menu de ações do componente na Aba Componentes do painel do projeto).
- A tela de design (veja Menu de ações do componente na Tela de design).
- A tela de design clicando duas vezes na operação (isso abre Configurações diretamente).
Após abrir a tela de configurações da operação, selecione a aba Opções:

Configurar opções de operação
As seções a seguir descrevem cada opção de operação:
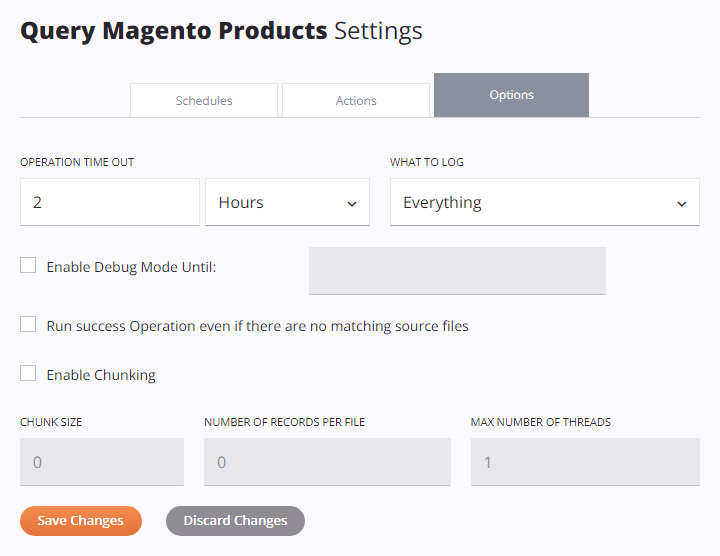
- Timeout da operação
- O que registrar
- Executar em agente dedicado
- Ativar Modo de Registro de Depuração Até
- Executar operação de sucesso mesmo que não haja arquivos de origem correspondentes
- Ativar Chunking
- Opções de operação em massa do Salesforce
Timeout da operação
Defina quanto tempo a operação deve ser executada antes de ser cancelada. O padrão é 2 horas, o que funciona para a maioria das operações.
Você pode querer ajustar essa configuração por estas razões:
-
Aumentar o tempo limite para conjuntos de dados grandes que levam mais tempo para processar. Operações agendadas que processam grandes volumes de dados podem precisar de tempos limites mais longos. Se seus conjuntos de dados excederem os limites de tempo limite, consulte Habilitar Chunking para opções que dividem grandes conjuntos de dados em lotes menores e controlam o número de registros gravados por arquivo de saída.
-
Diminuir o tempo limite para operações sensíveis ao tempo que devem ser concluídas rapidamente.
Digite um número e selecione Segundos, Minutos ou Horas no menu suspenso.
Nota
Operações acionadas por APIs do API Manager ignoram esta configuração em agentes em nuvem. Para agentes privados, habilite EnableAPITimeout no arquivo de configuração do agente privado para que a configuração de Tempo Limite da Operação se aplique a operações acionadas por APIs.
O que registrar
Escolha quais informações aparecem nos registros de operações:
- Tudo: Registra toda a atividade da operação (recomendado).
- Somente Erros: Registra apenas operações com status do tipo erro (como Erro, Falha SOAP ou Sucesso com Erro de Filho). Use esta configuração se você tiver problemas de desempenho e não precisar de registros detalhados. Operações de filho bem-sucedidas não são registradas. Operações pai (de nível raiz) são sempre registradas, pois requerem registro para funcionar corretamente.
Depuração
A seção Depuração inclui opções para executar uma operação em um agente dedicado e habilitar o modo de depuração.
Executar em agente dedicado
Direcione esta operação para ser executada em um agente específico como uma medida temporária de solução de problemas. Esta opção se aplica apenas a grupos de agentes privados configurados com uma classe de grupo de agentes de Alta Disponibilidade (HA). Use-a para reproduzir falhas em um agente específico ou para contornar um agente problemático enquanto mantém o restante do grupo operacional.
Para habilitar esta opção, selecione a caixa de seleção Executar em agente dedicado, e então configure o seguinte:
-
Selecionar um agente: Selecione o agente específico dentro do grupo HA a ser usado para a execução desta operação. Se o agente que você selecionar for excluído enquanto esta opção estiver ativa, a execução em agente dedicado será automaticamente desativada e a operação reverterá para a execução padrão do grupo de agentes.
-
Até: Selecione uma data até duas semanas a partir de hoje. A execução em agente dedicado será automaticamente desativada nesta data, e a operação reverterá para o comportamento padrão de execução do grupo de agentes.
-
Aplicar a operações filhas: Se a operação tiver operações filhas, esta caixa de seleção aparecerá. Selecione-a para direcionar todas as operações filhas a serem executadas no mesmo agente que a operação pai.
Quando Executar em agente dedicado está habilitado, um aviso aparece.
Diálogo
Executar esta operação em um único agente ignora sua configuração de Alta Disponibilidade (HA). Se este agente falhar ou atingir a capacidade, a operação ficará parada sem uma troca.
Habilitar Modo de Depuração Até
Ative o registro detalhado para solução de problemas. Selecione uma data até duas semanas a partir de hoje. O modo de depuração será automaticamente desativado nesta data.
Aviso
Em grupos de agentes na nuvem, a duração desta configuração é imprevisível. Os registros podem parar de ser gerados antes do final do período de tempo selecionado.
Quando você habilita o modo de depuração para operações com operações filhas, pode aplicar a mesma configuração a todas as operações filhas usando a caixa de seleção Também Aplicar a Operações Filhas.
O registro de depuração gera diferentes tipos de registros com base no tipo de agente:
| Tipo de log | Descrição do log | Tipo de agente |
|---|---|---|
| Arquivos de log de depuração | Arquivos de log de depuração para solução de problemas detalhada. Você pode acessar esses arquivos diretamente no agente ou baixá-los através do Console de Gerenciamento. O registro de depuração também pode ser ativado para todo o projeto a partir do próprio agente privado (veja Registro de depuração de operação). Os arquivos de log de depuração são acessíveis diretamente em agentes privados e podem ser baixados através das páginas do Console de Gerenciamento Agentes e Runtime. Aviso O modo de depuração cria arquivos de log grandes. Use apenas durante os testes, não em produção. |
Apenas agentes privados |
| Entrada e saída de componentes | Dados de solicitação e resposta (mantidos por 30 dias). Acessados através da página Runtime do Console de Gerenciamento. Cuidado Os dados de entrada e saída do componente sempre são registrados na nuvem Harmony, mesmo que o registro na nuvem esteja desativado. Para parar isso em agentes privados, defina Os registros de depuração contêm todos os dados de solicitação e resposta, incluindo informações sensíveis como senhas e informações pessoalmente identificáveis (PII). Esses dados aparecem em texto claro nos registros da nuvem Harmony por 30 dias. |
Agentes em nuvem e privados |
| Logs de operações de API | Logs para operações de API bem-sucedidas (configurados para APIs personalizadas ou APIs OData). Por padrão, apenas operações de API com erros são registradas nos logs de operação. |
Agentes em nuvem e privados |
Executar operação de sucesso mesmo que não haja arquivos de origem correspondentes
Esta opção força uma operação a ter sucesso mesmo quando seu gatilho falha. Isso permite que outras operações acionadas para serem executadas Em Caso de Sucesso desta operação sejam executadas independentemente do resultado da operação inicial. Aplica-se apenas quando a operação inicial contém uma atividade de origem para um destes conectores:
- API
- Compartilhamento de Arquivos
- FTP
- HTTP
- Armazenamento Local
- SOAP
- Armazenamento Temporário
- Atividade de Variável
Por padrão, qualquer operação Em Caso de Sucesso é executada apenas se houver um arquivo de origem correspondente para processar. Esta opção pode ser útil para configurar partes posteriores de um projeto sem exigir o sucesso de uma operação dependente.
Nota
A configuração AlwaysRunSuccessOperation no arquivo de configuração do agente privado substitui esta opção.
Habilitar Chunking
Chunking divide grandes conjuntos de dados em partes menores (lotes). Isso torna o processamento mais rápido e ajuda a atender aos limites de registros da API. Para habilitar o chunking, sua operação deve conter uma transformação ou uma atividade de um destes conectores:
Nota
O particionamento não é suportado quando a fonte é um conector baseado em Connector SDK (mostrado como SDK na coluna Tipo de conector da lista de Conectores). Se sua fonte for baseada em SDK, divida a operação em duas: use uma atividade Write Variable como o alvo da primeira operação, depois use uma atividade Read Variable como a fonte na segunda operação com o particionamento habilitado.
Use o particionamento nessas situações:
- Você processa grandes conjuntos de dados com milhares de registros.
- Você usa serviços web com limites de registro. Por exemplo, o Salesforce permite apenas 200 registros por chamada.
- Você deseja usar múltiplos núcleos de CPU para processamento paralelo.
Dica
Para orientações sobre quando usar processamento em lote versus processamento orientado a eventos em projetos de integração, veja Processamento em lote e orientado a eventos.
Quando uma atividade de Salesforce, Salesforce Service Cloud ou ServiceMax está na operação, o particionamento é habilitado automaticamente.
Quando essa configuração está habilitada, configure os seguintes campos:
-
Tamanho do Chunk: O número de registros em cada chunk. O padrão é
1para a maioria das operações e200para operações do Salesforce.Nota
Quando você usa uma atividade em massa (Salesforce, Salesforce Service Cloud ou ServiceMax), altere esse padrão para um número muito maior, como
10.000. -
Número de Registros por Arquivo: O número de registros a serem gravados em cada arquivo de destino (lote). O padrão é
0, o que significa sem limite. -
Número Máximo de Threads: O número de threads de processamento que são executadas ao mesmo tempo. O padrão é
1para a maioria das operações e2para operações do Salesforce.
Aviso
O particionamento afeta como as variáveis globais e de projeto funcionam. Apenas as alterações da primeira thread são preservadas. Veja informações detalhadas sobre particionamento abaixo.
Opções de operação em massa do Salesforce
As seguintes opções aparecem apenas para operações em massa do Salesforce, Salesforce Service Cloud e ServiceMax (exceto operações de Bulk Query):
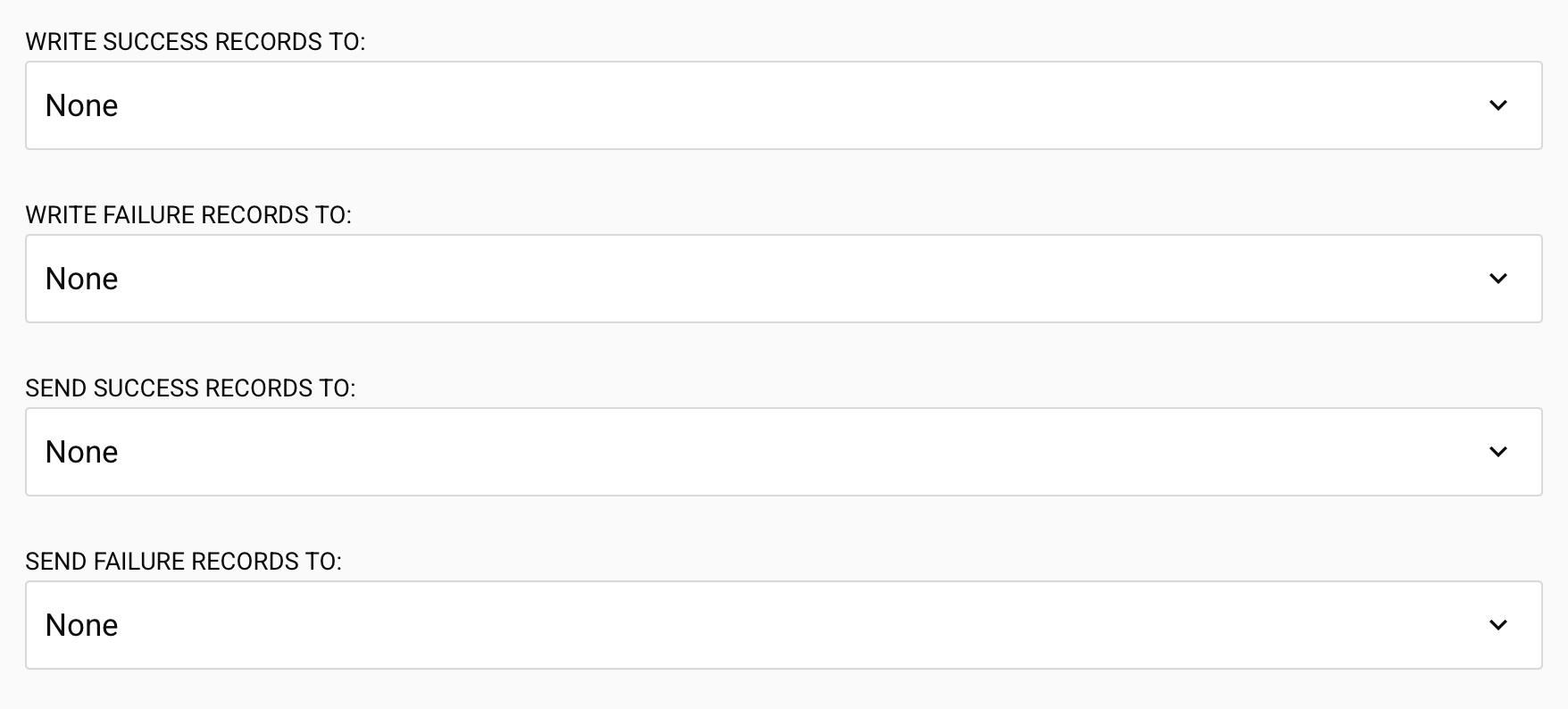
-
Gravar registros de sucesso em: Escolha onde enviar os registros bem-sucedidos após a conclusão da operação em massa. Selecione entre as atividades baseadas em arquivo configuradas: HTTP, API, FTP, File Share, Armazenamento Local, Armazenamento Temporário, ou Variável. Padrão: Nenhum.
-
Gravar registros de falha em: Escolha onde enviar os registros que falharam após a conclusão da operação em massa. HTTP, API, FTP, File Share, Armazenamento Local, Armazenamento Temporário, ou Variável. Padrão: Nenhum.
Importante
Quando você usa atividades de Variável, apenas operações na mesma cadeia de operação podem acessar o valor da variável durante a execução.
-
Enviar registros de sucesso para: Escolha uma notificação por email para receber registros bem-sucedidos. Selecione entre as notificações por email configuradas. Padrão: Nenhum.
-
Enviar registros de falha para: Escolha uma notificação por email para receber registros com falha. Selecione entre as notificações por email configuradas. Padrão: Nenhum.
Nota
Atividades baseadas em arquivo e notificações por email selecionadas nessas opções não precisam fazer parte de uma operação implantada existente. O Studio implantará e gerenciará automaticamente esses componentes quando selecionados.
Informações detalhadas sobre chunking
Chunking é usado para dividir os dados de origem em vários chunks (lotes) com base no tamanho de chunk configurado. O tamanho do chunk é o número de registros de origem (nós) para cada chunk. A transformação é então realizada em cada chunk separadamente, com cada chunk de origem produzindo um chunk de destino. Os chunks de destino resultantes se combinam para produzir o destino final.
Chunking pode ser usado apenas se os registros forem independentes e de uma fonte não-LDAP. Recomendamos usar um tamanho de chunk o maior possível, garantindo que os dados de um chunk caibam na memória disponível. Para métodos adicionais para limitar a quantidade de memória que uma transformação utiliza, veja Processamento de transformação.
Aviso
O uso de chunking afeta o comportamento de variáveis globais e de projeto. Veja Usar variáveis com chunking abaixo.
Limitações da API
Muitas APIs de serviços web (SOAP/REST) têm limitações de tamanho. Por exemplo, um upsert baseado em Salesforce aceita apenas 200 registros para cada chamada. Com memória suficiente, você poderia configurar uma operação para usar um tamanho de chunk de 200. A fonte seria dividida em chunks de 200 registros cada, e cada transformação chamaria o serviço web uma vez com um chunk de 200 registros. Isso seria repetido até que todos os registros tenham sido processados. Os arquivos de destino resultantes seriam então combinados. (Observe que você também poderia usar atividades em massa baseadas em Salesforce para evitar o uso de chunking.)
Processamento paralelo
Se você tiver uma fonte grande e um computador com múltiplos CPUs, o particionamento pode ser usado para dividir a fonte para processamento paralelo. Como cada parte é processada de forma isolada, várias partes podem ser processadas em paralelo. Isso se aplica apenas se os registros da fonte forem independentes entre si no nível do nó de partição. Serviços da web podem ser chamados em paralelo usando particionamento, melhorando o desempenho.
Ao usar particionamento em uma operação onde o destino é um banco de dados, observe que os dados de destino são primeiro gravados em vários arquivos temporários (um para cada parte). Esses arquivos são então combinados em um único arquivo de destino, que é enviado ao banco de dados para inserção/atualização. Se você definir a variável Jitterbit jitterbit.target.db.commit_chunks como 1 ou true quando o particionamento estiver habilitado, cada parte será, em vez disso, confirmada no banco de dados à medida que se torna disponível. Isso pode melhorar significativamente o desempenho, pois as inserções/atualizações no banco de dados são realizadas em paralelo.
Use variáveis com particionamento
Como o particionamento pode invocar multi-threading, seu uso pode afetar o comportamento de variáveis que não são compartilhadas entre as threads.
Variáveis globais e variáveis de projeto são segregadas entre as instâncias de particionamento, e embora os dados sejam combinados, as alterações a essas variáveis não são. Apenas as alterações feitas na thread inicial são preservadas ao final da transformação.
Por exemplo, se uma operação — com particionamento e múltiplas threads — tiver uma transformação que altera uma variável global, o valor da variável global após o término da operação é aquele da primeira thread. Quaisquer alterações à variável em outras threads são independentes e são descartadas quando a operação é concluída.
Essas variáveis globais são passadas para as outras threads por valor, em vez de por referência, garantindo que quaisquer alterações às variáveis não sejam refletidas em outras threads ou operações. Isso é semelhante à função RunOperation quando em modo assíncrono.