Funções de instância no Jitterbit Studio
Introdução
Essas funções são destinadas ao uso em mapeamentos de transformação (ou scripts chamados durante os mapeamentos), pois utilizam as instâncias de elementos de dados (fontes e alvos) encontrados nos mapeamentos.
Inserção de um hash para retornar um array
Em casos onde um parâmetro de entrada obrigatório para uma função de instância é um array, um símbolo de hash (#) pode ser inserido no caminho de referência de um elemento de dados para retornar um array de dados em vez de um único campo.
Por exemplo:
SumString(_Root$customer.contact#.Email, ",", true);
No exemplo acima, o caminho do elemento de dados (_Root$customer.contact#.Email) é construído para retornar um array de endereços de email (.Email) dentro de um array de contatos (.contact). O # é inserido antes do array de endereços de email (#.Email) para indicar que em cada contato, pode haver um array de endereços de email. Isso resulta em um mapeamento que percorre o array nos registros de contato, mas não percorre o array nos emails.
Esse conceito também se aplica a nós de loop em transformações.
Uso avançado
As funções de instância podem, em geral, ser aninhadas umas dentro das outras. À medida que são aninhadas, os resultados se movem para cima na hierarquia e abrangem mais resultados. Essas funções podem retornar um único valor ou um array de valores, dependendo do contexto em que são usadas.
Por exemplo, uma função Sum que possui uma função Count dentro irá somar os resultados de cada invocação da função Count e produzir um total:
Sum(Count(_Root$customer.sales#.items#.ID));
Count
Declaração
int Count(type de)
int Count(array arr)
Sintaxe
Count(<de>)
Count(<arr>)
Parâmetros obrigatórios
de: (Primeira forma) Um caminho de entidade para instâncias de um elemento de dados em uma fonte ou um destinoarr: (Segunda forma) Um array; todos os elementos do array devem ser do mesmo tipo
Descrição
Conta todas as instâncias de um elemento de dados em um nível hierárquico particular em uma fonte ou destino, onde esse elemento de dados contém um valor válido (e não é nulo).
A função retorna um inteiro ou um array de instâncias, dependendo do contexto em que é chamada.
Nota
Não use a função Count para determinar se uma variável é um array. Use a função IsValid e tente acessar um índice de array em vez disso. Por exemplo, IsValid(variable[0]).
Exemplos
Suponha que um banco de dados contenha um campo "Quantidade" em uma tabela "Itens" que é um filho de "POHeader" (uma ordem de compra), e que haja muitos itens dentro de um POHeader. Então, esta instrução retorna o número de linhas de itens para um POHeader particular que têm valores na coluna Quantidade que não são nulos:
Count(POHeader.Items#.Quantity);
Neste caso, suponha um arquivo de dados com múltiplas instâncias nele, com clientes que têm vendas que têm itens; e cada item tem um campo ID. Esta instrução contará quantos itens diferentes estão em cada venda e usará a função Sum para somar todos os itens retornados para cada venda; este será o total de itens diferentes comprados:
Sum(Count(_Root$customer.sales#.items#.ID));
CountSourceRecords
Declaração
int CountSourceRecords()
Sintaxe
CountSourceRecords()
Descrição
Retorna o número de instâncias de origem para um nó de destino, quando o nó de destino se refere a um pai de um campo de mapeamento.
Se o nó de destino não for um nó de loop, a função retorna 1. Veja também a função SourceInstanceCount.
Nota
O modo de streaming de uma transformação Flat-to-Flat não seria afetado pelo uso desta função, enquanto o modo de streaming seria desativado para uma transformação XML-to-Flat.
Exemplos
Suponha uma fonte com registros de cliente que têm instâncias de vendas com instâncias de itens com um campo Tipo:
// Esta declaração mostra a contagem de instâncias de um registro em comparação
// ao número total de registros de origem
"Registro " + SourceInstanceCount() + " de " + CountSourceRecords();
Exist
Declaração
bool Exist(type v, type de)
bool Exist(type v, array arr)
Sintaxe
Exist(<v>, <de>)
Exist(<v>, <arr>)
Parâmetros obrigatórios
v: Um valor a ser encontradode: (Primeira forma) Um caminho de entidade para instâncias de um elemento de dados em uma fonte ou um destinoarr: (Segunda forma) Um array; todos os elementos do array devem ser do mesmo tipo e ser do mesmo tipo quev
Descrição
Verifica a existência de um valor (v) em instâncias de um elemento de dados (de) ou em um array (arr) e retorna verdadeiro (ou falso) dependendo se é encontrado.
A função retorna um booleano ou um array de instâncias, dependendo do contexto em que é chamada.
Exemplos
Suponha uma fonte com registros de cliente que têm instâncias de vendas com instâncias de itens com um campo Tipo:
// Returns if true if the value "subscription" is
// found in any instances of a field "customer.sales.items.Type"
// at the level of "sales":
Exist("subscription",_Root$customer.sales.items#.Type);
// To test this at the next highest level of the hierarchy,
// at the level of the customer,
// enclose this in a nested "Exist", testing for "true":
Exist(true, Exist("subscription",_Root$customer.sales#.items#.Type));
// The last statement answers, at the customer level, if a customer
// has any items in any sales with a Type field equal to "subscription"
FindByPos
Declaração
type FindByPos(int pos, type de)
type FindByPos(int pos, array arr)
Sintaxe
FindByPos(<pos>, <de>)
FindByPos(<pos>, <arr>)
Parâmetros obrigatórios
pos: O índice (de qual ocorrência; baseado em 1) para recuperar o valorde: (Primeira forma) Um caminho de entidade para instâncias de um elemento de dados em uma fonte ou um destino; ouarr: (Segunda forma) Um array; todos os elementos do array devem ser do mesmo tipo
Descrição
Retorna o valor de um elemento de dados de uma instância que ocorre várias vezes. Também pode ser usado para retornar um elemento de um array, de forma baseada em 1.
Se um número negativo for especificado para a ocorrência ou array, a contagem começará a partir da última linha ou elemento. Note que o índice é baseado em 1.
Exemplos
// Assume a database has a child-parent relationship
// where for each parent the child occurs multiple times
// To retrieve the second child, use:
FindByPos(2, ParentTab.ChildTab#.Value$);
// To retrieve the last child, use:
FindByPos(-1, ParentTab.ChildTab#.Value$);
FindValue
Declaração
type FindValue(type0 v, type1 de1, type2 de2)
Sintaxe
FindValue(<v>, <de1>, <de2>)
Parâmetros obrigatórios
v: Um valor a ser pesquisadode1: Um caminho de entidade para instâncias de um elemento de dados em uma fonte ou um destino, a ser usado como correspondênciade2: Um caminho de entidade para instâncias de um elemento de dados em uma fonte ou um destino, a ser retornado se uma correspondência for encontrada
Descrição
Pesquisa múltiplas instâncias de um elemento de dados (de1) em busca do valor especificado em v. Se a função encontrar o valor, ela retorna o valor no campo especificado no terceiro parâmetro (de2) para aquela instância encontrada. Se o valor não for encontrado, a função retorna nulo. Veja também a função HasKey.
Exemplos
Esta instrução irá pesquisar as instâncias de B sob A e verificar o conteúdo de field1. Ela selecionará a primeira instância de B que encontrar onde field1 contém "ID", e então retornará o valor de field2 daquela mesma instância:
FindValue("ID", A.B#.field1, A.B#.field2);
Essas declarações mostram como implementar um teste de um array para inclusão de um valor. Ele busca um valor em um array e retorna verdadeiro se encontrado e falso se não. É o equivalente em array da função HasKey do dicionário. Note que duas instâncias do mesmo array são passadas para a função:
arr = {1, 2, 3};
value = 1;
t = (FindValue(value, arr, arr) == value);
// t will be 1 (true)
value = 4;
t = (FindValue(value, arr, arr) == value);
// t will be 0 (false)
GetInstance
Declaração
type GetInstance()
Sintaxe
GetInstance()
Descrição
Esta função retorna o elemento de dados da instância que foi definido ao chamar uma função SetInstances durante a geração do pai. Como alternativa a esta função, veja a função ArgumentList.
Exemplos
Suponha que uma das mapeações pai de uma transformação contenha estas declarações:
...
r1=DBLookupAll("<TAG>endpoint:database/My Database</TAG>",
"SELECT key_name, key_value, key_type FROM key_values");
SetInstances("DETAILS", r1);
r2 = {"MS", "HP", "Apple"};
SetInstances("COMPANIES", r2);
...
No nó de destino DETAILS, podemos criar uma condição de mapeamento usando:
<trans>
GetInstance()["key_value"] != "";
// Same as GetInstance()[0] != ""
</trans>
ou, em um dos atributos, o mapeamento pode conter:
<trans>
x=GetInstance();
x["key_name"] + "=" + x["key_value"];
// Same as x[0] + "=" + x[1]
</trans>
Em um dos atributos do nó de destino COMPANIES ou no próprio nó de destino, o mapeamento pode conter:
<trans>
GetInstance();
// This will return
// "MS" for the first instance
// "HP" for the second instance
// "Apple" for the third instance
</trans>
Exemplo visual e saída
Abaixo está um exemplo de configuração de esquema aplicando o exemplo r2 acima a um nó de loop getInformationRequest e um nó de loop de destino COMPANIES. DETAILS foi excluído por simplicidade.
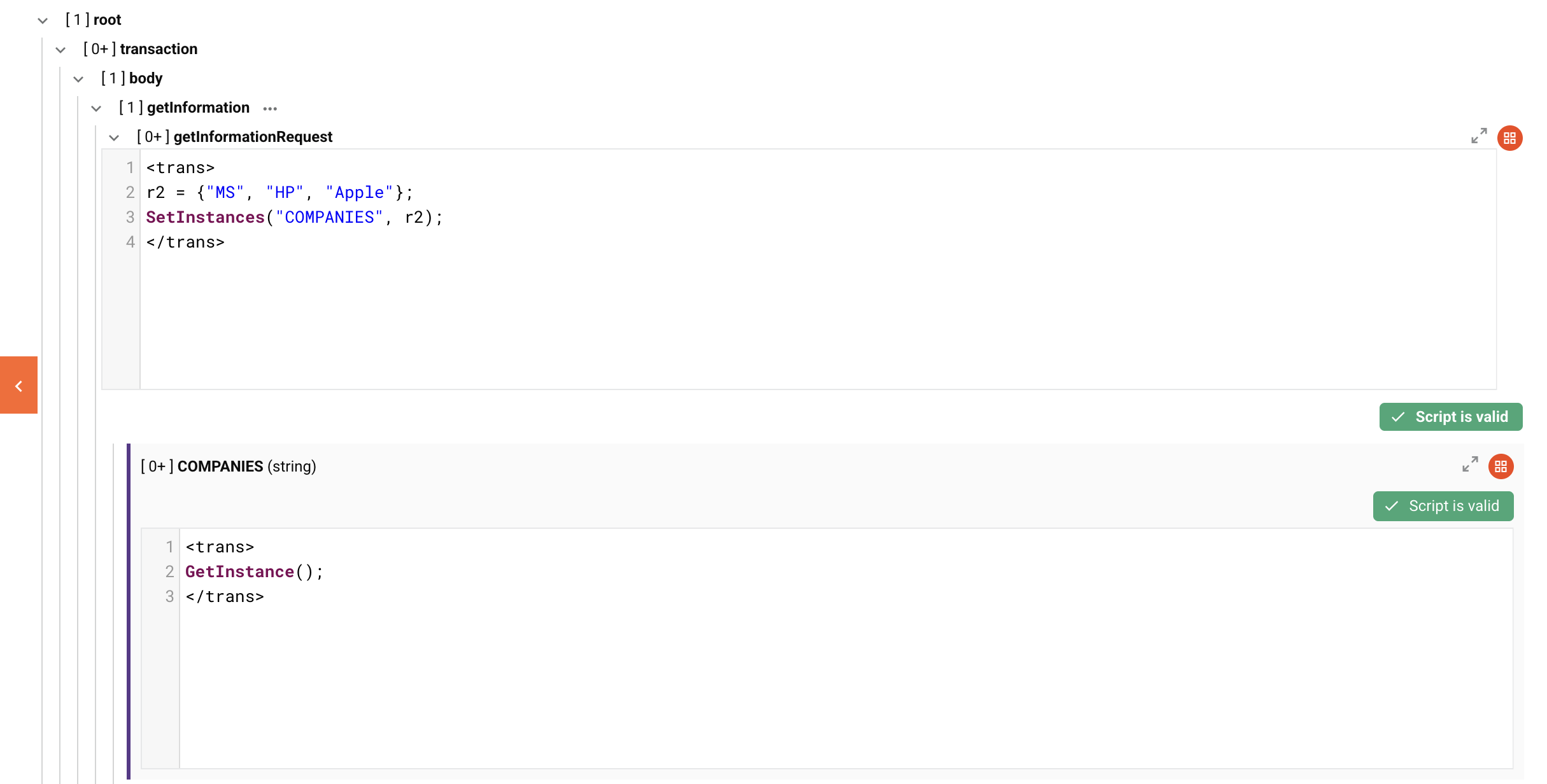
O XML resultante se a saída for escrita diretamente após a transformação:
<?xml version="1.0" encoding="UTF-8"?>
<root xmlns="http://www.jitterbit.com/XsdFromWsdl" xmlns:ns="com.iex.tv.webservices.services.agentResourcesService" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<transaction>
<body>
<ns:getInformation>
<ns:getInformationRequest>
<ns:COMPANIES>MS</ns:COMPANIES>
<ns:COMPANIES>HP</ns:COMPANIES>
<ns:COMPANIES>Apple</ns:COMPANIES>
</ns:getInformationRequest>
</ns:getInformation>
</body>
</transaction>
</root>
Max
Declaração
type Max(type de)
type Max(array arr)
Sintaxe
Max(<de>)
Max(<arr>)
Parâmetros obrigatórios
de: (Primeira forma) Um caminho de entidade para instâncias de um elemento de dados em uma fonte ou um destinoarr: (Segunda forma) Um array; todos os elementos do array devem ser do mesmo tipo
Descrição
Retorna o valor máximo das instâncias de um elemento de dados em um nível particular na hierarquia de uma estrutura de dados. Ele verificará todas as instâncias nesse nível e retornará a maior. Também pode ser usado para retornar o valor máximo de um array.
Exemplos
Suponha que um banco de dados contenha um campo "Quantidade" em uma tabela "Itens" que é um filho de "POHeader" (uma ordem de compra), e que haja muitos itens dentro de um POHeader. Então, esta instrução retorna o valor máximo de Quantidade para qualquer item de um POHeader específico:
Max(POHeader.Items#.Quantity);
Min
Declaração
type Min(type de)
type Min(array arr)
Sintaxe
Min(<de>)
Min(<arr>)
Parâmetros obrigatórios
de: (Primeira forma) Um caminho de entidade para instâncias de um elemento de dados em uma fonte ou um destinoarr: (Segunda forma) Um array; todos os elementos do array devem ser do mesmo tipo
Descrição
Retorna o valor mínimo das instâncias de um elemento de dados em um nível particular na hierarquia de uma estrutura de dados. Ele verificará todas as instâncias nesse nível e retornará a menor. Também pode ser usado para retornar o valor mínimo de um array.
Exemplos
Suponha que um banco de dados contenha um campo "Quantidade" em uma tabela "Itens" que é um filho de "POHeader" (uma ordem de compra), e que haja muitos itens dentro de um POHeader. Então, esta instrução retorna o valor mínimo de Quantidade para qualquer item de um POHeader específico:
Min(POHeader.Items#.Quantidade);
ResolveOneOf
Declaração
type ResolveOneOf(type de)
type ResolveOneOf(array arr)
Sintaxe
ResolveOneOf(<de>)
ResolveOneOf(<arr>)
Parâmetros obrigatórios
de: (Primeira forma) Um caminho de entidade para instâncias de um elemento de dados em uma fonte ou um destinoarr: (Segunda forma) Um array; todos os elementos do array devem ser do mesmo tipo
Descrição
Retorna o primeiro valor não nulo das instâncias de um elemento de dados. Esta função é geralmente usada para recuperar o valor de um elemento de dados de origem "um de". Também pode ser usada com arrays e retornará o primeiro elemento não nulo.
SetInstances
Declaração
null SetInstances(string nodeName, array de)
Sintaxe
SetInstances(<nodeName>, <de>)
Parâmetros obrigatórios
nodeName: O nome de um destinode: Um caminho de entidade para instâncias de um elemento de dados no destino
Descrição
Define as instâncias de origem para um nó de loop de destino. Normalmente, uma instância de destino de loop é gerada a partir de uma instância de origem de loop. Às vezes, os dados podem vir de outras fontes. Esta função é destinada a casos em que os dados estão em múltiplos conjuntos e cada conjunto gera um único elemento de destino.
A instância é um elemento de dados que pode ser um valor simples ou um array de elementos de dados. Ao criar o destino, cada instância será usada para gerar uma instância de destino.
Para ver como usar um elemento de dados de instância, consulte as funções GetInstance e ArgumentList.
Esta função deve ser chamada nas mapeações do nó pai do destino pretendido. Se nenhum nó folha estiver disponível no pai, você pode criar um nó de condição que chama esta função. A condição deve terminar com true para que sempre seja aceita.
A função não deve ser chamada mais de uma vez com o mesmo nó de destino, pois a última chamada sobrescreve as anteriores. Para evitar ser sobrescrito, você pode criar pastas de mapeamento múltiplo.
Um elemento de dados nulo é retornado por esta função e deve ser ignorado.
Exemplos
Suponha que exista um pai comum para os nós de destino DETAILS e COMPANIES; ambos são nós de loop; e uma pasta de mapeamento múltiplo foi criada para o nó de destino DETAILS.
...
r1 = DBLookupAll("<TAG>endpoint:database/My Database</TAG>",
"SELECT key_name, key_value FROM key_values");
SetInstances("DETAILS", r1);
SetInstances("DETAILS#1", r1);
// DETAILS#1 is the name of the
// 1st multiple-mapping-folder for DETAILS
r2 = {"MS", "HP", "Apple"};
SetInstances("COMPANIES", r2);
// Note: Renaming the display name of a
// multiple-mapping-folder doesn't change
// the folder's actual name, which can be
// found by control-clicking the node and using
// "Copy node name to clipboard"
...
Exemplo visual e saída
Abaixo está um exemplo de configuração de esquema aplicando o exemplo r2 acima a um nó de loop getInformationRequest e a um nó de loop de destino COMPANIES. DETAILS foi excluído por simplicidade.
O XML resultante se a saída for escrita diretamente após a transformação:
<?xml version="1.0" encoding="UTF-8"?>
<root xmlns="http://www.jitterbit.com/XsdFromWsdl" xmlns:ns="com.iex.tv.webservices.services.agentResourcesService" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<transaction>
<body>
<ns:getInformation>
<ns:getInformationRequest>
<ns:COMPANIES>MS</ns:COMPANIES>
<ns:COMPANIES>HP</ns:COMPANIES>
<ns:COMPANIES>Apple</ns:COMPANIES>
</ns:getInformationRequest>
</ns:getInformation>
</body>
</transaction>
</root>
SortInstances
Declaração
null SortInstances(string nodeName, array sourceDataElements1[, bool sortOrder, ..., array sourceDataElementsN, bool sortOrderN])
Sintaxe
SortInstances(<nodeName>, <sourceDataElements1>[, <sortOrder>, ..., <sourceDataElementsN>, <sortOrderN>])
Parâmetros obrigatórios
nodeName: Nome dos elementos de loop de destino a serem ordenadossourceDataElements: Um caminho de entidade para instâncias de um elemento de dados em uma fonte ou um destino
Parâmetros opcionais
sourceDataElementsN: Um caminho de entidade para instâncias de um elemento de dados em uma fonte ou um destinosortOrder: Uma ordem de classificação opcional, padrão verdadeiro para ascendente. O argumento não é opcional se múltiplos argumentossourceDataElementsforem fornecidos.
Descrição
Classifica a geração de elementos de dados do loop de destino com base em um ou mais elementos de dados na origem ou no destino.
Todas as instâncias de classificação devem ter o mesmo número de instâncias que o número de instâncias de destino.
A ordem de classificação é assumida como ascendente, e um argumento escalar opcional pode ser colocado ao lado de cada elemento de dados de classificação para substituir a ordem de classificação padrão. Se o sortOrder for falso, a ordem de classificação será descendente.
Os elementos de dados do loop de destino serão classificados primeiro pelas instâncias dos primeiros elementos de dados de origem e, em seguida, classificados pelas instâncias dos segundos elementos de dados, e assim por diante.
Esta função deve ser chamada nas mapeações do nó pai. Se não houver campo para mapear no nó pai, pode-se chamar um script com esta função ou adicionar uma condição para esse propósito.
Um valor nulo é retornado por esta função e deve ser ignorado.
Exemplos
// The target node "detail" will be ordered
// by "price" from high to low and,
// if the prices are the same for two items,
// the node will be ordered by "quantity" from low to high
SortInstances("detail", Invoice$Item#.price, false, Invoice$Item#.quantity);
Este próximo exemplo pode ser usado em uma condição em um mapeamento para classificar todas as vendas de cada cliente por data. Ele deve ser colocado no nível do nó customer. Note a inclusão da declaração true no final do bloco de código para que a condição seja sempre aceita:
<trans>
SortInstances("SalesOrders", _Root$customer.sales#.SalesDate);
true
</trans>
Sum
Declaração
type Sum(type de)
type Sum(array arr)
Sintaxe
Sum(<de>)
Sum(<arr>)
Parâmetros Obrigatórios
de: (Primeira forma) Um caminho de entidade para instâncias de um elemento de dados em uma origem ou um destinoarr: (Segunda forma) Um array; todos os elementos do array devem ser do mesmo tipo
Descrição
Obtém o valor de cada instância de um elemento de dados em um nível hierárquico particular e retorna a soma. O tipo de dado de ambos de e arr deve ser um dos tipos inteiro, longo, flutuante, duplo ou string. Os tipos de dados de todas as instâncias ou todos os elementos devem ser os mesmos.
Se o array estiver vazio, 0 (zero) é retornado. Embora valores nulos sejam ignorados em arrays com outro tipo de dado, um array contendo apenas nulos retornará um erro.
Exemplos
Suponha um banco de dados contendo um campo "Quantidade" em uma tabela "Itens" que é um filho de POHeader (há muitos itens dentro de um POHeader).
// Retorna a soma do campo "Quantidade" para
// todos os itens de um "POHeader" específico
Sum(POHeader.Items#.Quantity);
SumCSV
Declaração
string SumCSV(type de)
string SumCSV(array arr)
Sintaxe
SumCSV(<de>)
SumCSV(<arr>)
Parâmetros obrigatórios
de: (Primeira forma) Um caminho de entidade para instâncias de um elemento de dado em uma fonte ou um destinoarr: (Segunda forma) Um array; todos os elementos do array devem ser do mesmo tipo
Descrição
Concatena cada instância de um campo de um elemento de dado ou cada elemento de um array, com um delimitador de vírgula entre cada instância ou elemento.
Se o campo ou elemento do array contiver caracteres especiais, como quebras de linha ou vírgulas, o campo ou elemento do array é colocado entre aspas duplas. Nenhum delimitador é adicionado após a última instância ou elemento ser concatenado.
Veja também a função SumString para uma função semelhante, mas com opções adicionais.
Exemplos
// Concatena todas as instâncias de um campo de endereços de email
// com uma vírgula entre cada endereço
SumCSV(_Root$customer.contact#.Email);
SumString
Declaração
string SumString(type de[, string delimiter, bool omitLast])
string SumString(array arr[, string delimiter, bool omitLast])
Sintaxe
SumString(<de>[, <delimiter>, <omitLast>])
SumString(<arr>[, <delimiter>, <omitLast>])
Parâmetros obrigatórios
de: (Primeira forma) Um caminho de entidade para instâncias de um elemento de dados em uma fonte ou um destinoarr: (Segunda forma) Um array; todos os elementos do array devem ser do mesmo tipo
Parâmetros opcionais
delimiter: Uma string para delimitar os itens; o valor padrão é um ponto e vírgulaomitLast: Um indicador que indica se deve incluir o delimitador após o último item; o valor padrão é falso
Descrição
Concatena cada instância dos elementos de dados especificados ou cada elemento de um array, com um delimitador automaticamente anexado ao final de cada string concatenada.
Se o parâmetro omitlast for verdadeiro, o delimitador após a última string é omitido.
Veja também a função SumCSV.
Exemplos
// Concatenates all instances of a field of email addresses
// with a comma between each address,
// but does not place a delimiter after the last address
SumString(_Root$customer.contact#.Email, ",", true);