Capture alterações de dados com alterações de tabela ou arquivo no Jitterbit Design Studio
Caso de uso
Quando outros padrões para captura de dados de alterações não são viáveis (Padrão de integração para captura de dados de alterações usando consultas baseadas em registro de data e hora, Padrão de integração para captura de dados de alteração usando valores de campo de origem, Padrão de integração para captura de dados de alterações usando fontes de arquivo, Padrão de integração: captura de dados alterados - em tempo real/orientado por eventos), esse padrão pode ser aplicado.
Esse padrão se aplica em casos em que a origem não tem um registro de data e hora, não pode ser alterada para fornecer um campo a ser usado para consultar ou não pode enviar alterações.
Este padrão pressupõe que os registros de origem e destino podem ser comparados e as diferenças podem ser isoladas. Por exemplo, suponha que uma tabela de clientes em uma origem tenha 150 linhas e a tabela de clientes no destino tenha 100 linhas. O objetivo é determinar as linhas na origem que são Novas (não existem no destino), Diferentes (mesma linha e dados diferentes) e Ausentes (a linha não existe no destino). Se Novas, insira no destino. Se Diferentes, atualize a linha no destino. Se Ausentes, exclua do destino.
A documentação da função Diff do Jitterbit tem explicações detalhadas das diferentes funções Diff : Funções Diff.
Um caso de uso frequente desse padrão é que um processo é necessário para recuperar uma alteração em uma tabela de banco de dados de um período para o outro.
Aviso
As funções Diff podem ser usadas somente em um único agente privado, pois os snapshots diff não são compartilhados. Não use em um grupo de agentes com mais de um agente. Elas não são suportadas com agentes de nuvem.
Exemplo 1: Comparação de banco de dados para banco de dados
Neste exemplo, o cliente tem um banco de dados que sustenta um sistema transacional e deseja sincronizar determinados objetos de negócios com um armazenamento de dados externo para fins de auditoria.
Os passos básicos são:
- Inicialize o Diff e adicione registros ao snapshot no disco. Se esta não for a primeira vez que o processo é executado, então isso selecionará os novos registros.
- Passe novos registros para a transformação e atualize o banco de dados de destino.
- Processar as atualizações (mudanças desde a última vez que o processo foi executado)
- Passar para a transformação e atualizar o banco de dados de destino
- Processar as exclusões
- Passar para a transformação e atualizar o banco de dados de destino
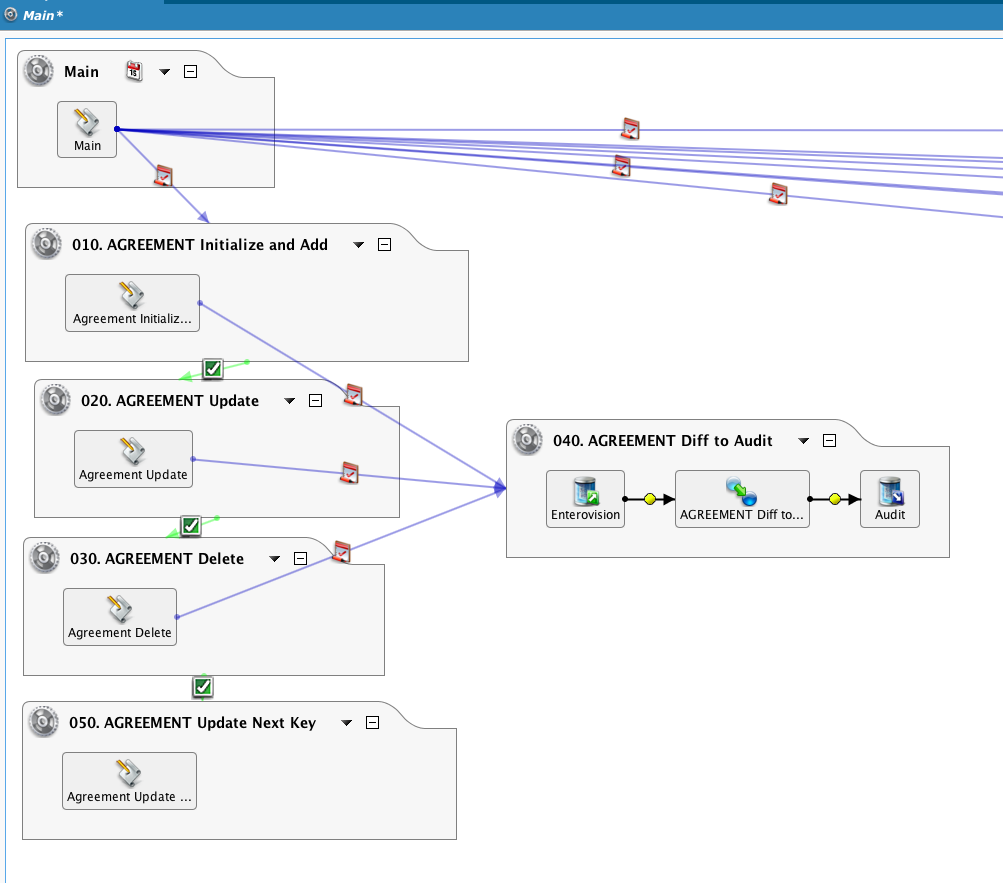
A operação Main aciona uma série de operações encadeadas, selecionando apenas uma tabela como exemplo.
Ao passar um 'false' argumento, o RunOperation() funções (veja Funções gerais do construtor de fórmulas) será executado de forma assíncrona:
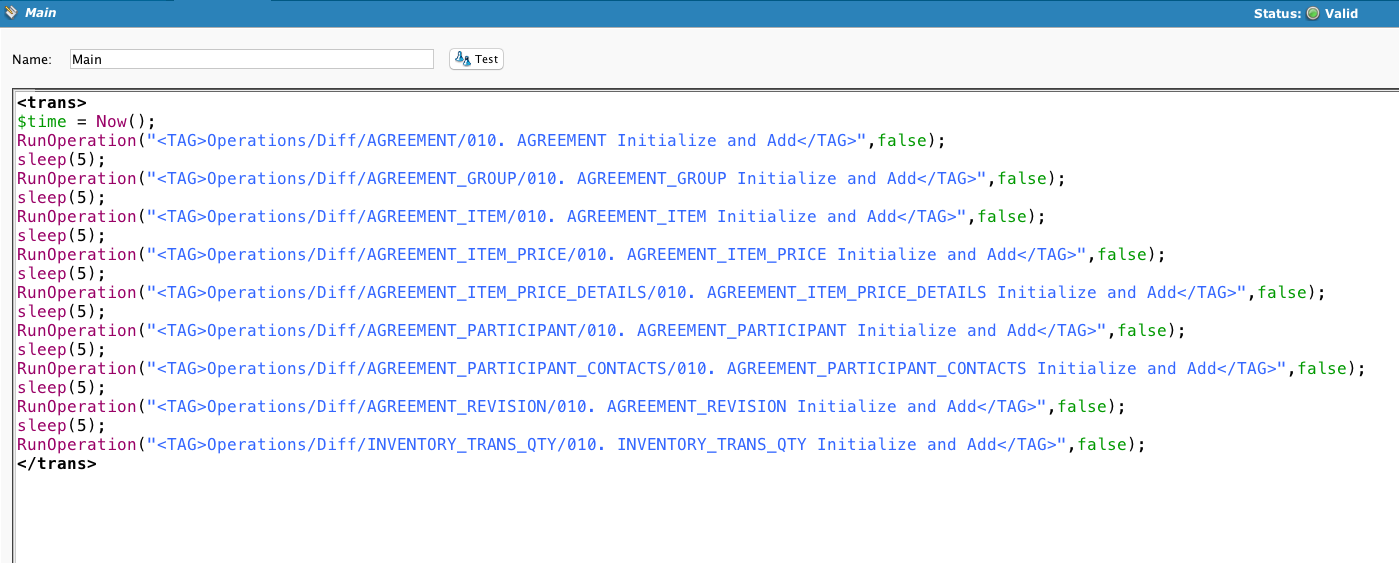
InitializeDiff é chamado e avaliado. Se falhar, então ResetDiff é chamado.
DiffKeyList define o identificador exclusivo do registro.
Se esta for a primeira vez que está sendo executado, todos os registros na fonte serão adicionados ao snapshot. Caso contrário, ele selecionará os novos registros.
Se houver uma falha, a cadeia de operação será cancelada.
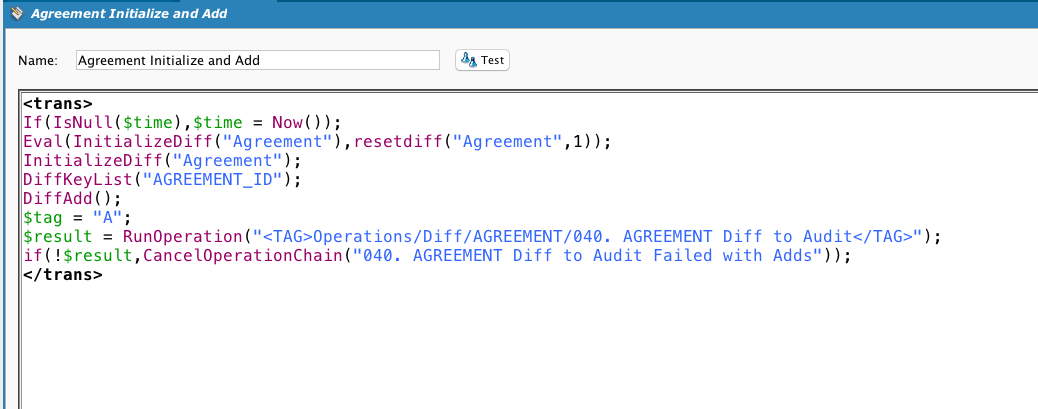
Esta é a transformação usada pela operação. Observe que, embora haja uma fonte de BD, se a chamada da operação for precedida por uma chamada Diff, a fonte da operação não será usada. Se um DiffUpdate for chamado, então esta operação será chamada e obteremos a saída da função DiffUpdate:
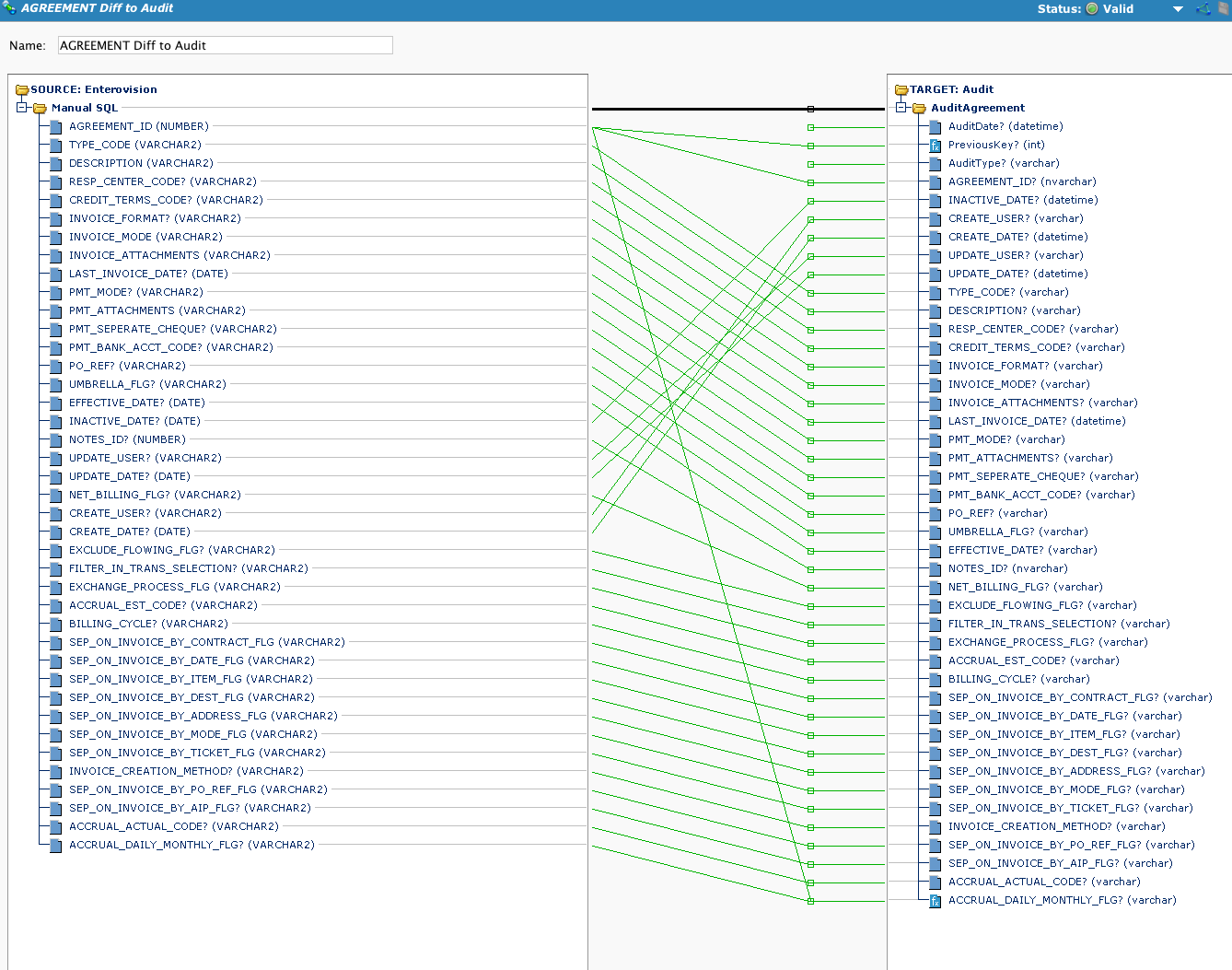
Chama DiffUpdate. Observe o uso de uma tag de variável global para indicar ao alvo que tipo de ação foi realizada.
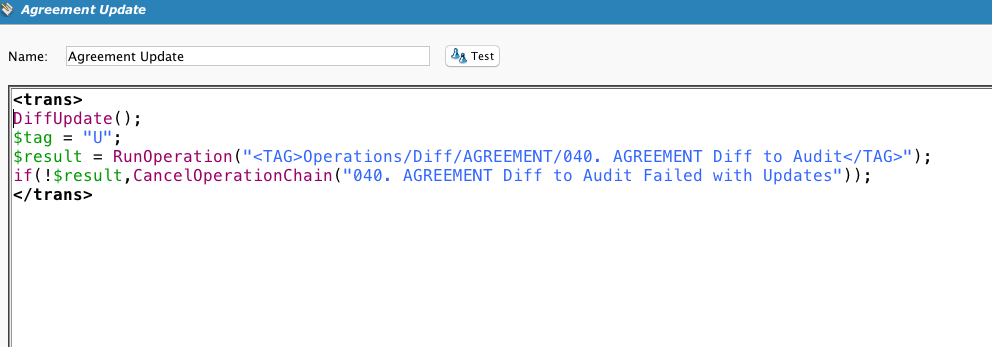
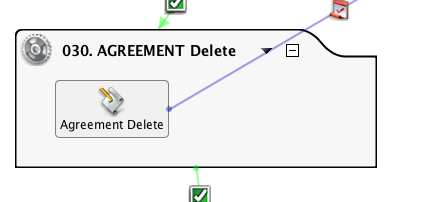
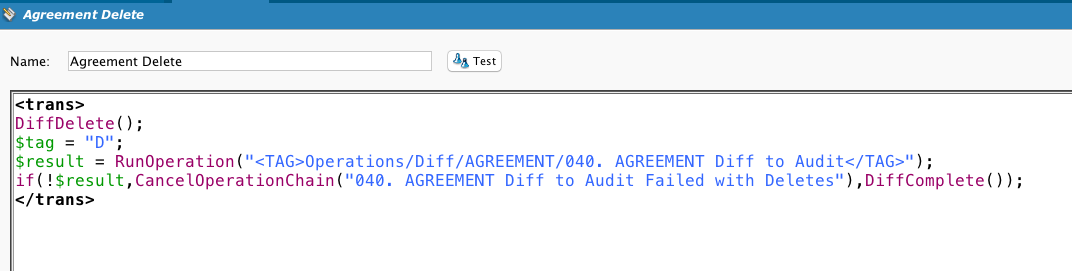
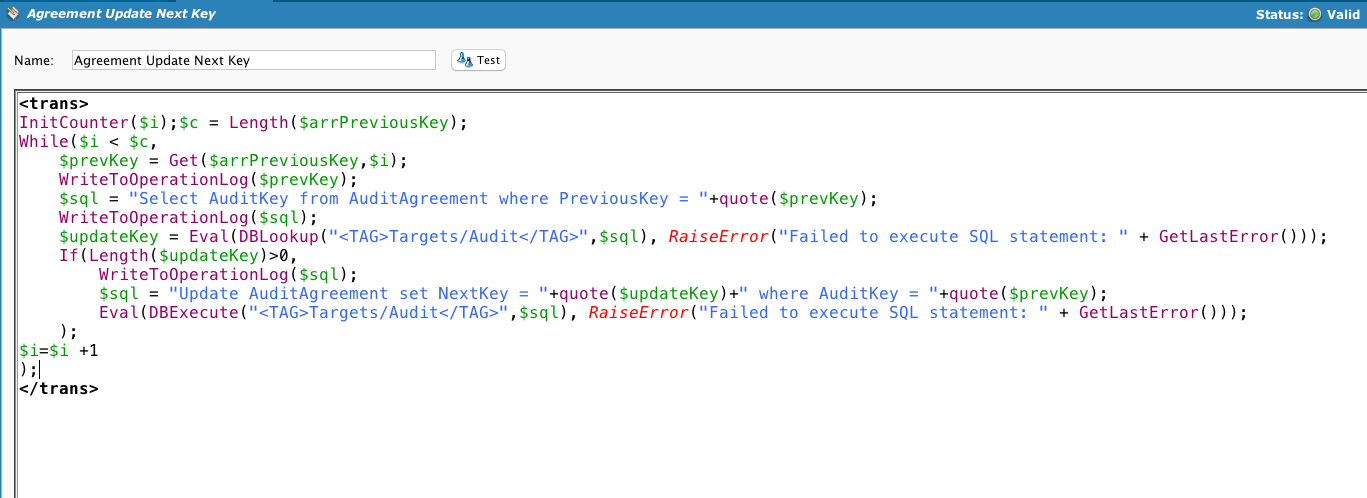
Mostrando este script para fins de completude. O cliente queria armazenar um registro das linhas novas e alteradas, não sincronizar dois armazenamentos de dados. Então, os processos Diff incorporaram um método de geração de chaves exclusivas que mostrarão as alterações no mesmo registro ao longo do tempo.
Exemplo 2: Comparação entre organizações
Este exemplo compara dois objetos do Salesforce simultaneamente.
Em geral, as etapas do Diff são:
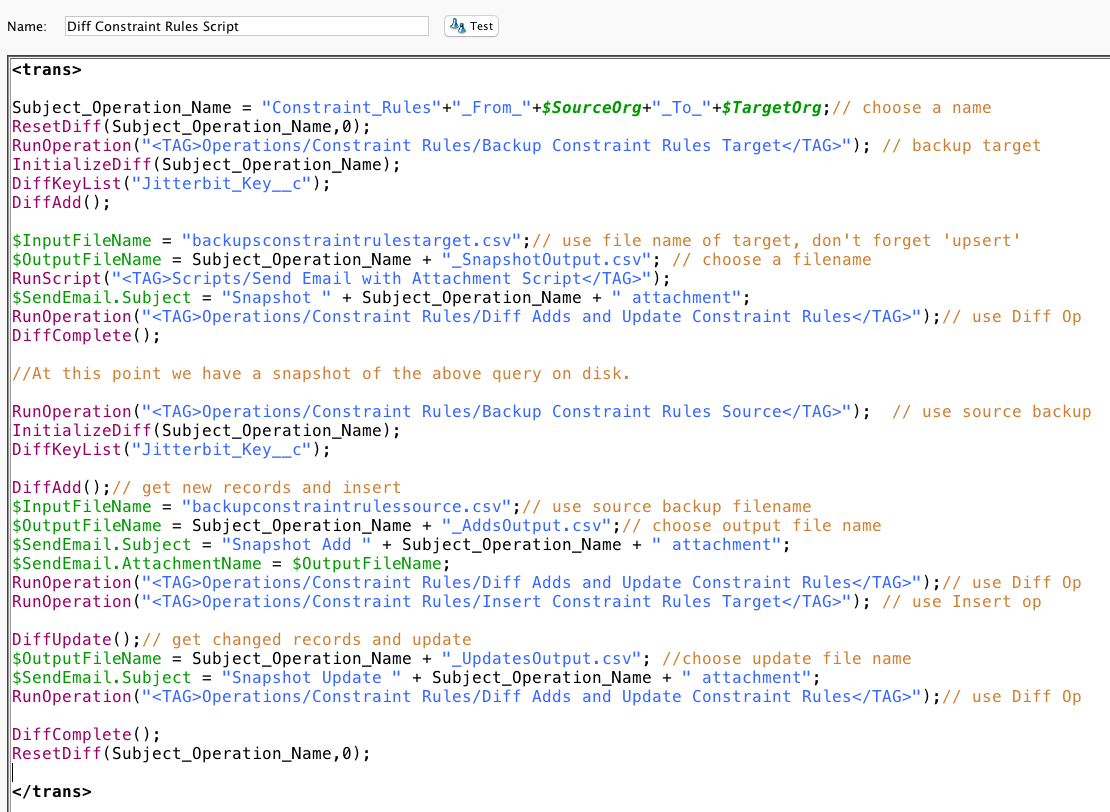
- Limpe o arquivo Diff antigo (ResetDiff). Não estamos rastreando alterações ao longo do tempo. Estamos rastreando diferenças entre arquivos de origem e de destino a partir deste ponto no tempo.
- Crie o Diff (InitializeDiff). Isso atribui a ele um nome exclusivo para ser usado como a chave para o diretório Diff que será criado no disco do servidor do agente privado. O nome do objeto é usado como o nome Diff.
- Defina o campo-chave (DiffKeyList). Isso dirá ao Diff qual campo na linha é o campo-chave e será usado para comparar linhas específicas no novo arquivo Diff com linhas no arquivo Diff antigo.
- Preencha o Diff (DiffAdd) da tabela de clientes de destino (neste caso, um arquivo csv criado pela consulta da tabela de clientes de destino). As linhas da "fonte" (neste caso, o arquivo csv criado pela consulta da tabela de clientes de destino) são lidas no arquivo Diff. O comportamento é diferente se o arquivo Diff estiver vazio, ou seja, se esta for a primeira vez que o Diff é criado.
- Salve o Diff (DiffComplete). Neste ponto, há um snapshot da tabela de clientes de destino no disco do servidor do agente privado.
- Inicie a comparação da fonte (neste caso, um arquivo csv criado pela consulta da tabela de clientes de origem) com o destino (um arquivo csv criado pela consulta da tabela de clientes de destino), começando com a leitura dos registros no arquivo csv de origem (DiffAdd). Então, enquanto usamos a mesma função DiffAdd acima, ela se comporta de forma diferente, pois há um arquivo Diff existente. Desta vez, ela compara os dois arquivos e gera as novas linhas com base no campo estabelecido pela DiffKeyList
- Comparar com base em alterações (DiffUpdate). O Diff faz o hash dos registros individuais nos arquivos antigos e novos, e identificará os registros alterados com base na mesma chave, mas em hashes diferentes. Isso produzirá as linhas alteradas.
- Salve o Diff (DiffComplete).
- Apagar o Diff (ResetDiff).
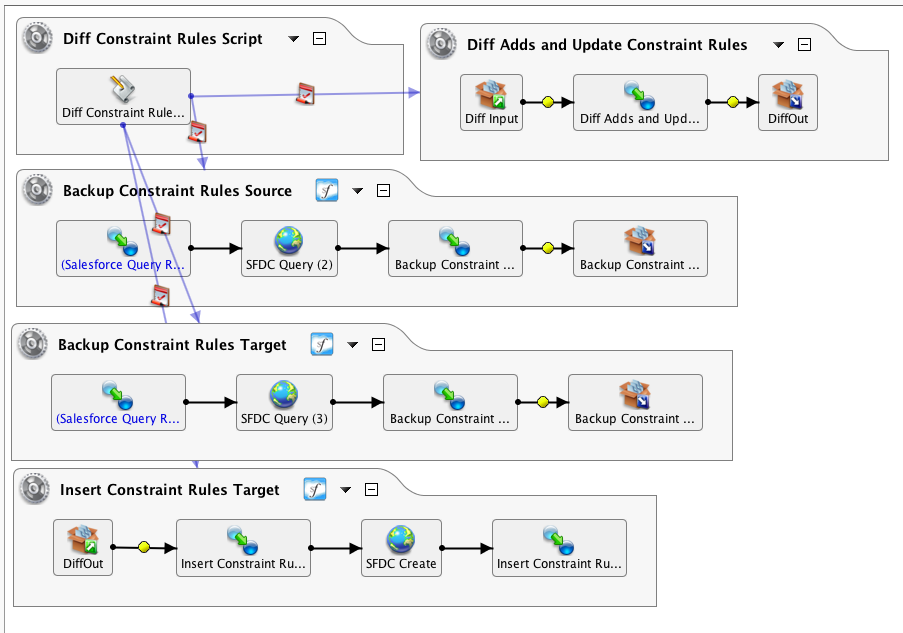
Este exemplo tem duas organizações do Salesforce com objetos e campos idênticos. A organização de origem contém dados que devem ser adicionados ou atualizados na organização de destino. Devido ao uso de gatilhos e atualizações, simplesmente consultar a origem com base em um carimbo de data/hora do objeto não é viável. Fazer uma cópia completa, consultando a origem inteira e fazendo upserting no destino, é um método viável, mas para conjuntos de dados muito grandes pode ser muito demorado. A preferência aqui era fazer uma migração das diferenças entre as organizações de origem e destino usando o Diff() funções.
Como o Diff só pode trabalhar com bancos de dados ou arquivos CSV, as consultas de origem e destino são convertidas nesse formato:
Isso consulta o alvo, e há uma operação semelhante que consulta a origem.
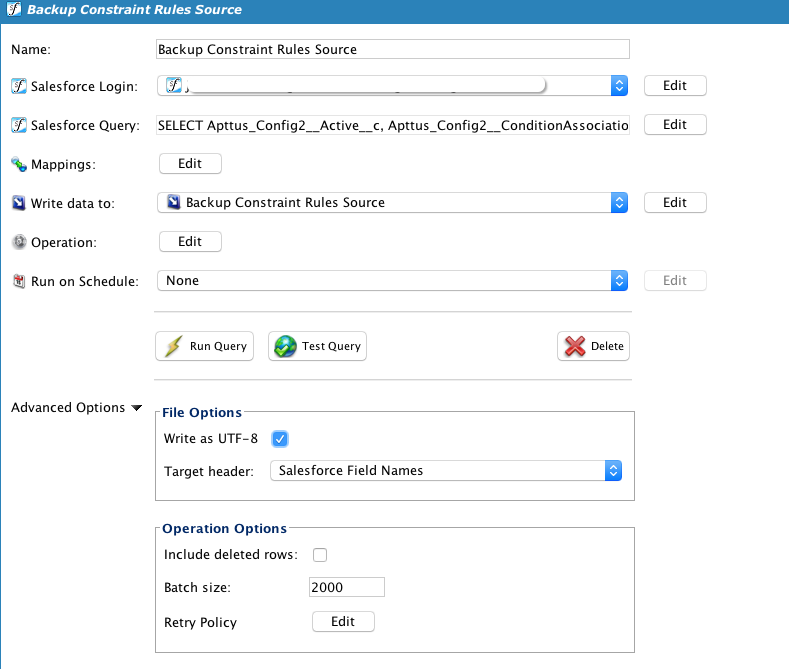
Observe que a consultar é limitada a dados comerciais, excluindo dados do sistema como LastModifiedDate, que serão diferentes da origem e do destino, bem como IDs de registro. Além disso, os cabeçalhos são selecionados, pois são necessários para auxiliar o usuário a visualizar os dados. O Destino de backup é idêntico, exceto pela organização do Salesforce.

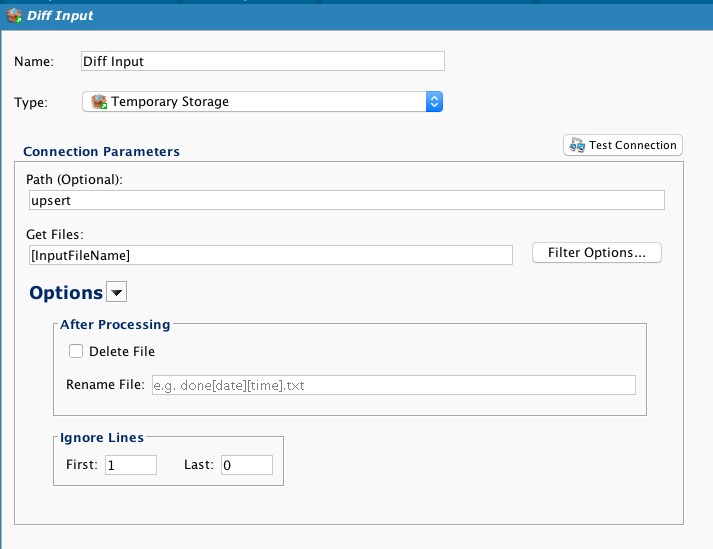
Uma fonte de armazenamento temporário é usada, onde uma variável global é usada para o nome do arquivo, e a primeira linha é ignorada.
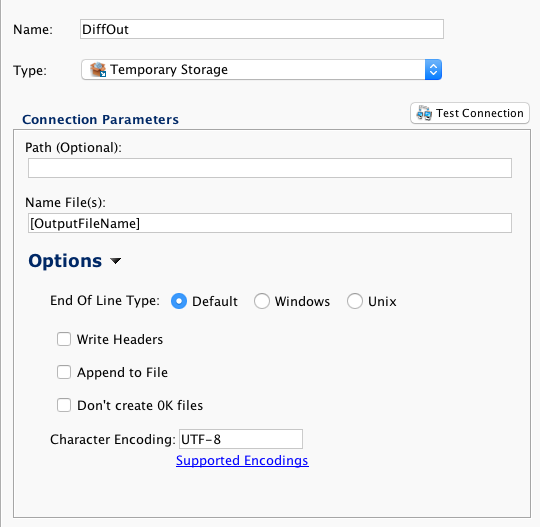
O alvo é um arquivo de armazenamento temporário. Pode ser um site FTP ou um compartilhamento de arquivo de rede. Novamente, uma variável global é usada para selecionar dinamicamente o nome do arquivo.
Este exemplo está usando um objeto Apttus padrão. Este formato de arquivo será usado repetidamente na cadeia de operações. Neste caso, os objetos de origem e destino usam um ID externo chamado 'Jitterbit_Key' para associar registros nas diferentes organizações. O Diff usará isso para identificar as novas linhas, bem como as linhas atualizadas.
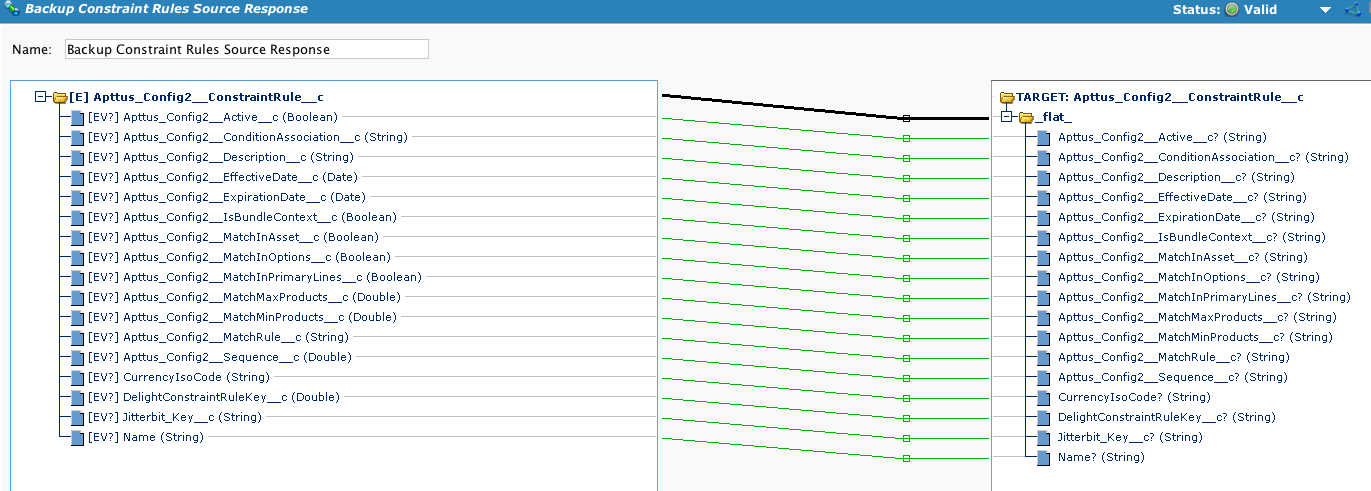
Isso executará a inserção de dados conforme a saída do arquivo Diff.
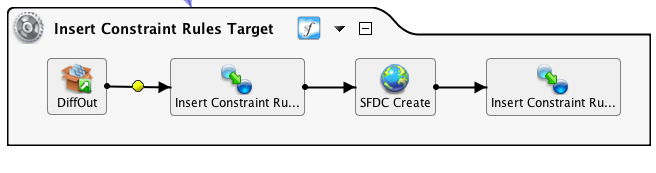
Novamente, o uso de uma variável global para selecionar dinamicamente um nome de arquivo:
Reutilizando o formato de arquivo, que agora é mapeado para o objeto Apttus.

Notas importantes:
Subject_Operation_Name é uma variável local e é usada para armazenar uma string que é usada repetidamente.
Melhor prática
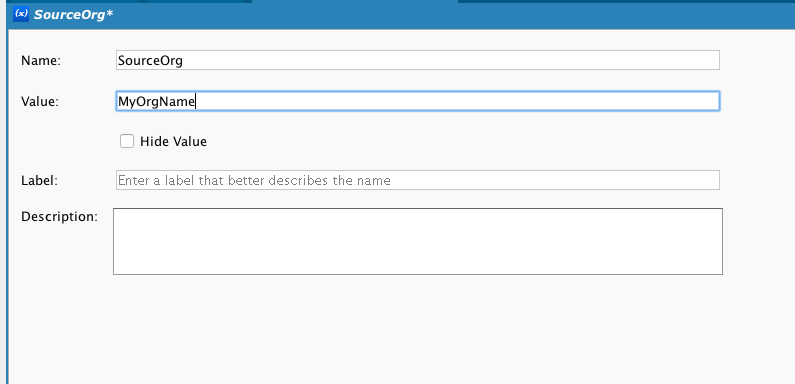
SourceOrg e TargetOrg são variáveis de projeto Jitterbit que contêm o nome da organização. Uma variável de projeto é um valor que está disponível para todos os objetos Jitterbit que podem trabalhar com uma variável. Observe que a formatação no editor de script é verde e em itálico:
As variáveis do projeto são definidas no Jitterbit Design Studio:
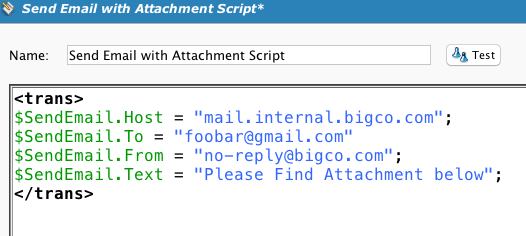
Outro script é chamado, que permite a captura da saída e a adiciona como um anexo a um email. Isso requer o uso de um plug-in Enviar email com anexo no alvo. (Veja a atualização abaixo).
O Diff Add and Update operação é usada repetidamente, já que as fontes e os alvos usam uma variável ("$OutputFile") para selecionar dinamicamente os arquivos a serem processados. Isso permite muito a reutilização de operações.
Método atualizado usando alvos de email
As versões atuais do Harmony incluem alvos de email; eles são superiores para lidar com anexos de email, pois não exigem o uso de um plug-in.
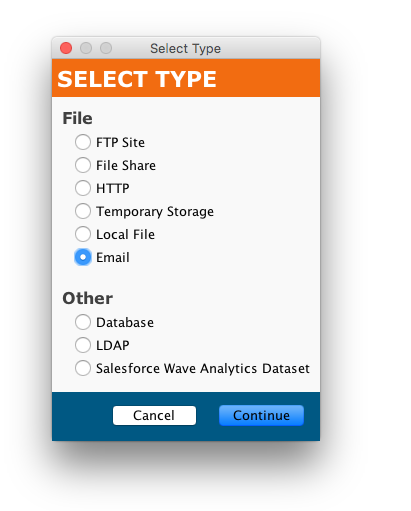
Primeiro, crie um alvo de e-Email:
Segundo, crie um email e defina o limite de tamanho do anexo:
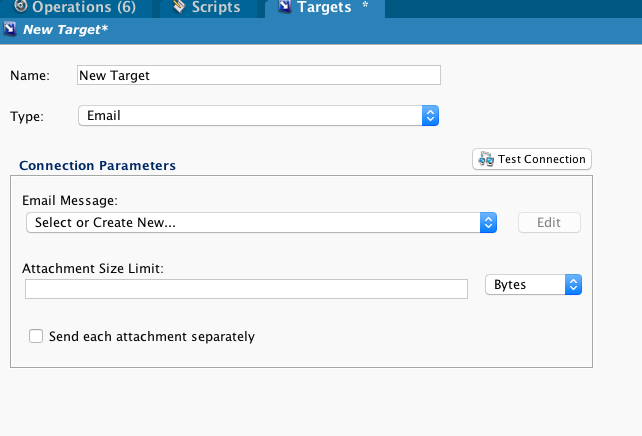
Agora você pode usar este destino de email para enviar a saída capturada.