Estruturas de Dados¶
Introdução¶
Estruturas de dados podem ser fornecidas como esquemas durante a configuração da atividade ou podem ser definidos dentro da transformação em si. Quando estruturas de dados são fornecidas em uma atividade, os esquemas são herdados pela transformação usando a atividade como uma origem ou destino na operação. Depois que os esquemas de origem e destino de uma transformação são definidos, você cria mapeamentos de transformação entre os esquemas de origem e destino para definir como os dados devem ser processados.
Tipos de Estrutura de Dados¶
No Harmony, os esquemas de origem e destino podem usar estruturas de dados que são consideradas planas ou hierárquico.
Estrutura Plana¶
Uma estrutura de dados plana consiste em um ou mais campos e registros únicos em uma estrutura bidimensional. Exemplos incluem arquivos CSV, arquivos XML simples e tabelas de banco de dados únicas. Uma estrutura de dados plana também é chamada de estrutura flat file.
<customer>
<id>10123</id>
<name>ABC Co.</name>
<street>1 Main St.</street>
<city>Anytown</city>
<state>NY</state>
<zip>12345</zip>
</customer>
Estrutura Hierárquica¶
Uma estrutura de dados hierárquica tem um ou mais relacionamentos pai-filho ou aninhados entre campos e registros em uma estrutura complexa. Uma estrutura de dados hierárquica é algumas vezes referida como uma estrutura relacional, multinível, dados complexos_ ou árvore.
<customer>
<id>10123</id>
<name>ABC Co.</name>
<addresses>
<address>
<street>1 Main St.</street>
<city>Anytown</city>
<state>NY</state>
<zip>12345</zip>
</address>
<address>
<street>1 Time Square</street>
<city>New York City</city>
<state>NY</state>
<zip>54321</zip>
</address>
</addresses>
</customer>
Exibição de Estruturas de Dados¶
As estruturas de dados são exibidas em um formato de árvore que pode ser expandido e recolhido para mostrar a árvore inteira ou apenas uma parte dela.
Cada árvore consiste em nós e campos, onde campos dentro da estrutura de dados de origem podem ser mapeados para campos dentro da estrutura de dados de destino.
Os nós têm um triângulo de divulgação à esquerda do nome do nó que é usado para recolher ou expandir o nó. Por padrão, os nós são expandidos até 8 níveis de profundidade para esquemas com 750 nós ou menos e até 5 níveis de profundidade para esquemas com mais de 750 nós. Todos os nós abaixo de um nó de destino podem ser expandidos de uma vez usando a opção de menu de ações do esquema Expandir todos os nós abaixo deste nó (consulte Nós de destino no modo de mapeamento). Se você expandir ou recolher nós, o Cloud Studio lembrará do último estado de expansão que você estava usando na próxima vez que acessar a transformação.
Uma vez expandidos, os nós exibem quaisquer nós filhos e campos contidos. Os nós podem ser considerados como pastas com nós filhos como subpastas. Os campos são contidos dentro dos nós e são listados com seu tipo de dados (boolean, integer, double, binary, string).
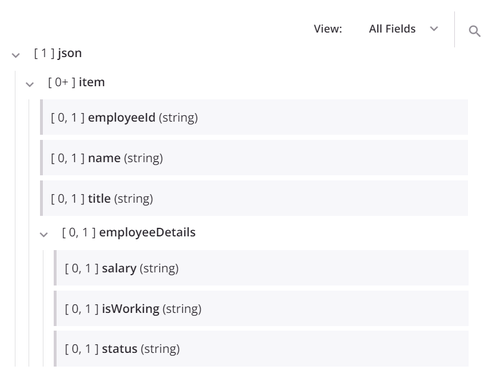
Por exemplo, na estrutura alvo mostrada abaixo, o nó json inclui o nó filho item, que contém os campos employeeId, name, e title. O nó item também contém o nó filho employeeDetails, que contém os campos salary, isWorking, e status.
Exibição de Campos Mapeados¶
Um mapeamento de transformação consiste em campos ou nós de destino e seus scripts correspondentes. Esses scripts podem conter referências a campos ou nós de origem ou a componentes do projeto, usar funções ou conter outra lógica de script válida. Um mapeamento não inclui campos de destino que não são mapeados.
Quando objetos de origem e variáveis são definidos dentro do campo de destino, eles aparecem como blocos dentro do campo de destino. O campo de destino mapeado é exibido com uma linha vertical roxa ao longo da esquerda do bloco do campo de destino:
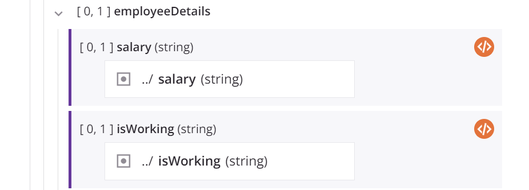
Quando você está no modo de mapeamento e um esquema de origem e um de destino estão visíveis na tela, uma linha cinza claro visual mostra a conexão com o objeto de origem quando você clica no bloco de um campo de destino ou passa o mouse sobre um campo de origem.
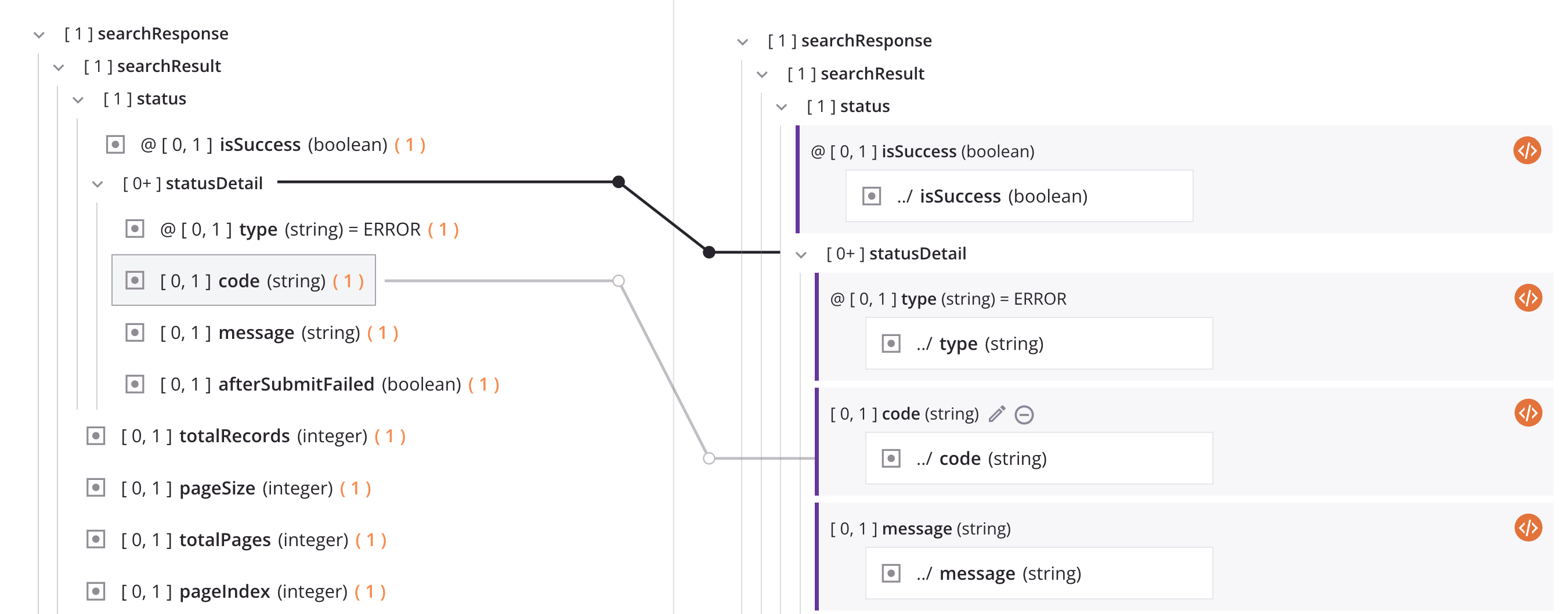
A linha preta sólida mostrada na imagem acima é explicada na próxima seção, Nós de loop.
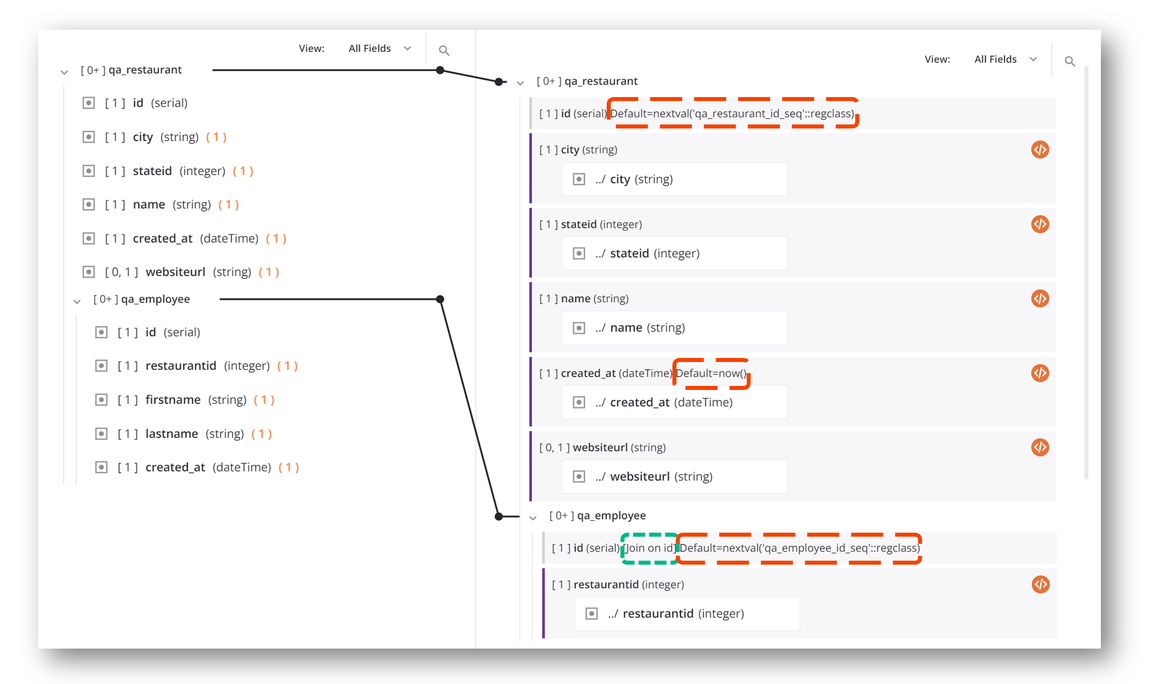
O lado alvo do mapeamento também indica se um campo tem algum valor padrão (destacado em vermelho na imagem abaixo) ou junções (destacado em verde na imagem abaixo). Por exemplo, essa transformação insere dados em um banco de dados cujo id campos são auto-incrementados e cujos created_at campo é definido como igual ao tempo atual por padrão. Ele também mostra que a tabela filha qa_employee foi unido no campo id à sua tabela pai qa_restaurant:
Se um nó recolhido contiver mapeamentos de campos de destino, esse nó será mostrado em negrito para indicar que contém mapeamentos:

Nós de Loop¶
Um nó de loop é um nó de origem ou de destino com valores de dados repetidos, como itens de linha em uma fatura ou um conjunto de registros de clientes.
Quando os campos do nó de loop são mapeados, uma linha iterator preta sólida aparece automaticamente, indicando que o processo de transformação fará um loop pelo conjunto de dados de origem. A localização das linhas do iterador geradas depende da multiplicidade dos nós de loop de origem correspondentes.
Uma transformação pode ter zero ou mais linhas de iterador. Quando várias linhas de iterador estão presentes, a precedência é dada de cima para baixo da estrutura de destino.
Para alternar a exibição de uma linha de iterador individual, clique diretamente no formato de círculo mais próximo do nó de destino:
![]()
A linha do nó de loop individual então se torna um toco laranja que, quando clicado novamente, exibe a linha completa:
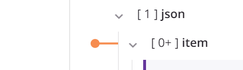
Exemplo¶
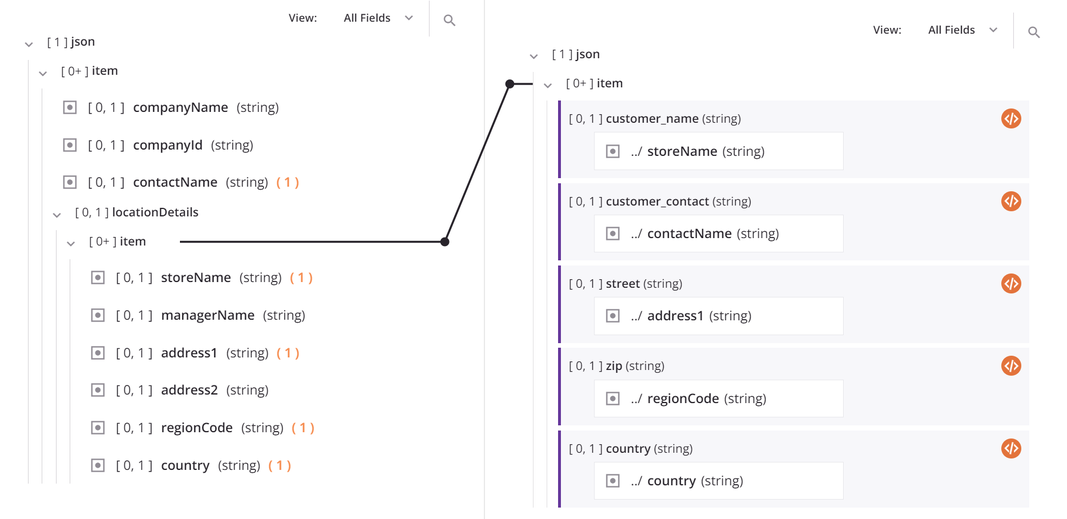
Como exemplo de um mapeamento de nó de loop, considere a seguinte estrutura de origem hierárquica contendo um nó de origem de nível superior (item) com campos que fornecem informações sobre uma empresa. Um nó de origem filho, locationDetails, inclui uma matriz (json$item.locationDetails$item.) de objetos com campos para vários locais de loja dentro de uma empresa. Tanto o nó pai quanto o filho são considerados nós de loop porque os dados podem conter vários registros de empresa com vários registros de local de loja para cada empresa.
Agora considere que esses dados estão sendo mapeados para uma estrutura de destino plana, resultando em um registro para cada local de loja. Conforme você mapeia campos, uma linha iteradora aparece automaticamente conectando os nós de loop de origem e destino. Essa linha indica que o destino fará um loop tantas vezes quanto houver conjuntos de dados repetidos na origem ou, neste exemplo, fará um loop por cada registro de local de loja para cada empresa.
Mapear de uma Fonte de Múltiplas Instâncias para um Destino de Instância Única¶
Quando o nó de loop de destino gerado depende de mais de um nó de loop de origem, pode ser necessário resolver um conflito de ocorrência múltipla com o mapeamento.
Se a estrutura de dados de origem for uma matriz de vários objetos e estiver sendo mapeada para uma estrutura de dados de destino com um único objeto, esta caixa de diálogo será exibida:
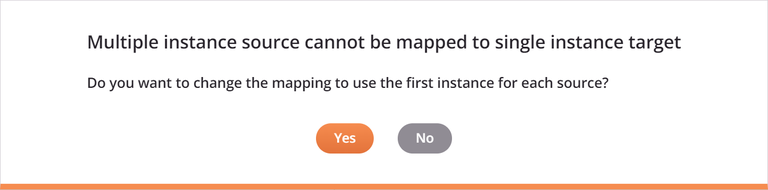
Para usar a primeira instância da origem no mapeamento, selecione Sim. Isso significa que somente o primeiro registro será mapeado. Por exemplo, dado o mapeamento a seguir, somente o primeiro registro de cliente na matriz é mapeado para a estrutura de destino contendo somente um único cliente. Observe que cada campo de destino mapeado agora contém um script, conforme indicado com o ícone de script.
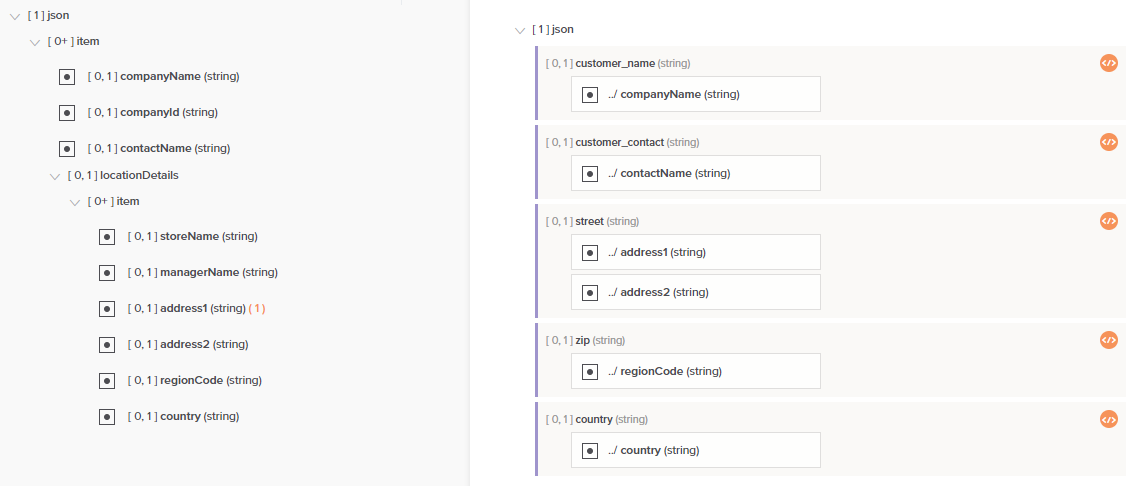
Ao alternar para o modo de script para qualquer campo mapeado, você verá que um #1 foi adicionado dentro do caminho do objeto de origem mapeado para indicar que a primeira instância é mapeada.
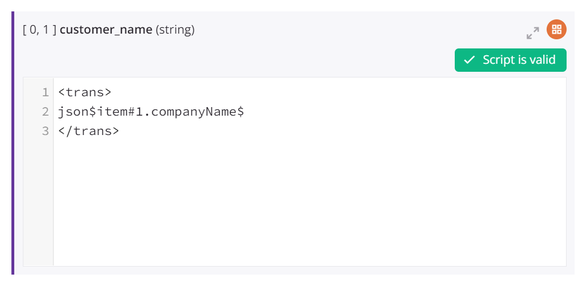
Se você não quiser que a primeira instância da fonte seja usada, você pode especificar outra lógica usando as funções de resolução de instância (veja Funções de instância).
Normalização de Dados¶
Se você estiver mapeando dados de uma estrutura plana para uma estrutura hierárquica, os dados podem precisar ser normalizados antes de serem transformados.
Por padrão, o Harmony usa um algoritmo de normalização para construir a árvore de destino. Isso converterá a estrutura plana da fonte em uma estrutura de fonte hierárquica que pode então ser mapeada para a estrutura de destino hierárquica.
Na estrutura de destino, o elemento raiz e todos os elementos de instâncias múltiplas sob a raiz são usados para criar a estrutura de elementos de origem secundários. Os atributos (ou campos) desses elementos de origem secundários são elementos de dados simples que são então usados nos mapeamentos do elemento de destino correspondente.
Com a estrutura de origem devidamente definida, o processo de normalização é simplificado para combinar nós com os mesmos pais.
Existem três opções para normalização:
- Normalização completa: Todos os elementos com o mesmo pai e todos os campos são reduzidos a um elemento. (Este é o padrão.)
- Normalização parcial: O mesmo que normalização completa, exceto que os filhos mais baixos não são normalizados.
- Sem normalização: Cada registro simples cria uma ramificação de elementos; nenhuma redução de elementos é realizada ao criar a estrutura de origem hierárquica.
É possível que a estrutura hierárquica contenha um único nó de instância. Nesse caso, apenas o primeiro elemento para essa raiz será mantido, e registros simples que conflitam com esse nó de dados raiz serão ignorados.
Para desabilitar a normalização, defina a variável Jitterbit jitterbit.transformation.disable_normalization para true (veja Variáveis Jitterbit de Transformação).
Mapeamento de Instância e Múltiplo¶
O mapeamento de Transformação é o processo usado para definir o relacionamento de dados entre entradas e uma saída resultante de dados. Dependendo de quais tipos de estrutura de dados são usados, o mapeamento de transformação pode ser descrito como mapeamento de instância ou mapeamento múltiplo.
Mapeamento de Instância¶
O mapeamento de instância descreve quando o mapeamento de uma instância de destino depende possivelmente de mais de uma instância de uma fonte. O mapeamento de instância pode ser plano para plano (um para um) ou hierárquico para plano (muitos para um).
Mapeamento Múltiplo¶
O mapeamento múltiplo descreve o mapeamento de duas estruturas de dados hierárquicas ou o mapeamento de uma única estrutura plana que é, na verdade, hierárquica por natureza, com seus segmentos inferiores contendo vários conjuntos de valores, como pares nome/valor. O mapeamento múltiplo pode ser hierárquico para hierárquico (muitos para muitos) ou plano para hierárquico (um para muitos).
Exemplos¶
Exemplos de situações para mapeamento de instâncias e múltiplos podem ser encontrados na documentação do Design Studio:
- Mapeamento de Instância
- Mapeamento múltiplo
Embora esses exemplos sejam para o Design Studio, os mesmos conceitos podem ser aplicados no Cloud Studio.
Para módulos de treinamento prático que têm exemplos de mapeamento de arquivos de banco de dados, texto e XML simples e complexos, consulte Introdução ao Harmony Cloud Studio.