Agente de Conocimiento Jitterbit
Descripción general
El Agente de Conocimiento Jitterbit (Agente de Conocimiento) es un agente de IA proporcionado a través del Mercado de Jitterbit que tiene como objetivo permitir que el equipo interno de su organización obtenga respuestas inteligentes a partir de los datos internos de su organización. Este agente utiliza la técnica de Generación Aumentada por Recuperación (RAG), que combina el razonamiento de LLM con acceso a herramientas externas y fuentes de datos. Realiza lo siguiente:
-
Se conecta y obtiene información de las siguientes fuentes utilizando Jitterbit Studio:
- Páginas de Atlassian Confluence
- Problemas de Atlassian Jira
- Documentos de Google Drive
- Casos de soporte de Salesforce (del objeto
Case)
-
Se integra con Azure OpenAI para potenciar un chatbot inteligente de IA utilizando datos de las fuentes mencionadas, accedidos a través de una API personalizada creada con Jitterbit API Manager.
Este documento explica cómo configurar y operar este agente de IA. Cubre la arquitectura y los requisitos previos, ejemplos de solicitudes que muestran lo que el agente puede hacer, y pasos para instalar, configurar y operar el agente de IA.
Arquitectura del agente de IA
El siguiente diagrama representa la arquitectura implementada en el Agente de Conocimiento:
Flujo de datos del agente
Slack app/bot) JB_CUSTOM_API(
Jitterbit API Manager
custom API) REQ_AZURE_OPENAI(Request to
Azure OpenAI) SLACK_API_REQ_H(Slack
API request handler
workflow) RES_AZURE_OPENAI(Response from Azure OpenAI) TIMEOUT(Timeout handling) subgraph LIVE_AGENT_DATA_FLOW[ ] direction RL subgraph EXTAPP[**External app**] SLACKAPP end JB_CUSTOM_API subgraph STUDIO[ **Jitterbit Studio**] REQ_AZURE_OPENAI RES_AZURE_OPENAI SLACK_API_REQ_H TIMEOUT end end SLACKAPP -->|Request| JB_CUSTOM_API JB_CUSTOM_API -->|Request| SLACK_API_REQ_H JB_CUSTOM_API -->|Response| SLACKAPP SLACK_API_REQ_H -->|Response|JB_CUSTOM_API SLACK_API_REQ_H --> REQ_AZURE_OPENAI REQ_AZURE_OPENAI --> RES_AZURE_OPENAI RES_AZURE_OPENAI --> SLACK_API_REQ_H REQ_AZURE_OPENAI --> TIMEOUT --> SLACK_API_REQ_H classDef Clear fill:white, stroke:white, stroke-width:0px, rx:15px, ry:15px classDef Plain fill:white, stroke:black, stroke-width:3px, rx:15px, ry:15px class LIVE_AGENT_DATA_FLOW Clear class EXTAPP,APIM,STUDIO Plain
Carga inicial de datos y flujos de trabajo de mantenimiento de datos
Requisitos previos
Para utilizar el Agente de Conocimiento, se requieren o asumen los siguientes componentes en el diseño del agente.
Componentes de Harmony
Debe tener una licencia de Jitterbit Harmony con acceso a los siguientes componentes:
- Jitterbit Studio
- Jitterbit API Manager
- Agente de Conocimiento Jitterbit adquirido como un complemento de licencia
Endpoints compatibles
Los siguientes endpoints están incorporados en el diseño del agente.
Modelo de lenguaje grande (LLM)
El agente de IA utiliza Azure OpenAI como proveedor de LLM. Para usar Azure OpenAI, debes tener una suscripción a Microsoft Azure con permisos para crear y gestionar los siguientes recursos:
- Recurso de Azure OpenAI con un modelo
gpt-4oogpt-4.1desplegado. - Almacenamiento de Azure con un contenedor Blob para almacenar datos recuperados.
- Búsqueda de IA de Azure con un servicio de búsqueda que se puede configurar con un índice y un indexador.
Consejo
Para información sobre precios, consulta los niveles de precios de Azure AI Search.
Base de conocimientos
Puedes usar cualquiera o todos estos endpoints como la base de conocimientos para este agente de IA:
- Atlassian Confluence: La fuente de las páginas de Confluence.
- Atlassian Jira: La fuente de los problemas de Jira.
- Google Drive: La fuente de archivos almacenados en una unidad compartida de Google.
- Salesforce: La fuente de tus casos de soporte al cliente del objeto
Case.
Interfaz de chat
El diseño del agente incorpora Slack como la interfaz de chat para interactuar con el agente de IA. Si deseas usar una aplicación diferente como la interfaz de chat, se incluye un flujo de trabajo separado e instrucciones para una configuración de API genérica en este agente de IA.
Ejemplos de solicitudes
Aquí hay ejemplos de solicitudes que el Agente de Conocimiento puede manejar con acceso a los datos apropiados. El agente puede encontrar información en cualquiera o todos los endpoints conectados.
- "Tengo un problema con el componente 'ABC'. ¿Puedes ayudarme con esto?"
- "¿Cómo puedo conectarme a una base de datos MySQL usando JDBC?"
- "¿Puedes darme detalles sobre el ticket de Jira número 123?"
- "¿Hay algún ticket de Jira relacionado con el conector SQL?"
- "¿Cuál es la política de seguridad para instalar software en mi computadora de trabajo?" (Puede haber un documento en Google Drive o una página de Confluence sobre este tema.)
Instalación, configuración y operación
Sigue estos pasos para instalar, configurar y operar este agente de IA:
- Descargar personalizaciones e instalar el proyecto de Studio.
- Revisar flujos de trabajo del proyecto.
- Crear recursos de Microsoft Azure.
- Crear la aplicación de Slack.
- Configurar una cuenta de servicio de Google y una unidad compartida.
- Configurar variables del proyecto.
- Probar conexiones.
- Desplegar el proyecto.
- Crear la API personalizada de Jitterbit.
- Revisar flujos de trabajo del proyecto.
- Activar los flujos de trabajo del proyecto.
- Solución de problemas.
Descargar personalizaciones e instalar el proyecto
Sigue estos pasos para descargar archivos de personalización e instalar el proyecto de Studio:
-
Inicia sesión en el portal de Harmony en https://login.jitterbit.com y abre Marketplace.
-
Localiza el agente de IA llamado Jitterbit Knowledge Agent. Para localizar el agente, puedes usar la barra de búsqueda o, en el panel de Filtros bajo Tipo, seleccionar Agente de IA para limitar la visualización a los agentes de IA disponibles.
-
Haz clic en el enlace de Documentación del agente de IA para abrir su documentación en una pestaña separada. Mantén la pestaña abierta para consultarla después de iniciar el proyecto.
-
Haz clic en Iniciar Proyecto para abrir un diálogo de configuración de dos pasos para descargar personalizaciones e importar el agente de IA como un proyecto de Studio.
Nota
Si aún no has comprado el agente de IA, se mostrará Obtener este agente en su lugar. Haz clic en él para abrir un diálogo informativo, luego haz clic en Enviar para que un representante se comunique contigo sobre la compra del agente de IA.
-
En el paso de configuración 1, Descargar Personalizaciones, se proporcionan los siguientes archivos para facilitar la configuración del índice y el indexador en Azure AI Search y para crear la aplicación de Slack. Selecciona los archivos y haz clic en Descargar Archivos:
-
Archivos de definición JSON del índice y el indexador de Azure AI Search
Azure_AI_Search_Datasource_Definition.jsonAzure_AI_Search_Index_Definition.jsonAzure_AI_Search_Indexer_Definition.json
-
Archivo de manifiesto de la aplicación de Slack
slack_app_manifest.json
Consejo
El cuadro de diálogo de configuración incluye una advertencia de no importar la plantilla antes de aplicar las personalizaciones del punto final. Esa advertencia no se aplica a este agente de IA y se puede ignorar. Sigue el orden recomendado de los pasos en esta documentación.
Haz clic en Siguiente.
-
-
En el paso de configuración 2, Crear un Nuevo Proyecto, selecciona un entorno donde deseas crear el proyecto de Studio, luego haz clic en Crear Proyecto.
-
Se muestra un cuadro de diálogo de progreso. Después de que indique que el proyecto ha sido creado, utiliza el enlace del cuadro de diálogo Ir a Studio o abre el proyecto directamente desde la página de Proyectos de Studio.
Crear recursos de Microsoft Azure
Crea los siguientes recursos de Microsoft Azure y retén la siguiente información para configurar el agente de IA. Para crear y gestionar estos recursos, debes tener una suscripción de Microsoft Azure con los permisos apropiados.
Contenedor de Blob de Azure
Debes crear un contenedor de Blob de Azure para almacenar los detalles del cliente. Los datos del contenedor de Blob se indexarán en Azure AI Search utilizando un índice y un indexador.
Necesitarás la URL SAS del contenedor para usarla en la determinación de los valores de las variables del proyecto de Azure Blob Storage. Para generar la URL SAS:
- En el portal de Azure, navega a Cuentas de almacenamiento y abre la cuenta de almacenamiento específica.
- En el menú de recursos bajo Almacenamiento de datos, selecciona Contenedores y abre el contenedor específico.
- En el menú de recursos bajo Configuración, selecciona Tokens de acceso compartido.
-
Utiliza el menú de Permisos para verificar que la URL de la firma de acceso compartido (SAS) para este contenedor tenga un mínimo de permisos de Lectura y Escritura:
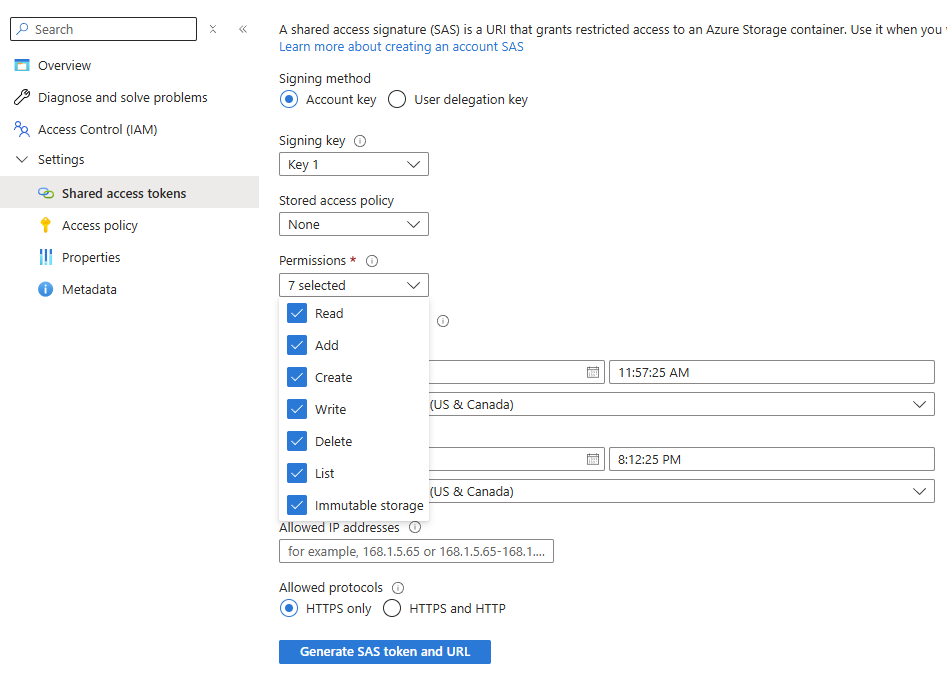
-
Haz clic en Generar token y URL SAS.
- Copia la URL SAS de Blob que se muestra en la parte inferior.
- Determina los valores de las variables del proyecto de Azure Blob Storage a partir de la URL SAS. La URL SAS tiene el formato
{{ azure_blob_base_url }}/{{ Azure_Blob_Container_Name }}?{{ azure_blob_sas_token }}.
Si utilizas los archivos de definición JSON incluidos en los archivos de personalización del agente de IA para generar el índice y el indexador, también necesitarás la clave de cuenta de Azure Blob Storage. Para ver las claves de acceso a la cuenta:
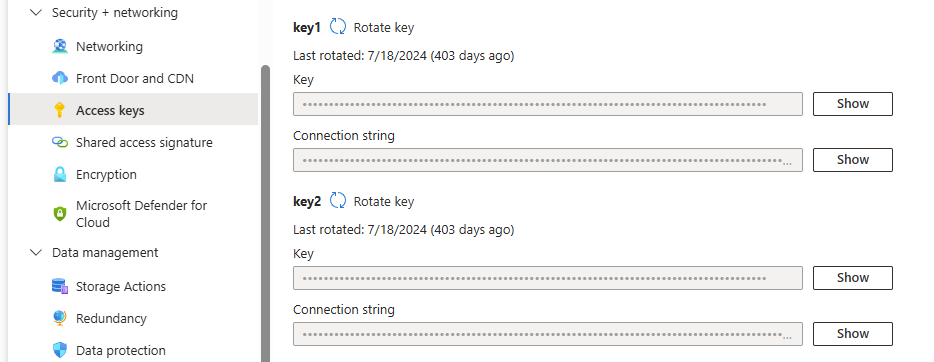
- En el portal de Azure, navega a Cuentas de almacenamiento y abre la cuenta de almacenamiento específica.
- En el menú de recursos, bajo Seguridad + redes, selecciona Claves de acceso.
-
Haz clic en Mostrar claves para revelar la clave de acceso que se utilizará durante la configuración de Azure AI Search.
Servicio de búsqueda de Azure AI
Debes crear un servicio de búsqueda de Azure AI y configurar su índice y indexador para procesar los datos del contenedor Blob.
Necesitarás la URL del servicio de búsqueda de Azure AI y la clave API para determinar los valores de las variables del proyecto de Azure AI Search:
- URL: Para obtener el valor que se utilizará para
azure_ai_search_url, consulta la documentación de Azure Obtener información del servicio. - Clave API: Para obtener el valor que se utilizará para
azure_ai_search_api_key, consulta la documentación de Azure Configurar acceso basado en roles.
Puedes utilizar los archivos de definición JSON incluidos en los archivos de personalización del agente de IA para generar el índice y el indexador, o puedes crearlos tú mismo.
Si utiliza los archivos de definición proporcionados, debe reemplazar los siguientes marcadores de posición con sus propios valores de configuración:
Azure_AI_Search_Indexer_Definition.json
| Marcador de posición | Descripción |
|---|---|
{{Su nombre del servicio de búsqueda de Azure AI}} |
El nombre del servicio de búsqueda de Azure AI. |
Azure_AI_Search_Datasource_Definition.json
| Marcador de posición | Descripción |
|---|---|
{{Su nombre del servicio de búsqueda de Azure AI}} |
El nombre del servicio de búsqueda de Azure AI. |
{{Su nombre de cuenta de Blob de Azure}} |
El nombre de la cuenta de Blob de Azure. |
{{Su clave de cuenta de Blob de Azure}} |
La clave de acceso para la cuenta de almacenamiento de Blob de Azure, obtenida como se describe en contenedor de Blob de Azure arriba. |
{{su_nombre_de_contenedor_blob_de_azure}} |
El nombre del contenedor de Blob de Azure. |
Recurso de Azure OpenAI
Debe crear un recurso de Azure OpenAI y desplegar un modelo gpt-4o o gpt-4.1 a través del portal de Azure AI Foundry.
Necesitará el nombre del despliegue, la URL del endpoint de Azure OpenAI y la clave API para determinar los valores de las variables del proyecto de Azure OpenAI. Para encontrar estos valores:
- En el portal de Azure AI Foundry, abra el recurso específico de OpenAI.
-
Los valores a utilizar para la URL del endpoint (
azure_openai_base_url) y la clave API (azure_openai_api_key) se muestran en la página de inicio del recurso: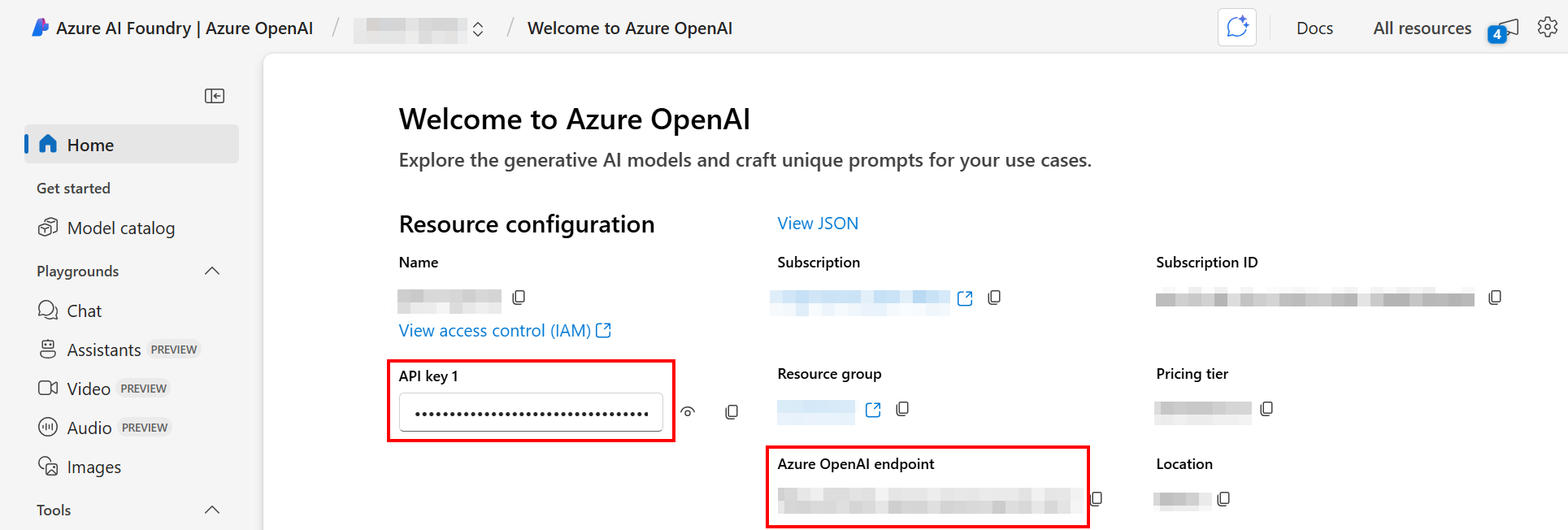
-
En el menú de navegación bajo Recursos compartidos, selecciona Despliegues. Se muestra el nombre del despliegue (
Azure_OpenAI_Deployment_Name).
Crear la aplicación de Slack
Para crear la interfaz de chat del Agente de Conocimiento en Slack, sigue estos pasos:
-
Crea una aplicación de Slack utilizando el archivo de manifiesto de la aplicación de Slack (
slack_app_manifest.json) proporcionado con los archivos de personalización de este agente de IA. Alternativamente, crea la aplicación desde cero. -
Si utilizas el archivo de manifiesto proporcionado, reemplaza los siguientes marcadores de posición con tus propios valores de configuración:
Marcador de posición Descripción {{Reemplazar con el nombre del bot de Slack}}El nombre que deseas que tenga tu bot de Slack, tal como se muestra a los usuarios. Reemplaza este valor en dos lugares en el manifiesto. {{Reemplazar con la URL de la API de Jitterbit}}La URL del servicio de la API personalizada de Jitterbit que creaste en Crear la API personalizada de Jitterbit. -
Instala la aplicación en tu espacio de trabajo de Slack.
-
Obtén el token del bot (para el campo Token OAuth de Usuario del Bot de la conexión de Slack) e ingresa su valor para la variable de proyecto
slack_bot_oauth_user_token. -
Configura la variable de proyecto
slack_channel_namecon el canal donde se deben enviar las notificaciones. -
Ingresa el valor del token del bot para la variable de proyecto
slack_bot_oauth_user_tokeny el nombre del canal para la variable de proyectoslack_channel_name. Configurarás estos en el siguiente paso.
Configurar una cuenta de servicio de Google y una unidad compartida
Esta configuración es necesaria solo si estás utilizando el flujo de trabajo Data upload Utility - Google Drive to Azure Blob. Debes tener un proyecto activo de Google Cloud para continuar. Si no tienes uno, puedes crear uno siguiendo las instrucciones de Google.
Crear una cuenta de servicio de Google
Sigue los pasos a continuación para crear una clave para la cuenta de servicio de Google que permita a la utilidad acceder de forma segura a tus archivos de Google Drive:
-
En la consola de Google Cloud, utiliza la barra de búsqueda para encontrar y navegar a la página de Cuentas de servicio.
-
Si ya tienes una cuenta de servicio que deseas usar, procede al paso 3. De lo contrario, haz clic en Crear cuenta de servicio, proporciona un nombre y haz clic en Listo. No se necesitan permisos o accesos adicionales.
-
Selecciona la cuenta de servicio para abrir sus Detalles de la cuenta de servicio:
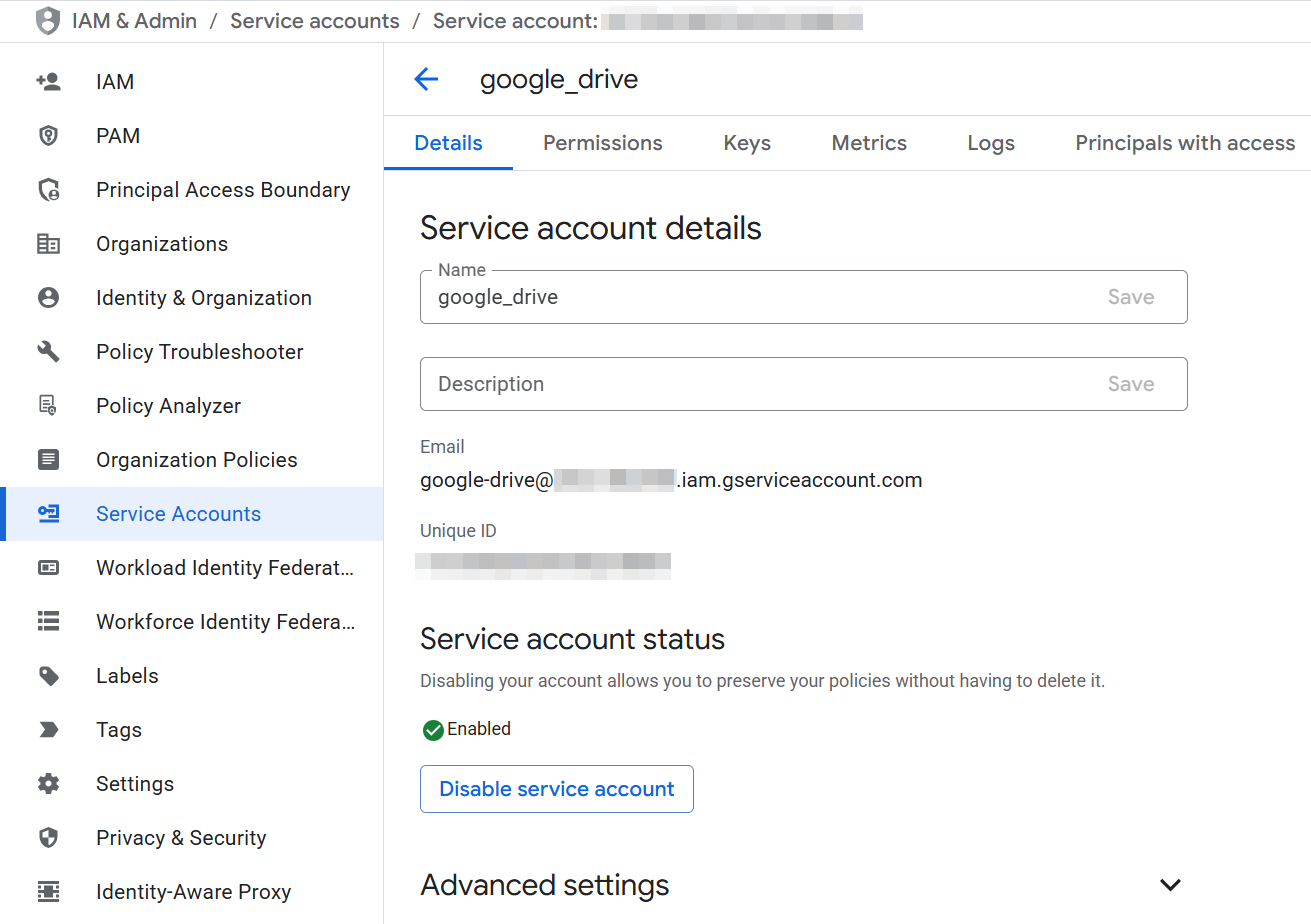
-
Navega a la pestaña de Claves y utiliza el menú Agregar clave para seleccionar Crear nueva clave.
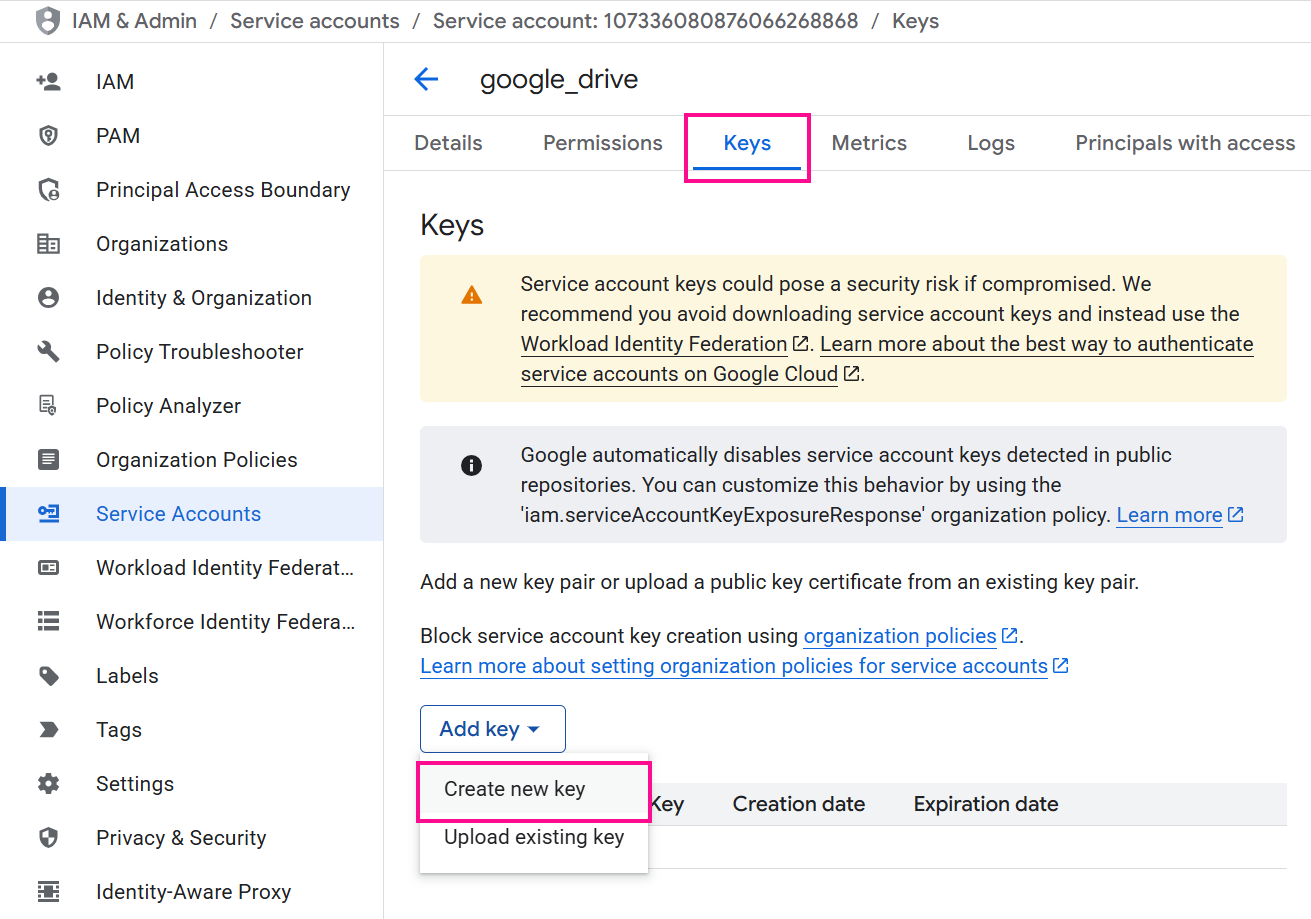
-
Elige JSON como el tipo de clave y haz clic en Crear. Se descargará un archivo JSON que contiene las credenciales en tu computadora.
-
Abre el archivo JSON descargado para encontrar los siguientes valores necesarios para configurar las variables del proyecto de Google Drive:
client_email: Este es el valor para la variable del proyectoGoogle_Client_Emaily necesario para configurar la unidad compartida de Google en la siguiente sección.private_key: Este es el valor para la variable del proyectoGoogle_Private_Key.
-
Habilita la API de Google Drive en tu cuenta de Google Cloud:
-
En la consola de Google Cloud, utiliza la barra de búsqueda para encontrar y navegar a la página de APIs y Servicios.
-
Accede a la API Library y selecciona la API de Google Drive:
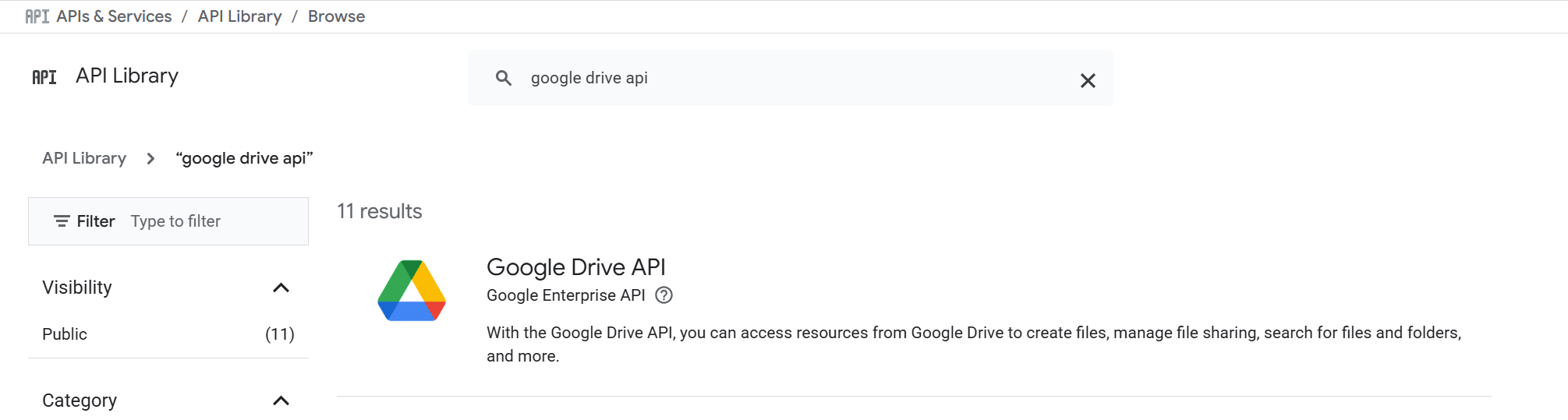
-
Haz clic en el botón Enable:

-
Configurar la unidad compartida de Google
La unidad compartida de Google debe configurarse de la siguiente manera para permitir que la utilidad acceda a cualquier archivo que subas a ella:
-
Crea una unidad compartida de Google si aún no tienes una.
-
Abre la unidad compartida y copia su ID de la URL del navegador. El ID es la larga cadena de caracteres al final. Por ejemplo, si la URL es
https://drive.google.com/drive/folders/dftg-LbGrP7hdfd, el ID esdftg-LbGrP7hdfd. Este ID es el valor para la variable de proyectoGoogle_Drive_IDal configurar variables de proyecto de Google Drive. -
Haz clic en el nombre de la unidad compartida en la parte superior de la página y selecciona Manage members. Aparece un diálogo.
-
En el campo Add people and groups, pega el valor de
client_emaildel archivo JSON que descargaste anteriormente. -
Asigna el rol de Content manager a la cuenta de servicio y confirma la acción.
Configurar variables de proyecto
En el proyecto de Studio instalado anteriormente a través de Marketplace, debes establecer valores para las siguientes variables de proyecto.
Esto se puede hacer utilizando el menú de acciones del proyecto para seleccionar Project Variables y abrir un panel en la parte inferior de la página donde puedes revisar y establecer los valores.
Salesforce
| Nombre de la variable | Descripción |
|---|---|
SF_Login_URL |
Servidor Host en la conexión de Salesforce |
SF_Password |
Contraseña en la conexión de Salesforce |
SF_Security_Token |
Token de seguridad en la conexión de Salesforce |
SF_User_Name |
Nombre de usuario en la conexión de Salesforce |
SF_Cases_Incremental_Run |
Bandera para controlar si se deben obtener solo los casos de Salesforce nuevos o actualizados desde la última ejecución. Cuando es true, solo se obtienen casos incrementales (nuevos o actualizados) de Salesforce desde la última ejecución. Cuando es false, se realiza una obtención completa desde la fecha y hora predeterminadas (SF_Cases_Default_Modified_Date). |
SF_Cases_Default_Modified_Date |
La fecha y hora predeterminadas desde las cuales se obtienen los casos de Salesforce. Se utiliza durante la primera ejecución o cuando SF_Cases_Incremental_Run es false. Formato: yyyy-MM-dd'T'HH:mm:ss.SSS'Z'. Ejemplo: 2024-09-11T13:00:02.000Z. Si esta fecha no se establece, se generará un error. |
Jira
| Nombre de variable | Descripción |
|---|---|
JIRA_Username |
La dirección de correo electrónico asociada con la cuenta de Jira para la autenticación. |
JIRA_Token |
Token de API utilizado para autenticarse con la instancia de JIRA. Para Atlassian Cloud, puedes generar este token desde la configuración de tu cuenta. |
JIRA_Projects |
Claves de proyectos de Jira para obtener problemas, utilizando el formato keys=PROJECT1&keys=PROJECT2. Ejemplo: keys=SUPPORT&keys=ITHELP. |
JIRA_Issue_Types |
Lista de tipos de problemas de Jira a obtener, separados por comas. Cada valor debe estar entre comillas simples. Ejemplo: 'Story','Bug','Task'. |
Jira_Default_Modified_Date |
La fecha y hora predeterminadas desde las cuales se obtienen los problemas de Jira. Se utiliza durante la primera ejecución o cuando JIRA_IncrementalRun es false. Formato: yyyy-MM-dd HH:mm. Ejemplo: 2025-08-07 10:00. Si esta fecha no se establece, se generará un error. |
JIRA_Incremental_Run |
Indicador para controlar si se deben obtener solo problemas nuevos o actualizados de Jira desde la última ejecución. Cuando es true, solo se obtienen problemas incrementales (nuevos o actualizados) de Jira desde la última ejecución. Cuando es false, se realiza una obtención completa desde la fecha y hora predeterminadas (Jira_Default_Modified_Date). |
JIRA_Base_URL |
La URL base de la instancia de Jira a la que conectarse. No incluyas una barra diagonal al final. Ejemplo: https://yourdomain.atlassian.net. |
Confluence
| Nombre de variable | Descripción |
|---|---|
Confluence_Wiki_UserName |
El nombre de usuario del wiki de Confluence. |
Confluence_Wiki_Password |
La contraseña del wiki de Confluence. |
Confluence_Wiki_Base_Url |
La URL raíz del wiki de Confluence para llamadas a la API y recuperación de contenido. Ejemplo: https://yourcompany.atlassian.net/wiki. |
Google Drive
| Nombre de variable | Descripción |
|---|---|
Google_Client_Email |
El correo electrónico del cliente de la cuenta de servicio de Google utilizado para la autenticación al acceder a Google Drive. |
Google_Drive_Default_Modified_Date |
La fecha y hora predeterminadas a partir de las cuales se leen los archivos de Google Drive. Se utiliza durante la primera ejecución o cuando la lectura incremental está desactivada. Formato: yyyy-MM-dd'T'HH:mm:ss. Ejemplo: 2024-05-28T11:32:47. Si esta fecha no se establece, se generará un error. |
Google_Drive_ID |
El ID de la unidad compartida de Google desde la cual se leerán los archivos. Por ejemplo, si la URL de la unidad compartida es https://drive.google.com/drive/folders/1KTXaKx_FG7Ud8sWHf8QgG67XHy, el ID de la unidad es 1KTXaKx_FG7Ud8sWHf8QgG67XHy. |
Google_Drive_Incremental_Run |
Indicador para controlar si se deben recuperar solo archivos nuevos o actualizados de Google Drive desde la última ejecución. Cuando es true, solo se recuperan archivos incrementales (nuevos o actualizados) de Google Drive desde la última ejecución. Cuando es false, se realiza una recuperación completa desde la fecha y hora predeterminadas (Google_Drive_Default_Modified_Date). |
Google_Oauth_Scopes |
El alcance de OAuth requerido para otorgar a la cuenta de servicio de Google acceso a Google Drive. Para este agente de IA, ingrese: https://www.googleapis.com/auth/. |
Google_Private_Key |
La clave privada de la cuenta de servicio de Google Cloud utilizada para autenticar la recuperación de archivos de Google Drive. |
Almacenamiento de Blob de Azure
| Nombre de variable | Descripción |
|---|---|
Azure_Blob_Container_Name |
El nombre del contenedor de Almacenamiento de Blob de Azure donde se almacenan o recuperan los datos obtenidos. Esta es la parte de la URL SAS que sigue inmediatamente al dominio de la cuenta de almacenamiento. Ejemplo: En https://myaccount.blob.core.windows.net/mycontainer/myblob.txt?sv=..., el nombre del contenedor es mycontainer. |
azure_blob_sas_token |
El token SAS utilizado para autenticar el acceso al contenedor de Blob de Azure Azure_Blob_Container_Name. Solo se debe almacenar la parte después de ? en la URL completa del blob. Ejemplo de token: sv=2025-08-01&ss=b&srt=sco&sp=rl&se=2025-08-30T12:00:00Z&st=2025-08-25T12:00:00Z&spr=https&sig=AbCdEfGhIjKlMnOpQrStUvWxYz1234567890. |
azure_blob_base_url |
La URL base de la cuenta de Almacenamiento de Blob de Azure utilizada para acceder a contenedores y blobs. En una URL SAS como https://myaccount.blob.core.windows.net/mycontainer/myblob.txt?sv=..., la URL base es https://myaccount.blob.core.windows.net/. |
Consejo
Estos valores se pueden derivar de la URL SAS, que tiene el formato de {{azure_blob_base_url}}/{{Azure_Blob_Container_Name}}?{{azure_blob_sas_token}}.
Búsqueda de AI de Azure
| Nombre de variable | Descripción |
|---|---|
Azure_AI_Search_Index_Name |
El nombre del índice de Azure que almacena la información del cliente de los formularios de pedido. |
azure_ai_search_indexer |
El nombre del indexador de Búsqueda de AI de Azure utilizado para poblar y actualizar el índice de búsqueda Azure_AI_Search_Index_Name. |
azure_ai_search_url |
La URL del endpoint de su servicio de Búsqueda de AI de Azure. No incluya una barra diagonal al final. Ejemplo: https://<your-search-service>.search.windows.net. |
azure_ai_search_api_key |
La clave API utilizada para autenticar las solicitudes a la Búsqueda de AI de Azure. |
Azure OpenAI
| Nombre de variable | Descripción |
|---|---|
Azure_OpenAI_Deployment_Name |
El nombre del despliegue de Azure OpenAI utilizado para acceder al modelo. |
azure_openai_base_url |
La URL base para acceder al servicio de Azure OpenAI. Ejemplo: https://<tu-nombre-de-recurso>.openai.azure.com. |
azure_openai_api_key |
La clave API utilizada para autenticar solicitudes al servicio de Azure OpenAI. |
Slack
| Nombre de variable | Descripción |
|---|---|
Slack_Bot_Token |
El token del bot de Slack que se obtiene después de crear la aplicación de Slack, utilizado para el token de acceso OAuth del usuario Bot en la conexión de Slack. |
Nota
La aplicación de Slack se crea en un paso posterior. Por ahora, puedes dejar esta variable en blanco.
Común
| Nombre de variable | Descripción |
|---|---|
html_regex |
Expresión regular para eliminar etiquetas HTML. Usa el valor predeterminado: <(?:"[^"]*"['"]*|'[^']*'['"]*|[^'">])+> |
AI_Prompt |
El texto de entrada o instrucción proporcionada al modelo de IA que guía cómo debe generar una respuesta. Para este agente, puedes usar el siguiente aviso:
|
Probar conexiones
Probar las configuraciones de los endpoints para verificar la conectividad utilizando los valores de las variables del proyecto definidas.
Para probar conexiones, ve a la pestaña Endpoints y conectores del proyecto en la paleta de componentes de diseño, pasa el cursor sobre cada endpoint y haz clic en Probar.
Desplegar el proyecto
Desplegar el proyecto de Studio.
Para desplegar el proyecto, utiliza el menú de acciones del proyecto para seleccionar Desplegar.
Desplegar el proyecto
Desplegar el proyecto de Studio. Esto se puede hacer utilizando el menú de acciones del proyecto para seleccionar Desplegar.
Crear la API personalizada de Jitterbit
Crear una API personalizada utilizando API Manager para uno de los siguientes:
- Controlador de solicitudes de API de Slack bot: Requerido si se utiliza la notificación de Slack incluida en el diseño de este agente de IA.
- Controlador de solicitudes de API genérico: Opcional. Utilizar para manejar solicitudes de API de cualquier aplicación.
Crear el controlador de solicitudes de API de Slack bot
Esta API personalizada de Jitterbit activará la operación Controlador de solicitudes de API de Slack Bot. Configura y publica la API personalizada con los siguientes ajustes:
- Servicio API:
Controlador de solicitudes de API de Slack Bot - Ruta:
/ - Proyecto: Selecciona el proyecto de Studio creado a partir del
Agente de Conocimiento de Jitterbiten Marketplace - Operación a activar:
Controlador de solicitudes de API de Slack Bot - Método:
POST - Tipo de respuesta:
Variable del sistema
Conserva la URL del servicio de la API publicada para usarla en la creación de la aplicación de Slack. La URL del servicio se puede encontrar en el panel de detalles de API en la pestaña Servicios al pasar el cursor sobre la columna Acciones del servicio y hacer clic en Copiar URL del servicio API.
Manejador de solicitudes API genérico
Esta API personalizada de Jitterbit activará la operación Manejador de solicitudes API genérico. No es obligatorio. Crea esta API si estás utilizando otras aplicaciones para procesar solicitudes API HTTP. Configura y publica la API personalizada con los siguientes ajustes:
- Nombre del servicio:
Manejador de solicitudes API genérico - Proyecto: Selecciona el proyecto de Studio creado a partir del
Agente de Conocimiento Jitterbiten Marketplace - Operación:
Manejador de solicitudes API genérico - Método:
POST - Tipo de respuesta:
Variable del sistema
Consejo
También puedes agregar un perfil de seguridad para autenticación.
{
"username": "johnr",
"prompt": "How to connect to mysql using a connector?"
}
{
"message": "To connect to a MySQL database using the Database connector, follow these steps: - Use the MySQL JDBC driver that ships with the agent for additional features like manual queries.",
"references": [],
"status_code": 200
}
Revisar flujos de trabajo del proyecto
En el proyecto de Studio abierto, revisa los flujos de trabajo junto con las descripciones a continuación para entender qué hacen.
Nota
Los primeros cuatro flujos de trabajo son flujos de trabajo de Utilidad de carga de datos cuyo propósito es obtener datos que se utilizarán como base de conocimiento para el agente de IA. Puedes usar cualquiera o todos estos flujos de trabajo para obtener datos. Se requiere al menos una fuente como base de conocimiento para el agente de IA.
Estos flujos de trabajo deben ejecutarse primero para cargar conocimiento en el agente antes de interactuar con él. Puedes configurar un horario para obtener datos actualizados de manera regular según tus requisitos. Esto se puede hacer desde el menú de acciones de la primera operación en Configuración > Horarios.
-
Utilidad de carga de datos - Ticket de JIRA a Índice de Azure
Este flujo de trabajo obtiene problemas de Jira, luego ejecuta el flujo de trabajo
Utilidad - Carga de datos de Azure e Índicepara cargar problemas en Azure Blob Storage e indexarlos en el índice de búsqueda de Azure AI.La operación inicial es
Principal - Carga de tickets de JIRA. Se obtienen los siguientes campos:"fields": [ "summary", "status", "assignee", "description", "reporter", "created", "updated", "priority", "issuetype", "components", "comment" ]Este flujo de trabajo se puede configurar para obtener todos los problemas, o solo los problemas nuevos y actualizados, utilizando las variables del proyecto de Jira.
-
Utilidad de carga de datos - Casos de SF a índice de Azure
Este flujo de trabajo recupera casos de soporte de Salesforce, luego ejecuta el flujo de trabajo
Utility - Azure Data Upload and Indexpara cargar casos en Azure Blob Storage e indexarlos en el índice de Azure AI Search.La operación inicial es
Main - SF Cases Upload.En la configuración de la actividad de consulta de Salesforce, la siguiente consulta recupera información de casos de soporte por agente. Si su organización de Salesforce no utiliza estos objetos y campos, o si la información de los casos de soporte se almacena en diferentes objetos y campos, este flujo de trabajo no funcionará correctamente. Personalice la consulta en este flujo de trabajo para alinearla con el modelo de datos de su organización de Salesforce:
SELECT Account.Name, Owner.Email, Owner.Name, (SELECT CreatedBy.Email, CreatedBy.Name, Id, CommentBody, CreatedDate, LastModifiedDate, LastModifiedBy.Email, LastModifiedBy.Name FROM CaseComments), Id, CaseNumber, CreatedDate, Description, LastModifiedDate, Origin, Priority, Reason, Status, Subject, Type, CreatedBy.Email, CreatedBy.Name, LastModifiedBy.Email, LastModifiedBy.Name FROM CaseEste flujo de trabajo se puede configurar para obtener todos los casos, o solo los casos nuevos y actualizados, utilizando las variables del proyecto de Salesforce.
-
Utilidad de carga de datos - Páginas de Confluence a índice de Azure
Este flujo de trabajo recupera páginas de Confluence, luego ejecuta el flujo de trabajo
Utility - Azure Data Upload and Indexpara cargar documentos en Azure Blob Storage e indexarlos en el índice de Azure AI Search.La operación inicial es
Main - Load Confluence Pages.Este flujo de trabajo obtiene todas las páginas de Confluence en cada ejecución.
-
Utilidad de carga de datos - Google Drive a Azure Blob
Este flujo de trabajo recupera archivos de Google Drive, luego ejecuta el flujo de trabajo
Utility - Azure Data Upload and Indexpara indexarlos en el índice de Azure AI Search.La operación inicial es
Main - Google Drive Upload.Los tipos de archivos compatibles incluyen Google Docs, Google Spreadsheets y aquellos compatibles con la indexación de blobs de Azure Storage.
Los tamaños máximos de archivo compatibles se enumeran como el tamaño máximo de blob en los límites del indexador de Azure AI Search para su nivel de servicio de búsqueda AI. Por ejemplo, para el nivel básico, el límite es de 16 MB; para S1, el límite es de 128 MB.
Este flujo de trabajo se puede configurar para obtener todos los archivos, o solo archivos nuevos y actualizados, utilizando las variables del proyecto de Google Drive.
-
Utilidad - Carga de Datos en Azure e Indexación
Este es un flujo de trabajo de utilidad común utilizado por los flujos de trabajo de
Carga de Datos Utilitypara cargar datos en Azure Blob Storage e indexarlos en Azure AI Search. -
Entrada Principal - Manejador de Solicitudes de API de Slack
Este flujo de trabajo gestiona las solicitudes entrantes del bot de Slack. Se activa a través de una API personalizada de Jitterbit cada vez que su equipo interactúa con la interfaz de chat del bot de Slack (es decir, envía un mensaje de Slack). La configuración de la API personalizada de Jitterbit se describe en Crear la API personalizada de Jitterbit más adelante en esta página.
Si no está utilizando Slack, este flujo de trabajo se puede ignorar y no se activará. Para usar una interfaz de chat diferente para que su equipo interactúe, utilice el flujo de trabajo
Manejador de Solicitudes de API Genérico, que también se activa a través de una API personalizada de Jitterbit. -
Manejador de Solicitudes de API Genérico
Este flujo de trabajo procesa solicitudes de API HTTP de cualquier aplicación. Para integrarse con sus aplicaciones, cree una API personalizada de Jitterbit que active la operación
Manejador de Solicitudes de API Genérico. La URL de esta API puede ser utilizada por cualquier aplicación para enviar y recibir solicitudes.La configuración de la API personalizada de Jitterbit se describe en Crear la API personalizada de Jitterbit más adelante en esta página.
Activar los flujos de trabajo del proyecto
Para la carga inicial de datos, ejecute cualquiera o todos los flujos de trabajo de Carga de Datos Utility dependiendo de sus fuentes de datos. Esto se puede hacer utilizando la opción Ejecutar del operación inicial que se muestra al pasar el cursor sobre la operación. Necesitará ejecutar la operación nuevamente en el futuro si sus datos se actualizan.
Consejo
Puede que desee programar las operaciones iniciales en los flujos de trabajo de Carga de Datos Utility en un horario para obtener datos actualizados de manera regular. Esto se puede hacer desde el menú de acciones de la operación en Configuración > Horarios.
Los otros dos flujos de trabajo principales son activados por las API personalizadas de Jitterbit:
-
Main Entry - Slack API Request Handler: Este flujo de trabajo se activa desde Slack a través de la API personalizadaSlack Bot API Request Handler. Enviar un mensaje directo a la aplicación de Slack iniciará el disparador de la API personalizada. -
Generic API Request Handler: Este flujo de trabajo se activa desde otra aplicación a través de la API personalizadaGeneric API request Handler. Enviar una solicitud a la API configurada iniciará el disparador de la API personalizada.
Todos los demás flujos de trabajo son activados por otras operaciones y dependen de los mencionados anteriormente. No están destinados a ejecutarse por sí solos.
Solución de problemas
Si encuentras problemas, revisa los siguientes registros para obtener información detallada sobre la solución de problemas:
Para asistencia adicional, contacta a soporte de Jitterbit.