Dividir un archivo en registros individuales usando SCOPE_CHUNK en Jitterbit Studio
Introducción
Este patrón de diseño se puede utilizar para dividir los datos en un archivo de múltiples registros en múltiples archivos, cada uno conteniendo un solo registro, utilizando la sintaxis del prefijo SCOPE_CHUNK de la función Set.
Consejo
Este patrón se recomienda cuando los datos de origen son planos (no jerárquicos) y la operación no contiene una transformación que utilice lógica condicional. Para datos de origen complejos (jerárquicos), consulte Dividir un archivo en registros individuales usando SourceInstanceCount.
Caso de uso
En este escenario, los datos de origen contienen múltiples registros, y el proceso de negocio o el punto final de destino requieren que los registros sean procesados individualmente.
Patrón de diseño
Este patrón de diseño consiste en leer el archivo utilizando una operación donde la transformación utiliza el mismo esquema de origen y destino. Este patrón tiene las siguientes características clave:
- En el primer campo de la transformación que procesa los datos, se utiliza la función
Setpara establecer una variable que comienza conSCOPE_CHUNKseguida de texto adicional para construir el nombre de la variable. El primer argumento construye el nombre del archivo de salida, típicamente utilizando un identificador de registro de los datos de origen. Los nombres de archivo deben ser únicos para evitar ser sobrescritos, por lo que se puede utilizar un contador de registros o un GUID como parte del nombre del archivo. - Se debe utilizar un destino de almacenamiento de archivos como Almacenamiento Temporal o Almacenamiento Local. (No se admite el uso de una Variable.) Se recomienda definir una ruta. El nombre del archivo debe configurarse con el nombre de la variable global utilizada en la función
Set. - Las opciones de operación deben configurarse con Habilitar Fragmentación seleccionada, con un Tamaño de Fragmento de
1, Número de Registros por Archivo de1, y Número Máximo de Hilos de1. - Durante el tiempo de ejecución, cada registro será leído y asignado un nombre de archivo único, y escrito individualmente en el destino.
Después de usar este patrón, típicamente el siguiente paso es utilizar la función FileList para obtener el array de nombres de archivo en el directorio (configurar la actividad de Lectura del directorio de archivos con el comodín *), luego recorrer el array y leer cada archivo en la fuente para la siguiente operación.
Ejemplos
Se proporcionan ejemplos utilizando el patrón de diseño descrito anteriormente para dos tipos diferentes de datos de origen: un archivo CSV plano y un archivo JSON jerárquico.
CSV Plano
Esta cadena de operación aplica el patrón de diseño descrito anteriormente para dividir datos CSV planos en un archivo para cada registro. Cada número corresponde con una descripción del paso de operación a continuación. Para detalles adicionales, consulte las capturas de pantalla del ejemplo de JSON Jerárquico.
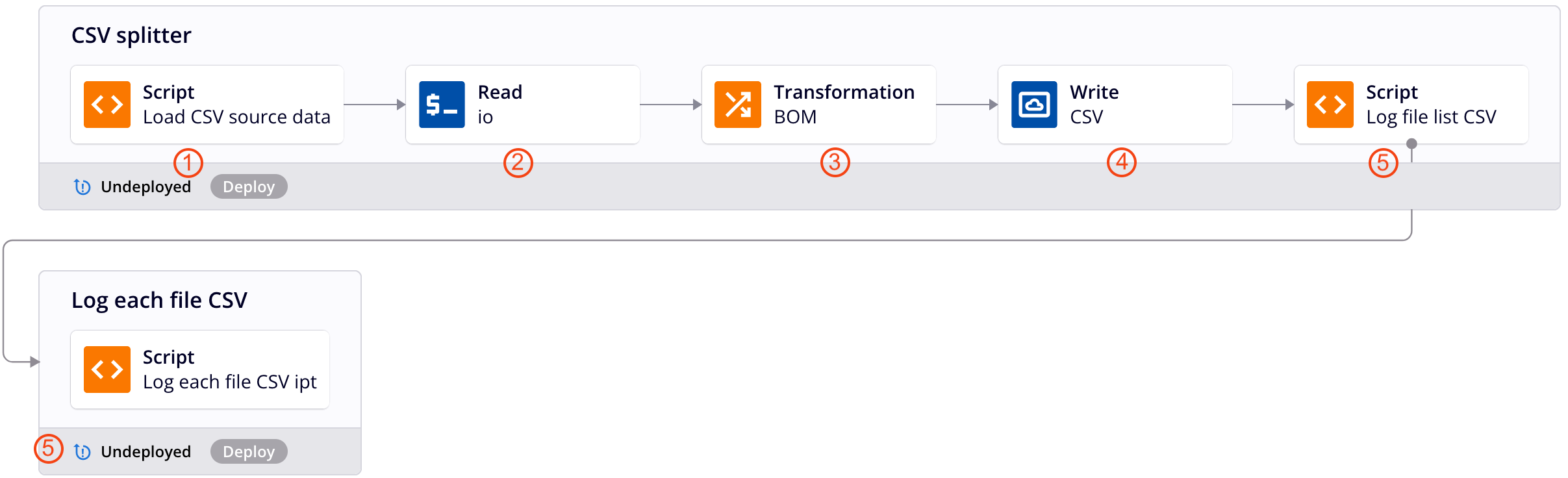
-
El script asigna los datos de origen a una variable global llamada
io(entrada/salida). (Se utiliza un script con fines de demostración; los datos de origen también podrían provenir de un endpoint configurado.)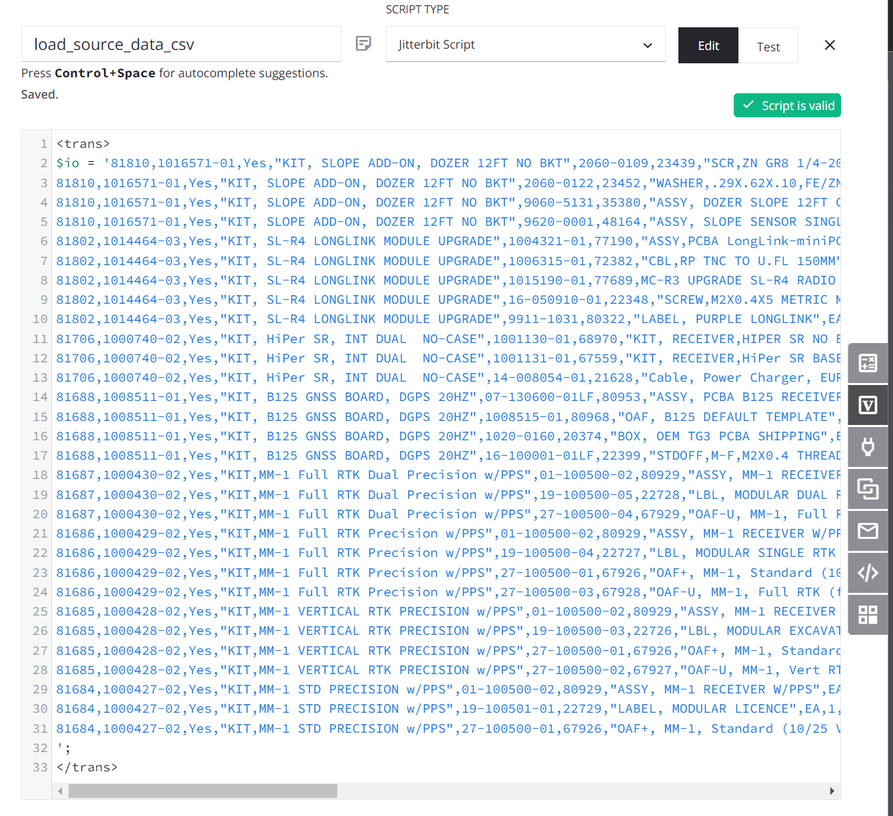
-
La variable global
iose utiliza para configurar un endpoint de Variable, y una actividad de lectura de Variable Lectura asociada es utilizada por la operación como la fuente de la transformación. -
Dentro de la transformación, la fuente y los objetivos utilizan el mismo esquema, y todos los campos están mapeados. El primer campo de datos en el script de mapeo de la transformación está configurado para usar
SCOPE_CHUNK. La funciónSetse utiliza para construir una variable que comienza con la fraseSCOPE_CHUNKy se concatena con el ID único del registro de la fuente, así como un contador de registros y un sufijo de.csv: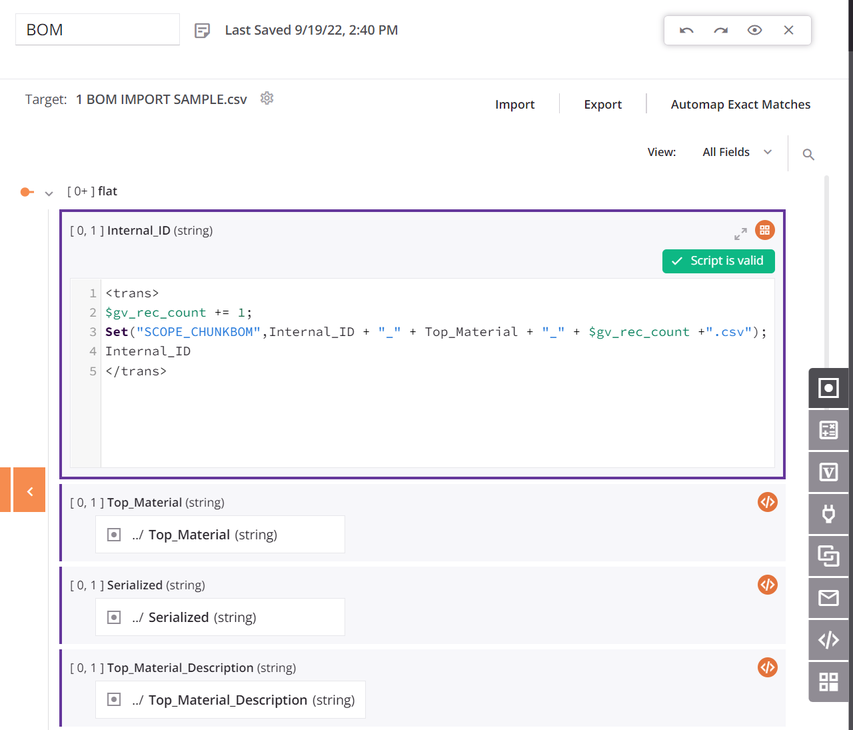
-
El objetivo es una actividad de Escritura en Almacenamiento Temporal configurada con una ruta predeterminada y la variable global de nombre de archivo definida anteriormente.
-
Los scripts son para registrar la salida y son opcionales. El primer script obtiene una lista de los archivos del directorio y recorre la lista, registrando el nombre del archivo y el tamaño, y luego pasa el nombre del archivo a una operación con otro script que registra el contenido del archivo. (Consulte las capturas de pantalla del ejemplo de JSON Jerárquico arriba.)
-
Las opciones de operación deben configurarse con Habilitar Fragmentación seleccionada, con un Tamaño de Fragmento de
1, Número de Registros por Archivo de1, y Número Máximo de Hilos de1.
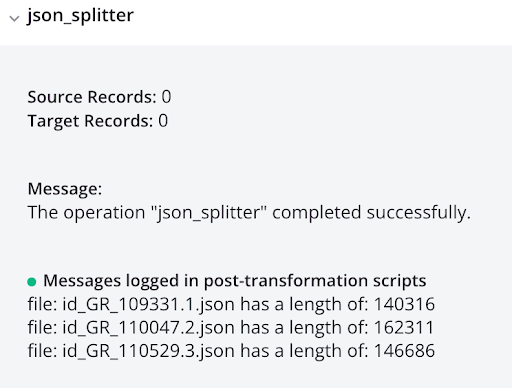
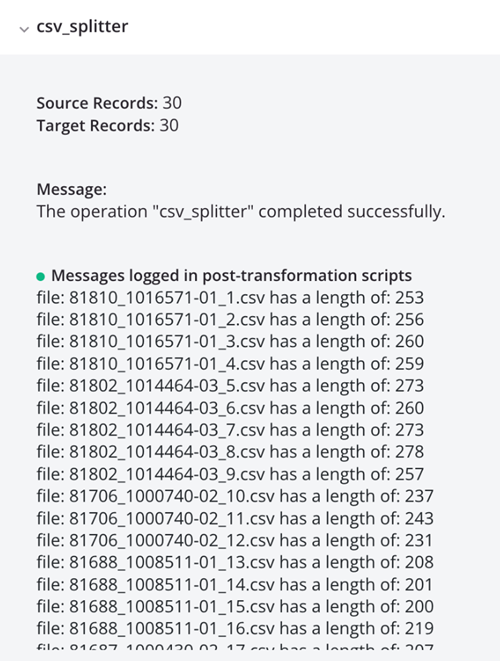
Ejecutar la operación resulta en registros CSV individuales, mostrados en la salida del registro:
JSON Jerárquico
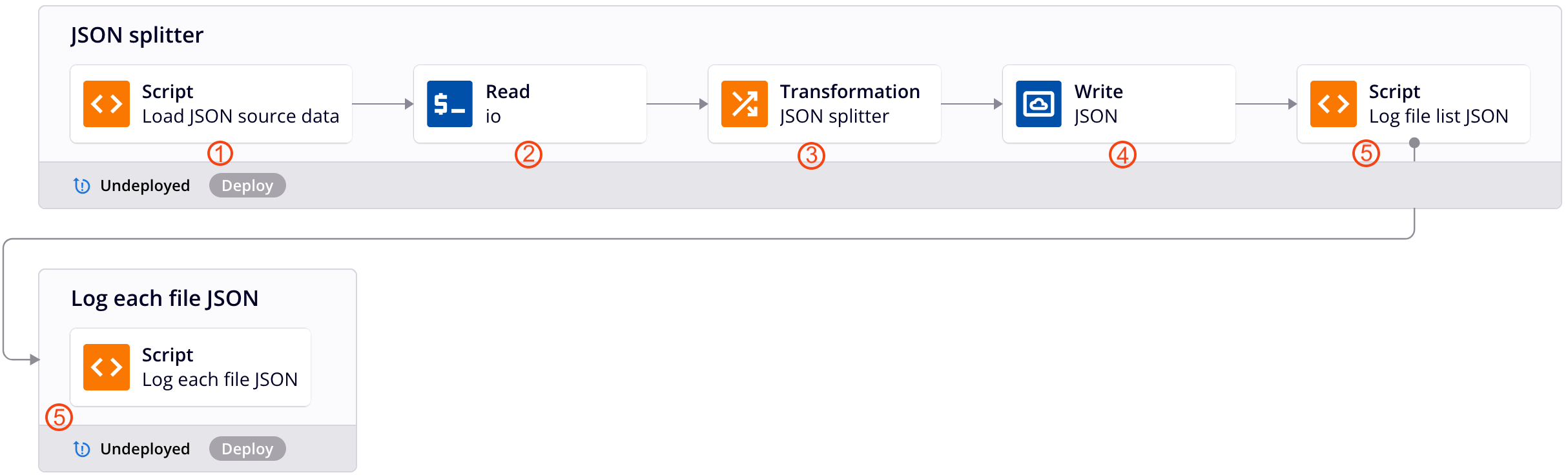
Esta cadena de operación de ejemplo aplica el patrón de diseño descrito anteriormente para dividir datos JSON jerárquicos en un archivo para cada registro. Cada número corresponde con una descripción del paso de operación a continuación.
Nota
Este patrón de diseño ya no es el método recomendado para dividir datos JSON jerárquicos. Para el método recomendado, consulte Dividir un archivo en registros individuales usando SourceInstanceCount.
-
El script asigna los datos de origen a una variable global llamada
io(entrada/salida). (Se utiliza un script con fines de demostración; los datos de origen también podrían provenir de un endpoint configurado.)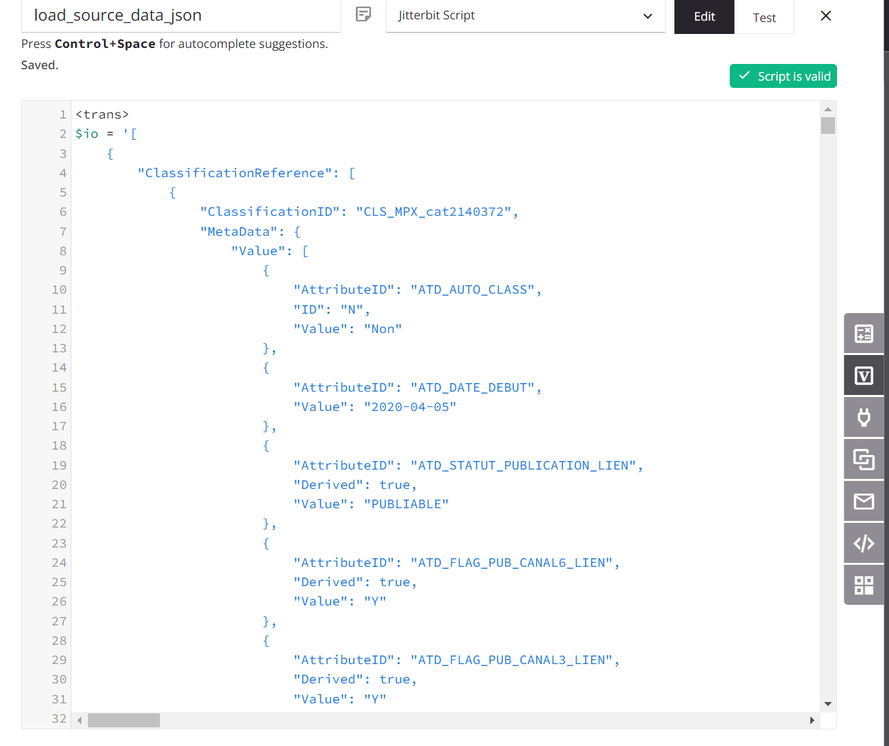
-
La variable global
iose utiliza para configurar un endpoint de Variable, y una actividad de Variable Read asociada es utilizada por la operación como la fuente de la transformación:
-
Dentro de la transformación, la fuente y el destino utilizan el mismo esquema, y todos los campos están mapeados:
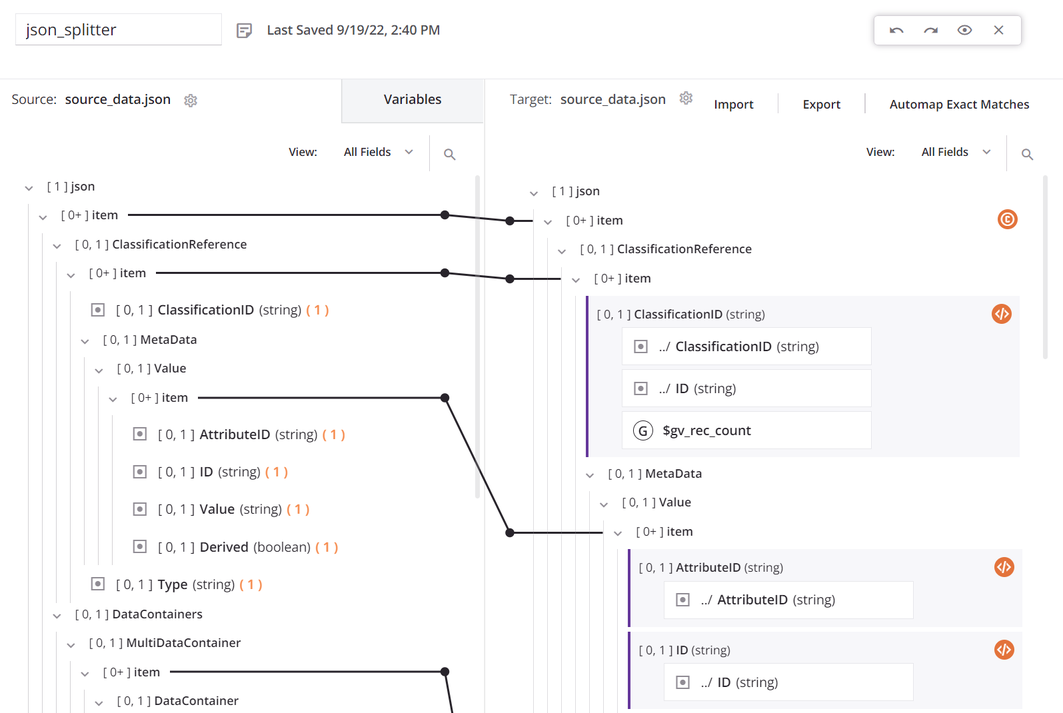
El nodo
itemsuperior tiene una condición para generar el conteo de registros. El primer campo de datos en el mapeo de transformación está configurado para usarSCOPE_CHUNK. La funciónSetse utiliza para construir una variable que comienza con la fraseSCOPE_CHUNKy se concatena con el ID de registro único de la fuente, así como un contador de registros y un sufijo de.json: -
El destino es una actividad de Temporary Storage Write configurada con una ruta predeterminada y la variable global de nombre de archivo definida anteriormente:
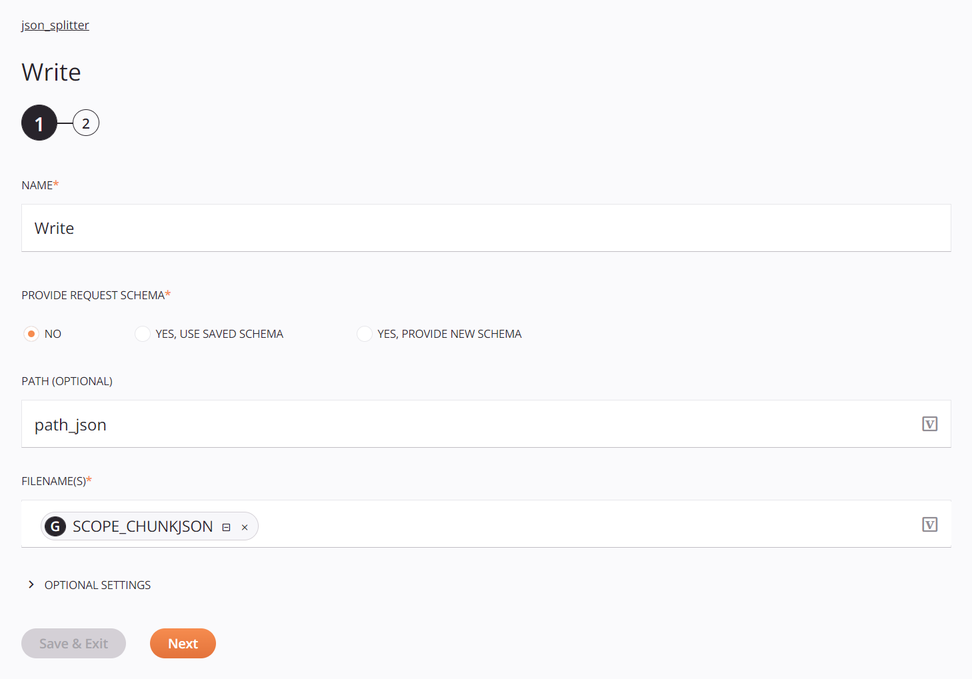
-
Los scripts son para registrar la salida y son opcionales. El primer script obtiene una lista de los archivos del directorio y recorre la lista, registrando el nombre del archivo y el tamaño, y luego pasa el nombre del archivo a una operación con otro script que registra el contenido del archivo:
log_file_list_json<trans> arr = Array(); arr = FileList("<TAG>activity:tempstorage/json_splitter/tempstorage_read/Read</TAG>"); cnt = Length(arr); i = 0; While(i < cnt, filename = arr[i]; file = ReadFile("<TAG>activity:tempstorage/json_splitter/tempstorage_read/Read</TAG>",filename); WriteToOperationLog("file: " + filename + " has a length of: " + Length(file)); $gv_file_filter = filename; RunOperation("<TAG>operation:log_each_file_json</TAG>"); i++ ); </trans>log_each_file_json<trans> WriteToOperationLog(ReadFile("<TAG>activity:tempstorage/json_splitter/tempstorage_read/Read</TAG>",$gv_file_filter)); </trans> -
Las opciones de operación deben configurarse con Enable Chunking seleccionado, con un Chunk Size de
1, Number of Records per File de1, y Max Number of Threads de1: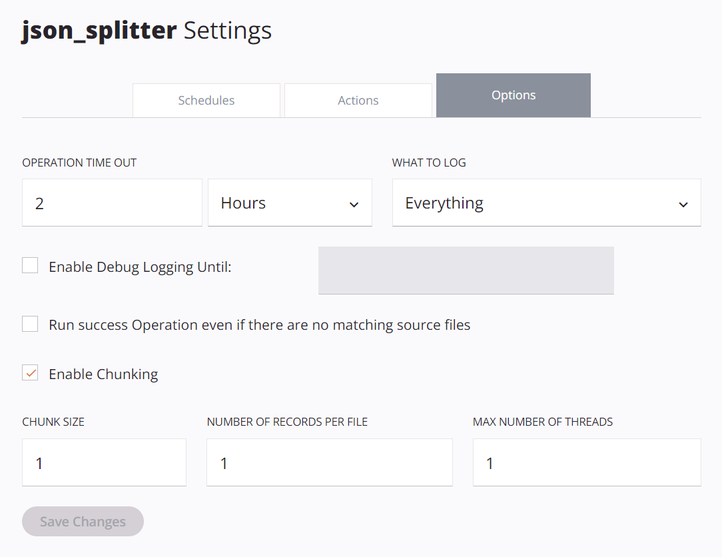
Ejecutar la operación resulta en registros JSON individuales, que se muestran en la salida del registro: