Conceptos clave para transformaciones en Jitterbit Studio
Esta página explica los conceptos fundamentales que se deben entender al diseñar transformaciones y solucionar problemas.
Esquemas
Un esquema define la estructura y los tipos de datos de tus datos de entrada o salida. Los esquemas especifican qué campos están disponibles, sus tipos de datos y cómo están organizados los campos:
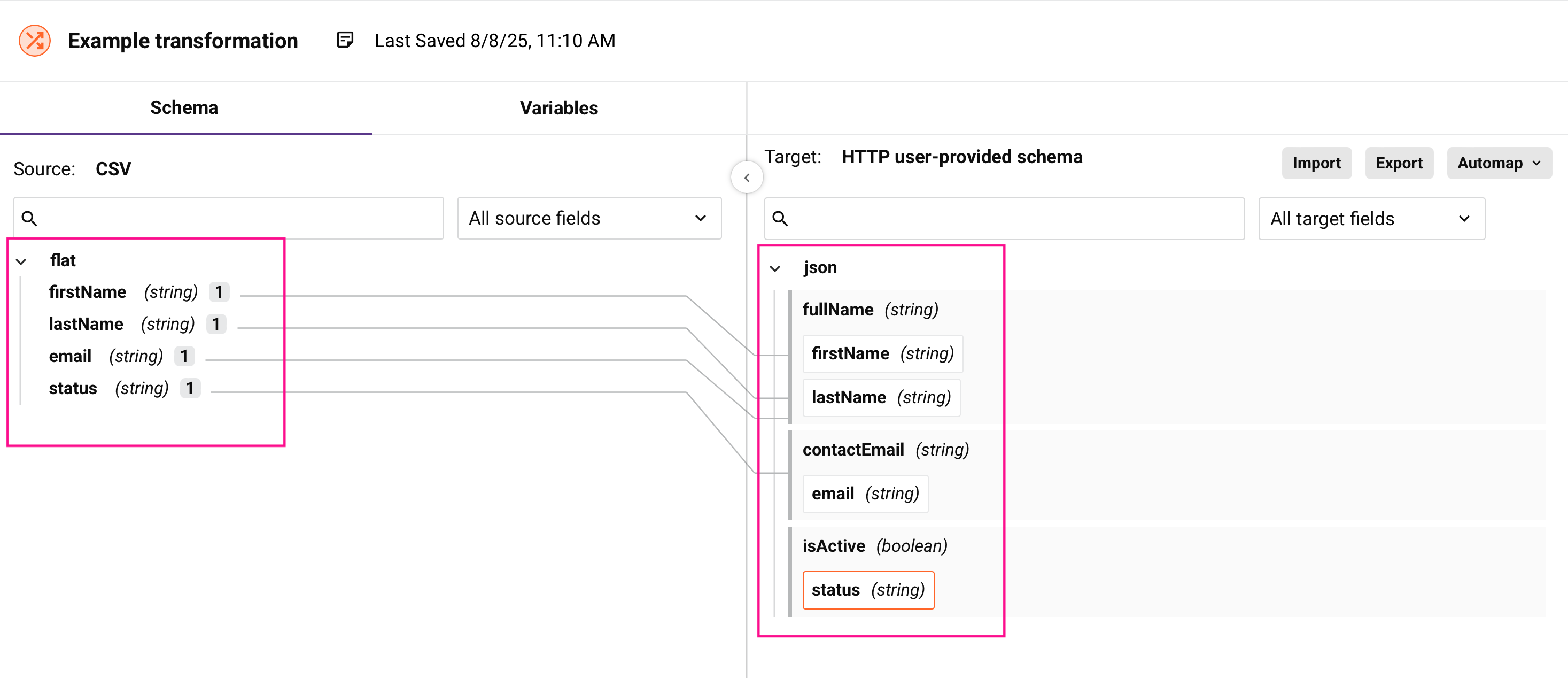
Esquemas de origen
El esquema de origen describe la estructura de los datos que ingresan a tu transformación. Los esquemas de origen pueden provenir de estas fuentes:
-
Esquemas generados por actividades: Creado automáticamente por actividades de conector como consultas a bases de datos o llamadas a API.
-
Esquemas definidos por el usuario: Esquemas personalizados que creas o subes.
Los esquemas de origen son opcionales. No necesitas un esquema de origen si solo estás utilizando variables, valores personalizados o lógica programada en tus mapeos.
Para más información, consulta Elegir fuentes de esquema.
Esquemas de destino
El esquema de destino describe la estructura de los datos que salen de tu transformación. Al igual que los esquemas de origen, los esquemas de destino pueden ser generados por actividades o definidos por el usuario.
Los esquemas de destino son siempre requeridos. Cada transformación debe tener un esquema de destino que defina la estructura de salida.
Para obtener orientación detallada sobre cómo crear y configurar esquemas, consulta Crear una transformación y configurar esquemas.
Estructuras de datos
Las estructuras de datos definen cómo se organiza la información dentro de los esquemas.
Estructuras planas
Las estructuras planas contienen campos en un solo nivel sin anidamiento. Ejemplos de estos formatos incluyen:
- Archivos CSV con columnas
- Tablas de bases de datos individuales
- Archivos XML simples sin elementos anidados
Ejemplo
<customer>
<id>10123</id>
<fullname>ABC Co.</fullname>
<street>1 Main St.</street>
<city>Anytown</city>
<state>NY</state>
<zip>12345</zip>
</customer>
Estructuras jerárquicas
Las estructuras jerárquicas contienen relaciones anidadas entre campos y registros. Ejemplos de estos formatos incluyen:
- Archivos XML complejos con elementos anidados
- Objetos JSON con propiedades anidadas
- Uniones de bases de datos a través de múltiples tablas
Ejemplo
<customer>
<id>10123</id>
<name>ABC Co.</name>
<addresses>
<address>
<street>1 Main St.</street>
<city>Anytown</city>
<state>NY</state>
<zip>12345</zip>
</address>
<address>
<street>1 Time Square</street>
<city>New York City</city>
<state>NY</state>
<zip>54321</zip>
</address>
</addresses>
</customer>
Para obtener más información sobre cómo trabajar con estructuras de datos, consulte Mapear datos.
Para escenarios de datos jerárquicos complejos, consulte Trabajar con datos jerárquicos.
Nodos y campos
Los esquemas se muestran como estructuras de árbol que contienen nodos y campos. Los nodos son contenedores que organizan campos en estructuras jerárquicas. Los campos contienen los valores de datos reales.
Cada nodo y campo muestra estos indicadores visuales:

- Clave de cardinalidad: Muestra las reglas de ocurrencia entre corchetes.
- Nombre: El identificador del elemento del esquema
- Tipo de dato: Solo para campos (cadena, entero, booleano, etc.)
-
Indicadores de atributo/valor: Algunas estructuras XML incluyen símbolos adicionales:
Símbolo Significado @Datos de atributo del elemento, por ejemplo @image#Datos de texto del elemento, por ejemplo #text
Nodos
Los nodos son contenedores que organizan campos en estructuras jerárquicas:
- Caret: Expande y colapsa nodos.
- Nombres en negrita: Indican nodos que contienen mapeos cuando están colapsados.
- Expansión predeterminada: 8 niveles de profundidad para esquemas con menos de 750 nodos, 5 niveles de profundidad para esquemas más grandes.
No se puede mapear datos directamente a nodos. En su lugar, se mapean datos a los campos que contienen los nodos.
Campos
Los campos contienen los valores de datos reales y tienen estas propiedades:
- Nombre: El identificador del campo.
- Tipo de dato: El tipo de dato, como cadena, entero, booleano, fecha y otros.
- Formato: Formato opcional para fechas o moneda.
-
Valores predeterminados: Cuando un esquema XSD o WSDL especifica un valor predeterminado para un elemento o atributo, el valor aparece junto al nombre del campo en la interfaz de transformación:

Notación de cardinalidad
Las claves de cardinalidad indican reglas de ocurrencia utilizando notación estilo UML:
| Clave de cardinalidad | Definición |
|---|---|
[1] |
Exactamente un elemento (requerido) |
[1+] |
Uno o más elementos (requerido, repetible) |
[0,1] |
Cero o un elemento (opcional) |
[0+] |
Cero o más elementos (opcional, repetible) |
Mapeos
Un mapeo conecta datos de origen a campos de destino y define cómo se deben transformar los datos.
Tipos de mapeos
-
Mapeos de campo directo: Conectan campos de origen directamente a campos de destino. Ver Mapear campos manualmente.
-
Mapeos de valor personalizado: Asignan valores o expresiones estáticas. Ver Usar valores personalizados.
-
Mapeos de variable: Hacen referencia a variables de proyecto o globales. Ver Mapear variables.
-
Mapeos de script: Utilizan funciones y lógica para transformar datos. Ver Mapeo con scripts.
-
Lógica condicional: Aplica lógica diferente según las condiciones. Ver Lógica condicional.
Scripts de mapeo
Todos los mapeos se implementan como scripts en los campos de destino. Incluso los mapeos visuales como arrastrar y soltar crean scripts subyacentes. Se pueden editar estos scripts directamente para transformaciones complejas.
Para el mapeo automático de estructuras similares, ver Mapear estructuras idénticas.
Nodos de bucle
Los nodos de bucle manejan datos repetidos, como múltiples registros o arreglos. Cuando se mapean campos dentro de nodos de bucle, la transformación procesa cada iteración de los datos.
Generación automática de bucles
Los nodos de bucle se generan automáticamente cuando mapeas campos de datos de origen repetidos a estructuras de destino repetidas. Aparece una línea de iterador que muestra cómo la transformación recorrerá los datos.
Definición manual de bucles
Puedes definir manualmente los nodos de bucle cuando la generación automática no coincide con tus necesidades de procesamiento de datos. Esto es útil cuando tienes múltiples niveles de datos repetidos y necesitas controlar qué nivel impulsa la iteración.
Para obtener una guía completa sobre cómo trabajar con datos repetidos, consulta Controlar bucles de datos.
Variables
Las variables están diseñadas para pasar valores, configuraciones y pequeñas cantidades de datos entre diferentes componentes en tu integración. Las variables son útiles cuando necesitas compartir información como IDs de sesión, parámetros de configuración o valores calculados entre scripts, transformaciones y operaciones. Estos tipos de variables están disponibles para su uso:
| Tipo | Alcance | Mejor para |
|---|---|---|
| Local | Script único | Cálculos y valores temporales |
| Global | Cadena de operación | Pasar datos entre operaciones |
| Project | Proyecto entero | Configuración y credenciales |
| Jitterbit | Definido por el sistema | Información en tiempo de ejecución |
Para ejemplos e información detallada sobre cada tipo de variable, consulta sus páginas de documentación individuales.
Para ejemplos prácticos de uso de variables en transformaciones, consulta Mapear variables.
Flujo de datos
Los datos fluyen a través de las transformaciones en esta secuencia:
-
Entrada: Una actividad de origen proporciona datos que coinciden con el esquema de origen.
-
Procesamiento: Una transformación aplica mapeos, funciones y lógica empresarial.
-
Salida: Los datos transformados que coinciden con el esquema de destino van a la actividad de destino.
Entender este flujo ayuda a diseñar mapeos que manejan los datos correctamente y a solucionar problemas cuando los datos no se transforman como se esperaba.
Para orientación sobre validación y solución de problemas, consulte Probar y validar transformaciones y Resolver conflictos y errores de mapeo de transformaciones.