Trabajar con datos jerárquicos en Jitterbit Studio
Introducción
Las estructuras de datos jerárquicas contienen una o más relaciones de padre-hijo o anidadas entre campos y registros. Ejemplos comunes incluyen clientes con múltiples direcciones, pedidos con artículos de línea o empresas con múltiples ubicaciones.
En Studio, las estructuras jerárquicas también se llaman datos relacionales, multilevel, complejos o estructuras de árbol.
Para obtener información sobre la notación de nodos y campos, consulte Nodos y campos en Conceptos clave.
Identificar estructuras jerárquicas
Los datos jerárquicos aparecen como una estructura de árbol en las transformaciones:
<customer>
<id>10123</id>
<name>ABC Co.</name>
<addresses>
<address>
<street>1 Main St.</street>
<city>Anytown</city>
<state>NY</state>
<zip>12345</zip>
</address>
<address>
<street>1 Time Square</street>
<city>New York City</city>
<state>NY</state>
<zip>54321</zip>
</address>
</addresses>
</customer>
Mapear datos jerárquicos
Cuando mapea estructuras jerárquicas, debe mapear dentro del mismo nivel. Por ejemplo:
- Los campos padre se mapean a campos padre.
- Los campos hijo se mapean a los campos hijo correspondientes.
- Los nodos de bucle se generan automáticamente para elementos repetidos.
Si el mapeo automático no funciona para su estructura, consulte Controlar bucles de datos.
Manejar desajustes de estructura
Cuando las estructuras de origen y destino difieren, puede manejarlas utilizando uno de estos métodos:
-
Mapear múltiples instancias a una sola instancia: Cuando mapea arreglos a objetos únicos, verá este diálogo:
Cita
Una fuente de múltiples instancias no puede ser mapeada a un destino de instancia única. ¿Desea cambiar el mapeo para usar la primera instancia de cada fuente?
Hacer clic en Sí mapea solo el primer registro agregando
#1a la ruta. -
Aplanar jerárquico a estructuras planas: Para crear un registro de salida por cada elemento hijo, siga estos pasos:
- Mapee campos desde el nodo repetido más profundo.
- Los datos padre se repiten automáticamente para cada hijo.
- La línea del iterador se mueve al nivel hijo.
Normalización de datos
La normalización de datos es el proceso de reestructurar registros de origen planos en un árbol jerárquico. Esto es necesario al mapear datos planos (como filas de CSV o de base de datos) a un destino jerárquico (como XML o JSON) para asegurar que las relaciones padre-hijo se creen correctamente sin duplicar nodos padre.
Por defecto, Harmony utiliza un algoritmo de normalización para construir el árbol de destino. Este proceso convierte la estructura plana de la fuente en una estructura jerárquica de origen, permitiendo que se mapee al destino jerárquico.
La normalización se puede desactivar utilizando una variable de Jitterbit dependiendo de la estructura de destino a la que se esté mapeando:
- Plano a plano:
jitterbit.transformation.disable_normalization - Plano a XML:
jitterbit.transformation.flat_to_xml.disable_normalization
El comportamiento del mapeo de transformación cambia según si la normalización está habilitada:
-
Con normalización (por defecto): Los datos redundantes en filas planas se colapsan. Por ejemplo, si tienes cinco filas de ítems de línea de
Ordenpara unID de Orden, se crea un padreOrdencon cinco ítems hijos. -
Sin normalización: Cada registro plano se trata como una rama única. En el ejemplo anterior, esto resultaría en cinco órdenes separadas, cada una conteniendo un solo ítem de línea.
Nodos de instancia única
Si un nodo de destino se define como un nodo de instancia única, solo se conserva el primer registro encontrado para ese nodo. Cualquier registro plano subsiguiente que de otro modo se mapearía a ese nodo se ignora.
Manejar esquemas XML complejos
Cuando se utiliza un esquema que contiene tipos derivados o grupos de sustitución, es necesario proporcionar alguna entrada antes de poder continuar con el mapeo de transformación.
Importante
Esquemas reflejados que utilizan grupos de sustitución no son compatibles y resultarán en un error de tiempo de ejecución de operación.
Especificar el esquema
Los tipos derivados o grupos de sustitución son comunes en esquemas XSD y WSDL basados en XML. Puedes cargar estos tipos de esquemas en una actividad o en una transformación, o pueden ser recuperados directamente desde el endpoint por algunos conectores. Por ejemplo, los esquemas de respuesta devueltos por una búsqueda guardada en una actividad de búsqueda de NetSuite a menudo contienen tipos derivados.
Para más información, consulta Elegir fuentes de esquema.
Seleccionar tipos derivados o grupo de sustitución
Después de especificar el esquema, selecciona los tipos derivados o el grupo de sustitución dentro de la transformación. Puede haber nodos para los cuales puedes seleccionar tipos derivados en el lado de origen o de destino de la transformación.
Un enlace a Seleccionar tipo(s) derivado(s) o Grupo de sustitución se muestra junto al nombre del nodo según corresponda:
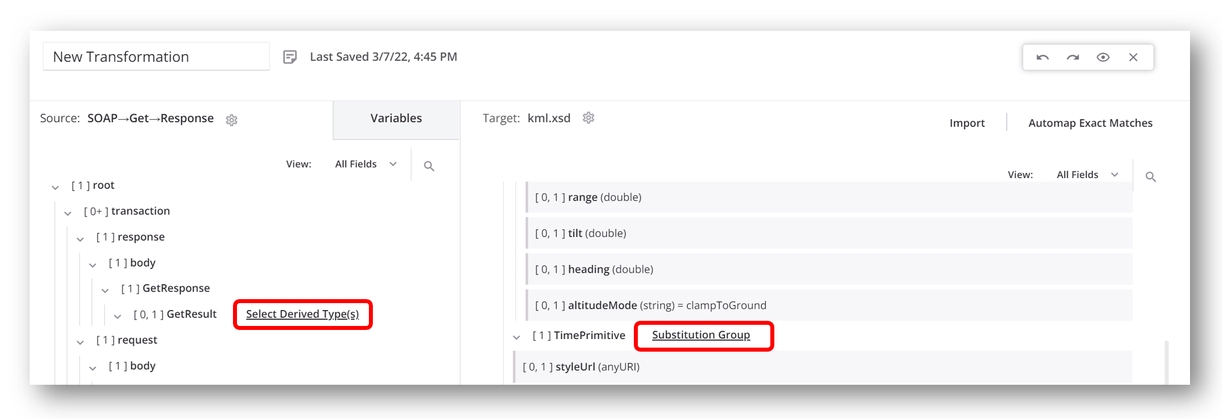
La interfaz de usuario es la misma tanto para seleccionar tipos derivados como para seleccionar un grupo de sustitución.
Haz clic en el enlace Seleccionar tipo(s) derivado(s) o Grupo de sustitución para abrir un diálogo donde puedes seleccionar entre los nodos disponibles:
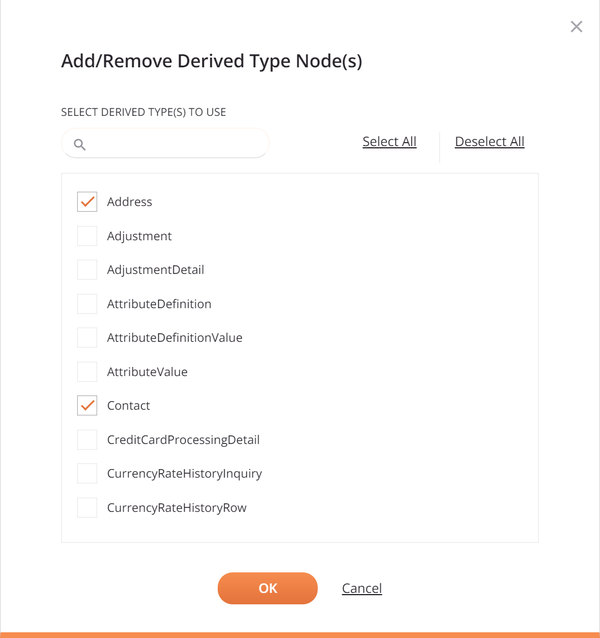
Para filtrar la lista de nodos, ingresa cualquier parte del nombre del nodo en el cuadro de búsqueda. La búsqueda no distingue entre mayúsculas y minúsculas.
Selecciona los nodos que deseas utilizando las casillas de verificación junto a los nombres de los nodos. Los enlaces Seleccionar todo y Deseleccionar todo se pueden usar para seleccionar o desmarcar todos los nodos a la vez. Luego haz clic en Aceptar para usar los nodos de tipo derivado dentro del esquema.
Nota
Cuando seleccionas un gran número de nodos de tipo derivado a la vez (30 o más), el sistema puede responder lentamente al actualizar la transformación.
Los nodos seleccionados se muestran dentro del esquema. Puedes expandir o colapsar estos nodos para mostrar nodos e campos hijos adicionales dentro de ellos:

Después de seleccionar nodos, puedes cambiar tus selecciones haciendo clic en el enlace Seleccionar tipo(s) derivado(s) o Grupo de sustitución nuevamente para regresar a la pantalla de selección y agregar o eliminar nodos según sea apropiado.
Luego puedes proceder con el mapeo de transformación como de costumbre, mapeando los campos de origen dentro de esos nodos seleccionados a campos de destino, o mapeando a campos de destino dentro de nodos seleccionados.