Opciones de operación en Jitterbit Studio
Introducción
Configura las opciones de operación para controlar los tiempos de espera, el registro y el procesamiento de datos. La mayoría de las operaciones funcionan bien con la configuración predeterminada, pero puedes personalizarlas para necesidades específicas.
Acceder a las opciones de operación
Puedes acceder a la opción de Configuración para operaciones desde estas ubicaciones:
- La pestaña Flujos de trabajo del panel del proyecto (ver Menú de acciones de componentes en Pestaña Flujos de trabajo del panel del proyecto).
- La pestaña Componentes del panel del proyecto (ver Menú de acciones de componentes en Pestaña Componentes del panel del proyecto).
- El lienzo de diseño (ver Menú de acciones de componentes en Lienzo de diseño).
- El lienzo de diseño haciendo doble clic en la operación (esto abre Configuración directamente).
Después de que se abra la pantalla de configuración de la operación, selecciona la pestaña Opciones:

Configurar opciones de operación
Las siguientes secciones describen cada opción de operación:
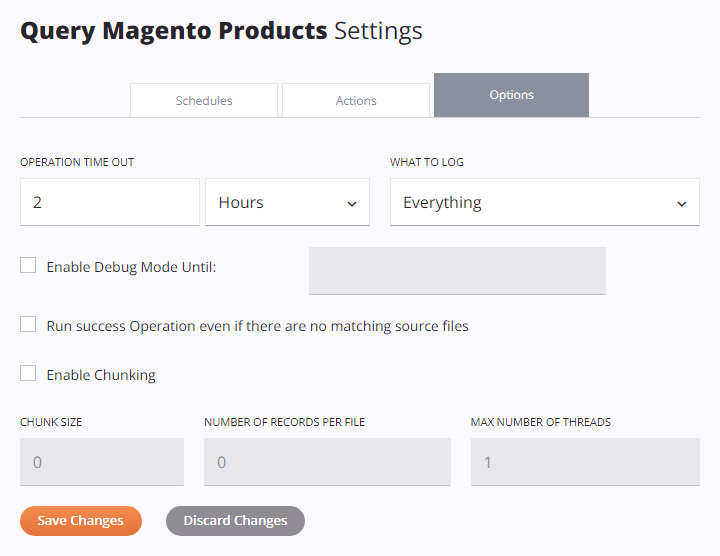
- Tiempo de espera de la operación
- Qué registrar
- Ejecutar en agente dedicado
- Habilitar modo de registro de depuración hasta
- Ejecutar operación de éxito incluso si no hay archivos fuente coincidentes
- Habilitar fragmentación
- Opciones de operación masiva de Salesforce
Tiempo de espera de la operación
Establezca cuánto tiempo se ejecuta la operación antes de que se cancele. El valor predeterminado es de 2 horas, lo que funciona para la mayoría de las operaciones.
Es posible que desee ajustar esta configuración por las siguientes razones:
-
Aumentar el tiempo de espera para conjuntos de datos grandes que tardan más en procesarse. Las operaciones programadas que procesan grandes volúmenes de datos pueden necesitar tiempos de espera más largos. Si sus conjuntos de datos superan los límites de tiempo de espera, consulte Habilitar fragmentación para opciones que dividen grandes conjuntos de datos en lotes más pequeños y controlan el número de registros escritos por archivo de salida.
-
Disminuir el tiempo de espera para operaciones sensibles al tiempo que deben completarse rápidamente.
Ingrese un número y seleccione Segundos, Minutos o Horas en el menú desplegable.
Nota
Las operaciones activadas por API Manager APIs ignoran esta configuración en agentes en la nube. Para agentes privados, habilite EnableAPITimeout en el archivo de configuración del agente privado para que la configuración de Tiempo de espera de operación se aplique a las operaciones activadas por APIs.
Qué registrar
Elija qué información aparece en los registros de operaciones:
- Todo: Registra toda la actividad de la operación (recomendado).
- Solo Errores: Registra solo operaciones con un estado de tipo error (como Error, Fallo de SOAP o Éxito con Error de Hijo). Utilice esta configuración si tiene problemas de rendimiento y no necesita registros detallados. Las operaciones de hijo exitosas no se registran. Las operaciones de padre (de nivel raíz) siempre se registran, ya que requieren registro para funcionar correctamente.
Depuración
La sección Depuración incluye opciones para ejecutar una operación en un agente dedicado y habilitar el modo de depuración.
Ejecutar en agente dedicado
Dirija esta operación para que se ejecute en un agente específico como una medida temporal de solución de problemas. Esta opción se aplica solo a grupos de agentes privados configurados con una clase de grupo de agentes de Alta Disponibilidad (HA). Úselo para reproducir fallos en un agente específico o para eludir un agente problemático mientras mantiene el resto del grupo operativo.
Para habilitar esta opción, selecciona la casilla Ejecutar en agente dedicado, luego configura lo siguiente:
-
Seleccionar un agente: Selecciona el agente específico dentro del grupo HA que se utilizará para la ejecución de esta operación. Si el agente que seleccionas se elimina mientras esta opción está activa, la ejecución en agente dedicado se desactiva automáticamente y la operación vuelve a la ejecución estándar del grupo de agentes.
-
Hasta: Selecciona una fecha hasta dos semanas a partir de hoy. La ejecución en agente dedicado se desactiva automáticamente en esta fecha, y la operación vuelve al comportamiento estándar de ejecución del grupo de agentes.
-
Aplicar a operaciones secundarias: Si la operación tiene operaciones secundarias, esta casilla aparece. Selecciónala para dirigir todas las operaciones secundarias a ejecutarse en el mismo agente que la operación principal.
Cuando Ejecutar en agente dedicado está habilitado, aparece una advertencia.
Diálogo
Ejecutar esta operación en un solo agente omite tu configuración de Alta Disponibilidad (HA). Si este agente falla o alcanza su capacidad, la operación se detendrá sin un cambio a otro agente.
Habilitar Modo de Depuración Hasta
Activa el registro detallado para la solución de problemas. Selecciona una fecha hasta dos semanas a partir de hoy. El modo de depuración se desactiva automáticamente en esta fecha.
Advertencia
En grupos de agentes en la nube, la duración de esta configuración es poco confiable. Los registros pueden dejar de generarse antes del final del período de tiempo seleccionado.
Cuando habilitas el modo de depuración para operaciones con operaciones secundarias, puedes aplicar la misma configuración a todas las operaciones secundarias utilizando la casilla También Aplicar a Operaciones Secundarias.
El registro de depuración genera diferentes tipos de registros según el tipo de agente:
| Tipo de registro | Descripción del registro | Tipo de agente |
|---|---|---|
| Archivos de registro de depuración | Archivos de registro de depuración para una solución de problemas detallada. Puede acceder a estos archivos directamente en el agente o descargarlos a través de la Consola de Administración. La depuración también se puede habilitar para todo el proyecto desde el propio agente privado (consulte Registro de depuración de operaciones). Los archivos de registro de depuración son accesibles directamente en agentes privados y se pueden descargar a través de las páginas de la Consola de Administración Agentes y Tiempo de ejecución. Advertencia El modo de depuración crea archivos de registro grandes. Úselo solo durante las pruebas, no en producción. |
Solo agentes privados |
| Entrada y salida de componentes | Datos de solicitud y respuesta (conservados durante 30 días). Accedido a través de la página de la Consola de Administración Tiempo de ejecución. Precaución Los datos de entrada y salida del componente siempre se registran en la nube de Harmony, incluso si el registro en la nube está deshabilitado. Para detener esto en agentes privados, establece Los registros de depuración contienen todos los datos de solicitud y respuesta, incluida información sensible como contraseñas e información personal identificable (PII). Estos datos aparecen en texto claro en los registros de la nube de Harmony durante 30 días. |
Agentes en la nube y privados |
| Registros de operaciones de API | Registros de operaciones de API exitosas (configurados para APIs personalizadas o APIs OData). Por defecto, solo se registran las operaciones de API con errores en los registros de operaciones. |
Agentes en la nube y privados |
Ejecutar operación de éxito incluso si no hay archivos fuente coincidentes
Esta opción obliga a que una operación tenga éxito incluso cuando su desencadenador falla. Esto permite que otras operaciones desencadenadas para ejecutarse Al Éxito de esta operación se ejecuten independientemente del resultado de la operación inicial. Se aplica solo cuando la operación inicial contiene una actividad fuente para uno de estos conectores:
- API
- Compartición de Archivos
- FTP
- HTTP
- Almacenamiento Local
- SOAP
- Almacenamiento Temporal
- Actividad de Variable
Por defecto, cualquier operación Al Éxito se ejecuta solo si tiene un archivo fuente coincidente para procesar. Esta opción puede ser útil para configurar partes posteriores de un proyecto sin requerir el éxito de una operación dependiente.
Nota
La configuración AlwaysRunSuccessOperation en el archivo de configuración del agente privado anula esta opción.
Habilitar Chunking
El chunking divide grandes conjuntos de datos en fragmentos más pequeños (lotes). Esto hace que el procesamiento sea más rápido y ayuda a cumplir con los límites de registros de la API. Para una guía orientada a tareas que cubre la selección del tamaño de fragmento, el procesamiento paralelo y el alcance de variables, consulte Configurar el chunking de operaciones para grandes conjuntos de datos.
Para habilitar el chunking, su operación debe contener una transformación o una actividad de uno de estos conectores:
Nota
Chunking no es compatible cuando la fuente es un conector basado en Connector SDK (mostrado como SDK en la columna Tipo de conector de la lista de conectores). Si tu fuente es basada en SDK, divide la operación en dos: utiliza una actividad de Escritura de Variable como el objetivo de la primera operación, luego utiliza una actividad de Lectura de Variable como la fuente en la segunda operación con chunking habilitado.
Usa chunking en estas situaciones:
- Procesas grandes conjuntos de datos con miles de registros.
- Utilizas servicios web con límites de registros. Por ejemplo, Salesforce permite solo 200 registros por llamada.
- Quieres usar múltiples núcleos de CPU para procesamiento paralelo.
Consejo
Para orientación sobre cuándo usar procesamiento por lotes frente a procesamiento basado en eventos en proyectos de integración, consulta Procesamiento por lotes y basado en eventos.
Cuando hay una actividad de Salesforce, Salesforce Service Cloud, o ServiceMax en la operación, el chunking se habilita automáticamente.
Cuando esta configuración está habilitada, configura estos campos:
-
Tamaño del Chunk: El número de registros en cada chunk. El valor predeterminado es
1para la mayoría de las operaciones y200para las operaciones de Salesforce.Nota
Cuando uses una actividad de bulk de (Salesforce, Salesforce Service Cloud, o ServiceMax), cambia este valor predeterminado a un número mucho mayor, como
10,000. -
Número de Registros por Archivo: El número de registros a escribir en cada archivo de destino (lote). El valor predeterminado es
0, lo que significa sin límite. -
Número máximo de hilos: El número de hilos de procesamiento que se ejecutan al mismo tiempo. El valor predeterminado es
1para la mayoría de las operaciones y2para las operaciones de Salesforce.
Advertencia
El fragmentado afecta cómo funcionan las variables globales y de proyecto. Solo se preservan los cambios del primer hilo. Consulte información detallada sobre el fragmentado a continuación.
Opciones de operación masiva de Salesforce
Las siguientes opciones aparecen solo para las operaciones masivas de Salesforce, Salesforce Service Cloud y ServiceMax (excepto las operaciones de Consulta Masiva):
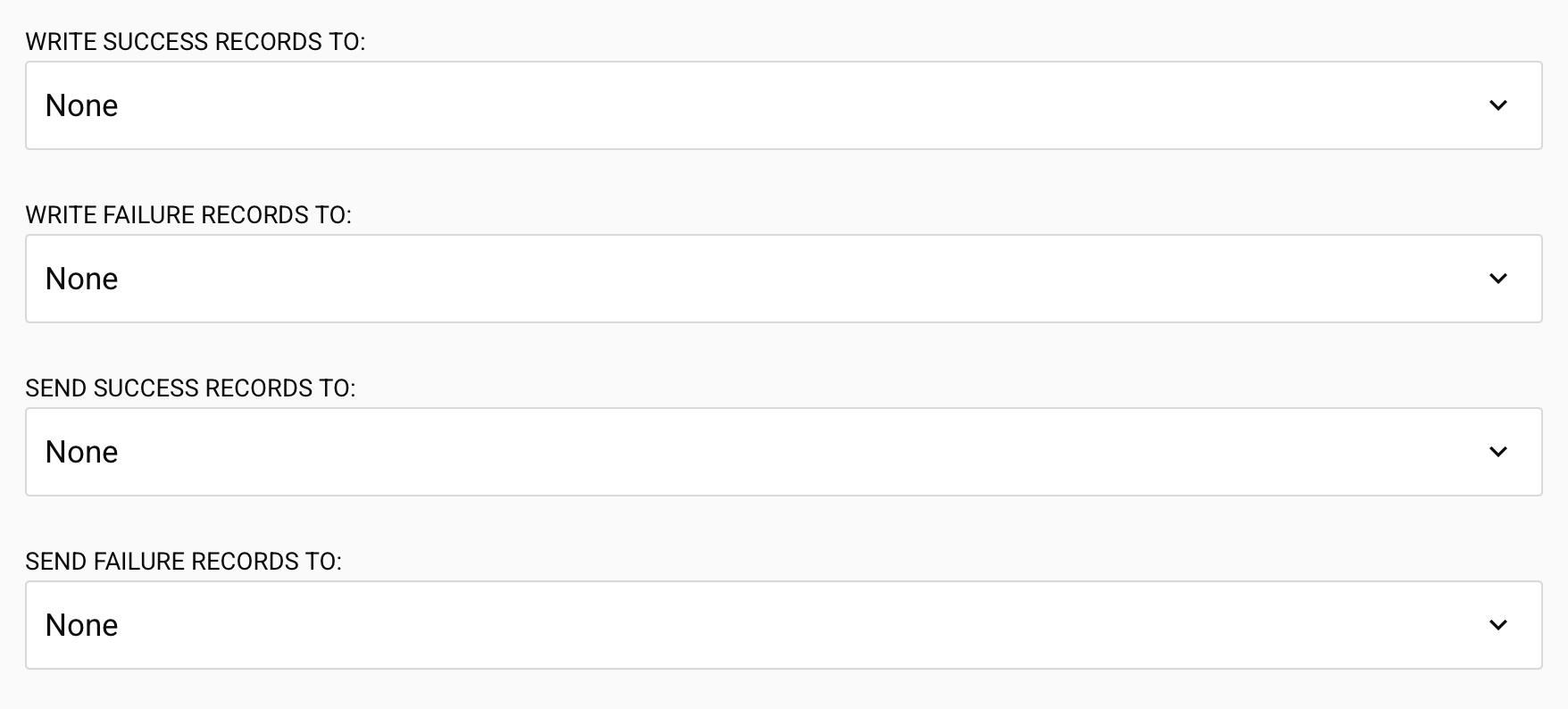
-
Escribir registros de éxito en: Elija dónde enviar los registros exitosos después de que se complete la operación masiva. Seleccione entre las actividades basadas en archivos configuradas: HTTP, API, FTP, Compartir Archivo, Almacenamiento Local, Almacenamiento Temporal, o Variable. Predeterminado: Ninguno.
-
Escribir registros de fallo en: Elija dónde enviar los registros fallidos después de que se complete la operación masiva. HTTP, API, FTP, Compartir Archivo, Almacenamiento Local, Almacenamiento Temporal, o Variable. Predeterminado: Ninguno.
Importante
Cuando se utilizan actividades de Variable, solo las operaciones en la misma cadena de operaciones pueden acceder al valor de la variable durante el tiempo de ejecución.
-
Enviar registros de éxito a: Elija una notificación por correo electrónico para recibir registros exitosos. Seleccione entre las notificaciones por correo electrónico configuradas. Predeterminado: Ninguno.
-
Enviar registros de fallo a: Elija una notificación por correo electrónico para recibir registros fallidos. Seleccione entre las notificaciones por correo electrónico configuradas. Predeterminado: Ninguno.
Nota
Las actividades basadas en archivos y las notificaciones por correo electrónico seleccionadas en estas opciones no necesitan ser parte de una operación desplegada existente. Studio desplegará y gestionará automáticamente estos componentes cuando se seleccionen.
Información detallada sobre el fragmentado
El fragmentado se utiliza para dividir los datos de origen en múltiples fragmentos (lotes) según el tamaño de fragmento configurado. El tamaño del fragmento es el número de registros de origen (nodos) para cada fragmento. La transformación se realiza luego en cada fragmento por separado, produciendo cada fragmento de origen un fragmento de destino. Los fragmentos de destino resultantes se combinan para producir el destino final.
El fragmentado solo se puede utilizar si los registros son independientes y provienen de una fuente que no es LDAP. Se recomienda utilizar un tamaño de fragmento lo más grande posible, asegurándose de que los datos de un fragmento quepan en la memoria disponible. Para métodos adicionales para limitar la cantidad de memoria que utiliza una transformación, consulte Procesamiento de transformaciones.
Advertencia
El uso del fragmentado afecta el comportamiento de las variables globales y del proyecto. Consulte Uso de variables con fragmentado a continuación.
Limitaciones de la API
Muchas API de servicios web (SOAP/REST) tienen limitaciones de tamaño. Por ejemplo, un upsert basado en Salesforce acepta solo 200 registros por cada llamada. Con suficiente memoria, podría configurar una operación para utilizar un tamaño de fragmento de 200. La fuente se dividiría en fragmentos de 200 registros cada uno, y cada transformación llamaría al servicio web una vez con un fragmento de 200 registros. Esto se repetiría hasta que todos los registros hayan sido procesados. Los archivos de destino resultantes se combinarían luego. (Tenga en cuenta que también podría utilizar actividades masivas basadas en Salesforce para evitar el uso del fragmentado.)
Procesamiento paralelo
Si tienes una fuente grande y una computadora con múltiples CPU, se puede utilizar el fragmentado para dividir la fuente para el procesamiento paralelo. Dado que cada fragmento se procesa de manera aislada, varios fragmentos pueden ser procesados en paralelo. Esto se aplica solo si los registros de la fuente son independientes entre sí a nivel de nodo de fragmento. Se pueden llamar servicios web en paralelo utilizando el fragmentado, mejorando el rendimiento.
Al utilizar el fragmentado en una operación donde el objetivo es una base de datos, ten en cuenta que los datos de destino se escriben primero en numerosos archivos temporales (uno para cada fragmento). Estos archivos se combinan luego en un solo archivo de destino, que se envía a la base de datos para inserción/actualización. Si configuras la variable de Jitterbit jitterbit.target.db.commit_chunks a 1 o true cuando el fragmentado está habilitado, cada fragmento se compromete a la base de datos a medida que se vuelve disponible. Esto puede mejorar significativamente el rendimiento, ya que las inserciones/actualizaciones en la base de datos se realizan en paralelo.
Usa variables con fragmentado
Dado que el fragmentado puede invocar multi-hilo, su uso puede afectar el comportamiento de las variables que no se comparten entre los hilos.
Las variables globales y las variables de proyecto están segregadas entre las instancias de fragmentado, y aunque los datos se combinan, los cambios en estas variables no lo están. Solo se preservan los cambios realizados en el hilo inicial al final de la transformación.
Por ejemplo, si una operación —con fragmentado y múltiples hilos— tiene una transformación que cambia una variable global, el valor de la variable global después de que la operación finaliza es el del primer hilo. Cualquier cambio en la variable en otros hilos es independiente y se descarta cuando la operación se completa.
Estas variables globales se pasan a los otros hilos por valor en lugar de por referencia, asegurando que cualquier cambio en las variables no se refleje en otros hilos u operaciones. Esto es similar a la función RunOperation cuando está en modo asíncrono.