Conservar datos para su posterior procesamiento mediante el almacenamiento temporal en Jitterbit Design Studio
Caso de uso
Un patrón común en la integración de datos es el uso de archivos para almacenar temporalmente datos que se utilizan como parte del proceso de transformación o traslado de datos desde el origen al destino.
Ejemplos
Archivos temporales
Un patrón típico es consultar una fuente, guardar la salida en un archivo temporal y luego leer la salida en el siguiente paso.
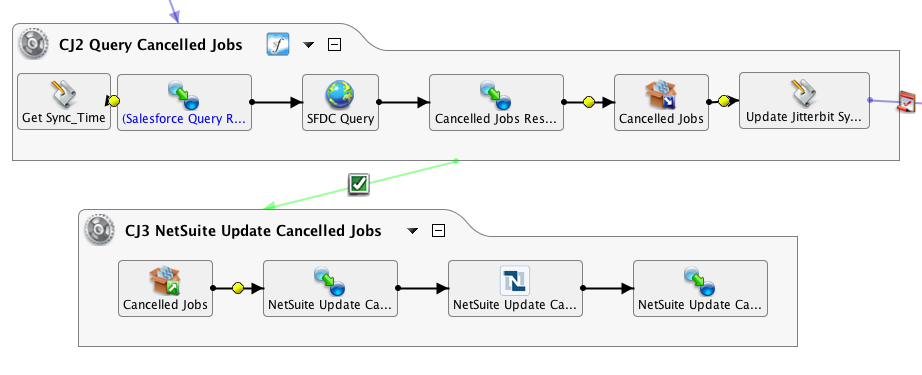
En el ejemplo anterior, se ejecuta una consultar de Salesforce periódicamente y se genera un resultado que se escribe en un destino denominado Trabajos cancelados. En la segunda operación, se lee una fuente con el mismo nombre como entrada en una actualización de NetSuite.
Consideraciones sobre el uso del almacenamiento temporal
- El almacenamiento temporal se escribe en el directorio temporal del sistema operativo predeterminado en el agente que está realizando el trabajo. En el caso de un solo agente privado, se trata del directorio temporal predeterminado del host del servidor de ese agente privado. Si el grupo de agentes está ejecutando más de un agente privado, se trata del directorio temporal en el alojar del servidor de cualquier agente en particular que esté realizando el trabajo. Si está escribiendo en el almacenamiento temporal en agentes de la nube (que están agrupados), se escribe en el alojar del servidor de cualquier agente de la nube en particular.
- De forma predeterminada, el almacenamiento temporal se elimina después de 24 horas mediante un servicio de limpieza Jitterbit
-
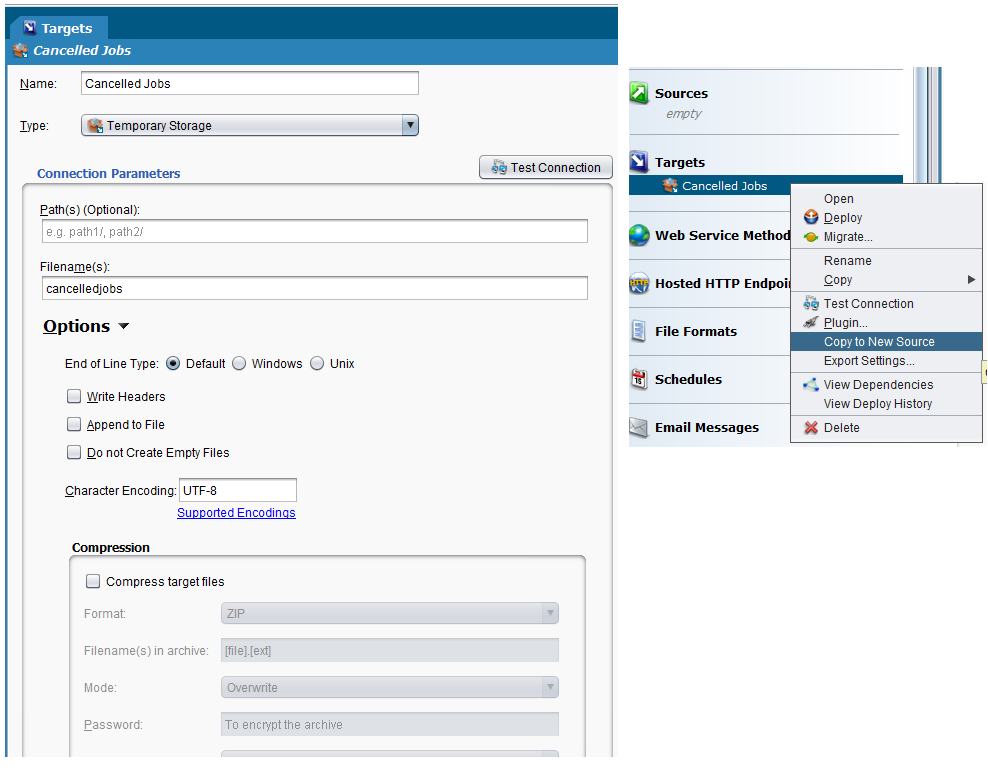
Crear una fuente a partir de un destino es simple: primero, cree un destino y asígnele un nombre único. Luego, use la opción "Copiar a nueva fuente" para crear la fuente utilizando el mismo nombre de archivo (haga clic con el botón derecho en el nombre del destino en el árbol de elementos del proyecto en el panel del lado izquierdo de la pantalla y seleccione "Copiar a nueva fuente" en el menú desplegable). El destino y las fuentes son en realidad independientes, por lo que cambiar unilateralmente el nombre de un archivo en un destino no afecta a una fuente con el mismo nombre.
-
En un ambiente de agente agrupado (agentes privados o en la nube), siempre que las operaciones que utilizan el almacenamiento temporal estén vinculadas (encadenadas) entre sí, todas las lecturas y escrituras de archivos temporales se realizarán en el mismo servidor alojar.
-
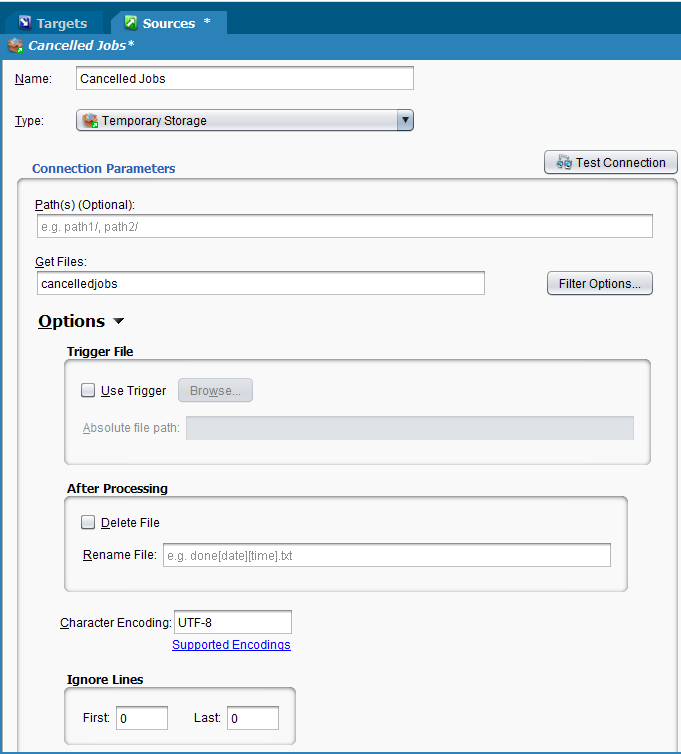
En el caso de los destinos, la opción predeterminada es sobrescribir el archivo. Esto se puede cambiar con la opción "Agregar al archivo" (haga doble clic en el destino, haga clic en Opciones y haga clic en la casilla de verificación "Agregar al archivo"). Cuando se lee el archivo, es necesario tratarlo de manera que una operación posterior no continúe agregándolo al archivo. Cuando se lee el archivo como origen, generalmente se elimina o archiva. Una forma sencilla de hacerlo es elegir "Eliminar archivo" o "Cambiar nombre de archivo" en el origen (haga doble clic en el origen, haga clic en Opciones y haga clic en la casilla de verificación "Eliminar archivo" o ingrese un nombre en el campo "Cambiar nombre de archivo").
-
Hay varias palabras clave entre corchetes que se pueden utilizar en el nombre del archivo:
- fecha - inserta AAAA-MM-DD
- fecha_hora - inserta AAAA-MM-DD_HHMMSS
- hora - inserta HHMMSS
- ext - sustituye la extensión del archivo
- archivo - sustituye el nombre del archivo
- secuencia - inserta el número de secuencia (1,2,3) del archivo
- único - inserta un GUID para crear un nombre de archivo único. Si se utiliza, la operación de "lectura" deberá utilizar un tipo de fuente de "Usar fuente de la operación anterior" o un comodín en la fuente.
- Es posible construir su propia parte de nombre de archivo 'única' mediante la creación de un secuencia de comandos de preoperación que utiliza una variable global asignada a un guid: $unique_filename = Guid(). Luego, pase '[unique_filename]' al origen y al destino.
- Se puede leer un archivo temporal en el estudio creando un secuencia de comandos con la función ReadFile(): ReadFile("\<TAG>Sources/test\</TAG>"). Luego, pruebe el secuencia de comandos. Tenga en cuenta que esto solo funciona de manera confiable si hay un solo agente privado.
Archivos temporales vs variables globales como orígenes y destinos
En lugar de leer y escribir en archivos temporales en un agente, es posible utilizar una variable global.
Ventajas de utilizar variables globales como fuente o destino
- Más fácil de escribir. Para escribir en un archivo temporal en un secuencia de comandos, se necesitan dos funciones: WriteFile() y FlushFile(). Lo mismo se puede hacer en un solo secuencia de comandos simplemente asignando un valor a una variable, como $foo="123", "456", "789".
- Es más fácil de usar en funciones. Es muy conveniente tener una variable global que se pueda pasar a otras funciones, como WriteToOperationLog(). Se puede hacer lo mismo con archivos temporales, pero se requiere una función ReadFile() para obtener los datos.
- Sin limpieza. Dado que se trata de variables globales, cuando se completa la operación, ya sea con éxito o no, los datos no se conservan. En el caso de los archivos temporales, una operación fallida puede dejar archivos huérfanos en el archivo temporal que pueden acumularse rápidamente y superar los límites de almacenamiento.
Ventajas de utilizar archivos temporales como origen o destino
- Más fácil de depurar. Si se utiliza un agente privado, tener acceso al archivo real puede resultar muy útil para depurar los detalles de integración.
- Rica en funciones. Hay muchas funciones de palabras clave integradas útiles para los nombres de archivos de destino. Algunos ejemplos son fecha, fecha_hora, secuencia y único. También se puede usar SCOPE_CHUNK para dividir los archivos temporales en fragmentos.
- Muchas opciones y más control. Tipo de fin de línea, opciones para escribir encabezados, agregar a archivo, no crear archivos vacíos, codificación y compresión de caracteres.
- Dinámico. Las entradas de ruta y nombre de archivo se pueden completar con una variable global, lo que permite establecer los valores en función de las opciones de operación anteriores. Si se construye correctamente, un único destino y origen se pueden reutilizar en múltiples operaciones.