Capturar cambios de datos con cambios de tabla o archivo en Jitterbit Design Studio
Caso de uso
Cuando no son viables otros patrones para la captura de datos modificados (Patrón de integración para la captura de datos modificados mediante consultas basadas en marcas de tiempo Patrón de integración para la captura de datos modificados utilizando valores de campos de origen Patrón de integración para la captura de datos modificados utilizando fuentes de archivos Patrón de integración: captura de datos modificados - en tiempo real/controlada por eventos), este patrón puede aplicarse.
Este patrón se aplica en los casos en que la fuente no tiene una marca de tiempo, no se puede cambiar para proporcionar un campo que se use para consultar o no se pueden enviar cambios.
Este patrón supone que los registros de origen y destino se pueden comparar y que las diferencias se pueden aislar. Por ejemplo, supongamos que una tabla de clientes en un origen tiene 150 filas y la tabla de clientes en el destino tiene 100 filas. El objetivo es determinar las filas en el origen que son Nuevas (no existen en el destino), Diferentes (misma fila y datos diferentes) y Faltantes (la fila no existe en el destino). Si son Nuevas, se insertan en el destino. Si son Diferentes, se actualiza la fila en el destino. Si son Faltantes, se eliminan del destino.
La documentación de la función Diff de Jitterbit tiene explicaciones detalladas de las diferentes funciones Diff : Funciones Diff.
Un caso de uso frecuente de este patrón es que se necesita un proceso para recuperar un cambio en una tabla de base de datos de un período al siguiente.
Advertencia
Las funciones de Diff solo se pueden usar en un solo agente privado, ya que las instantáneas de diferenciación no se comparten. No las use en un grupo de agentes con más de un agente. No son compatibles con los agentes en la nube.
Ejemplo 1: Comparación de base de datos con base de datos
En este ejemplo, el cliente tiene una base de datos que sustenta un sistema transaccional y quería sincronizar ciertos objetos comerciales con un almacén de datos externo para fines de auditoría.
Los pasos básicos son:
- Inicialice el Diff y agregue registros a la instantánea en el disco. Si no es la primera vez que se ejecuta el proceso, se seleccionarán los nuevos registros.
- Pasar nuevos registros a la transformación y actualizar la base de datos de destino.
- Procesar las actualizaciones (cambios desde la última vez que se ejecutó el proceso)
- Pasar a la transformación y actualizar la base de datos de destino
- Procesar las eliminaciones
- Pasar a la transformación y actualizar la base de datos de destino
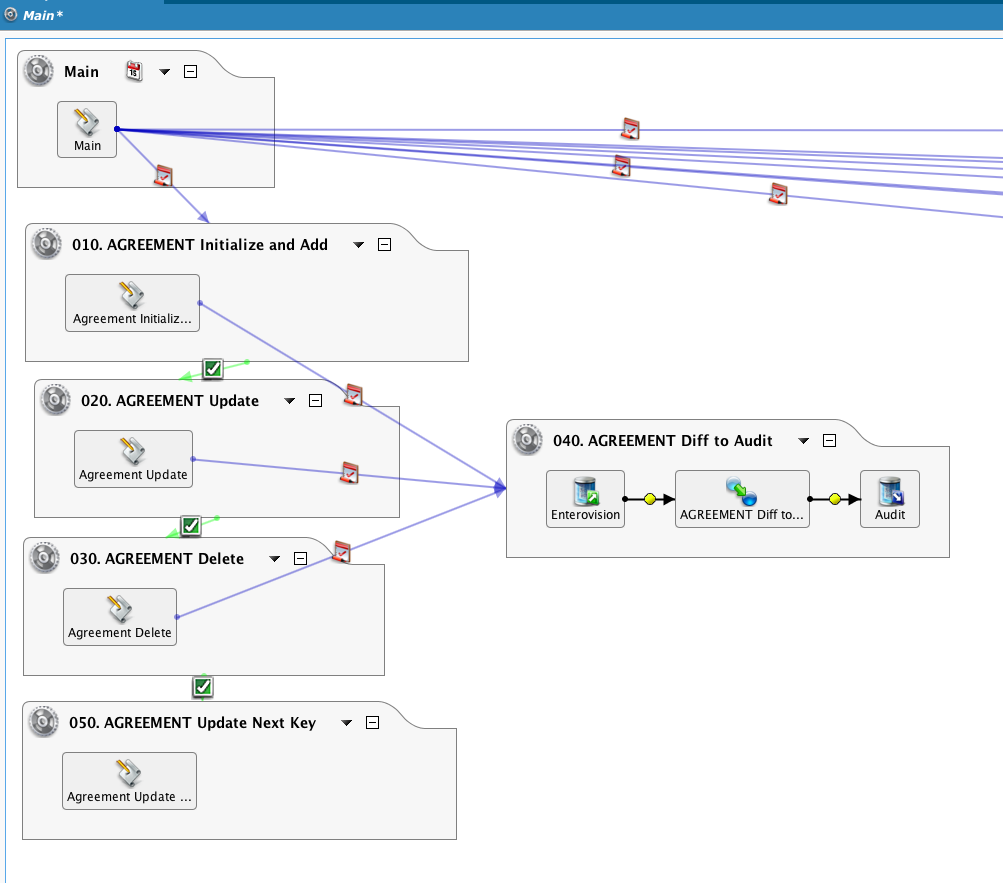
La operación Principal impulsa una serie de operaciones encadenadas, seleccionando solo una tabla como ejemplo.
Al pasar un 'false' argumento, el RunOperation() funciones (vea Funciones generales del generador de fórmulas) se ejecutará de forma asincrónica:
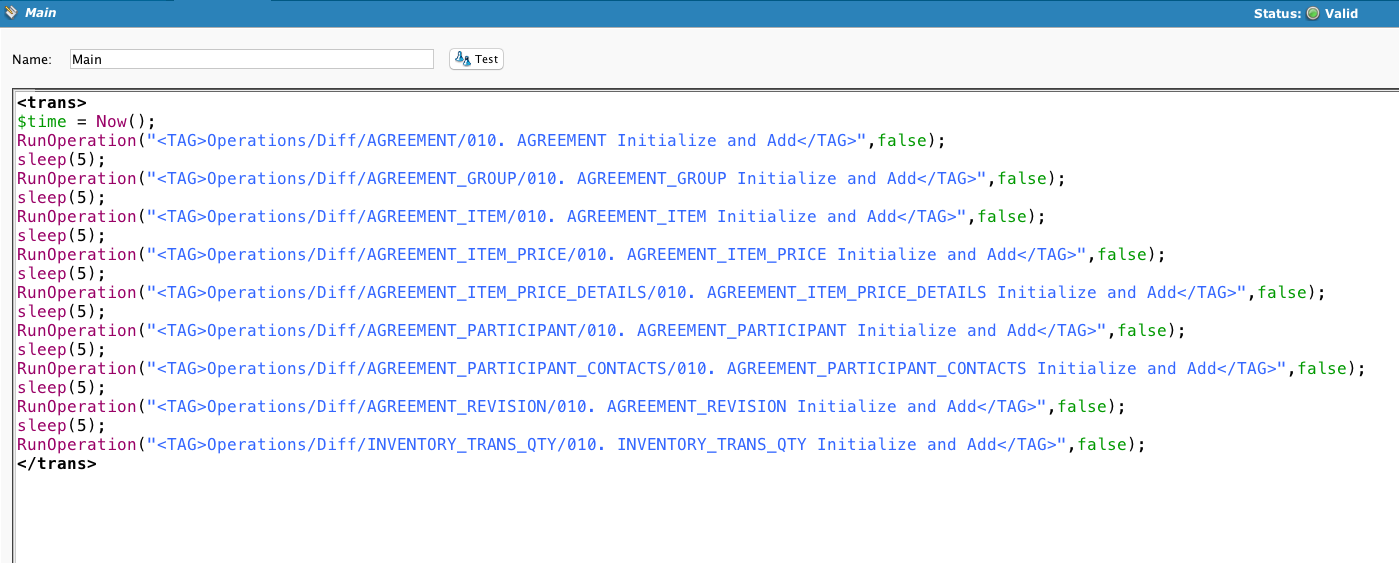
Se llama a InitializeDiff y se evalúa. Si falla, se llama a ResetDiff.
DiffKeyList establece el identificador único del registro.
Si es la primera vez que se ejecuta, se agregarán a la instantánea todos los registros de la fuente. De lo contrario, se seleccionarán los registros nuevos.
Si se produce un fallo se cancela la cadena de operación.
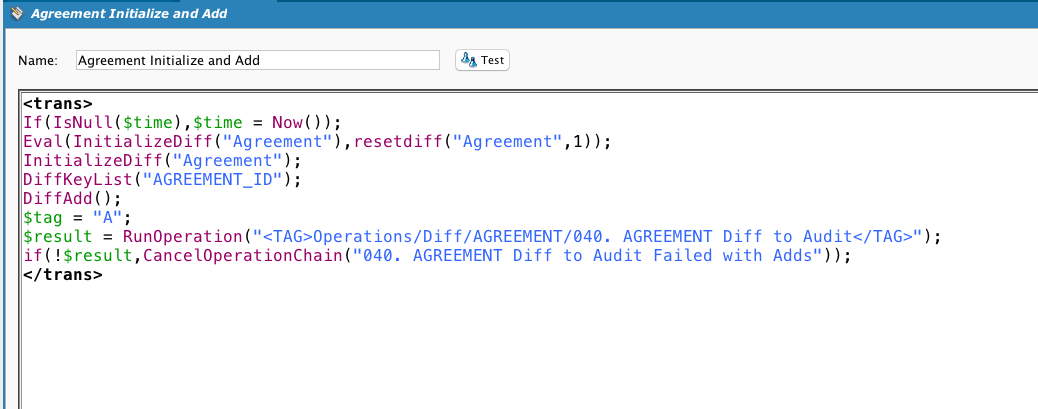
Esta es la transformación que utiliza la operación. Tenga en cuenta que, si bien existe una fuente de base de datos, si la llamada a la operación está precedida por una llamada a Diff, la fuente de la operación no se utiliza. Si se llama a DiffUpdate, se llama a esta operación y obtenemos el resultado de la función DiffUpdate:
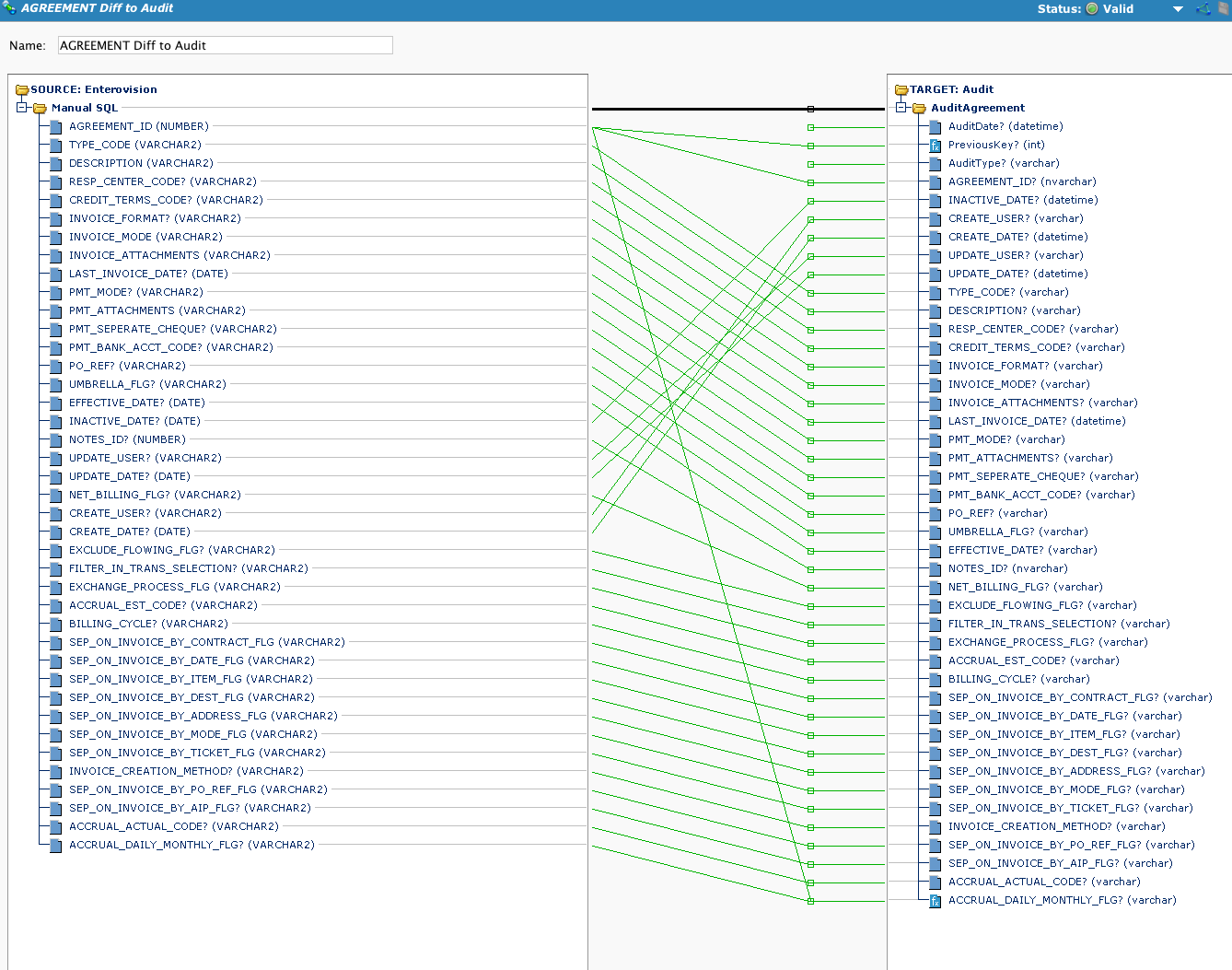
Llama a DiffUpdate. Observe el uso de una etiqueta de variable global para indicar al objetivo qué tipo de acción se realizó.
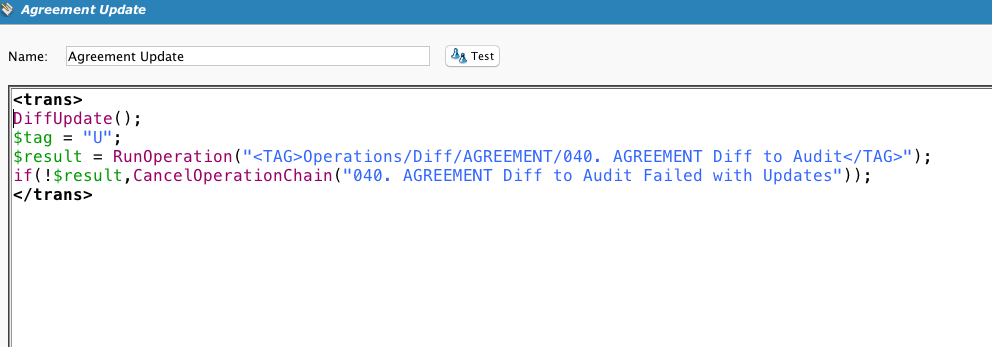
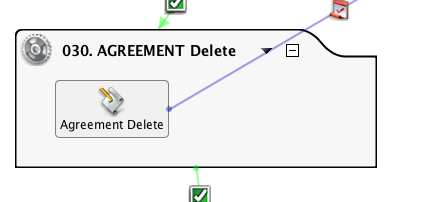
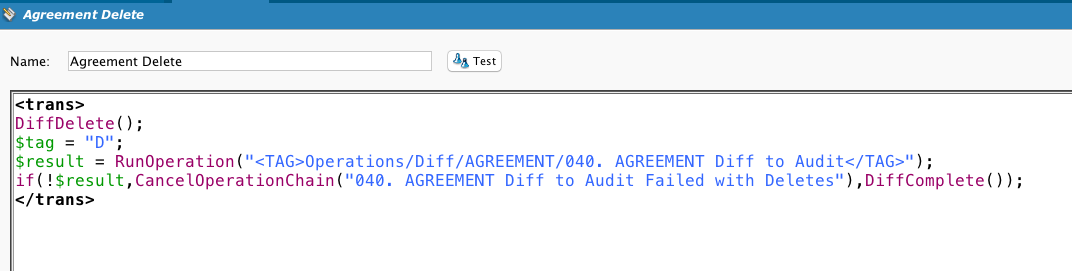
Se muestra este secuencia de comandos para completar la información. El cliente quería almacenar un registro de las filas nuevas y modificadas, no sincronizar dos almacenes de datos. Por lo tanto, los procesos Diff incorporaron un método para generar claves únicas que mostrarán los cambios en el mismo registro a lo largo del tiempo.
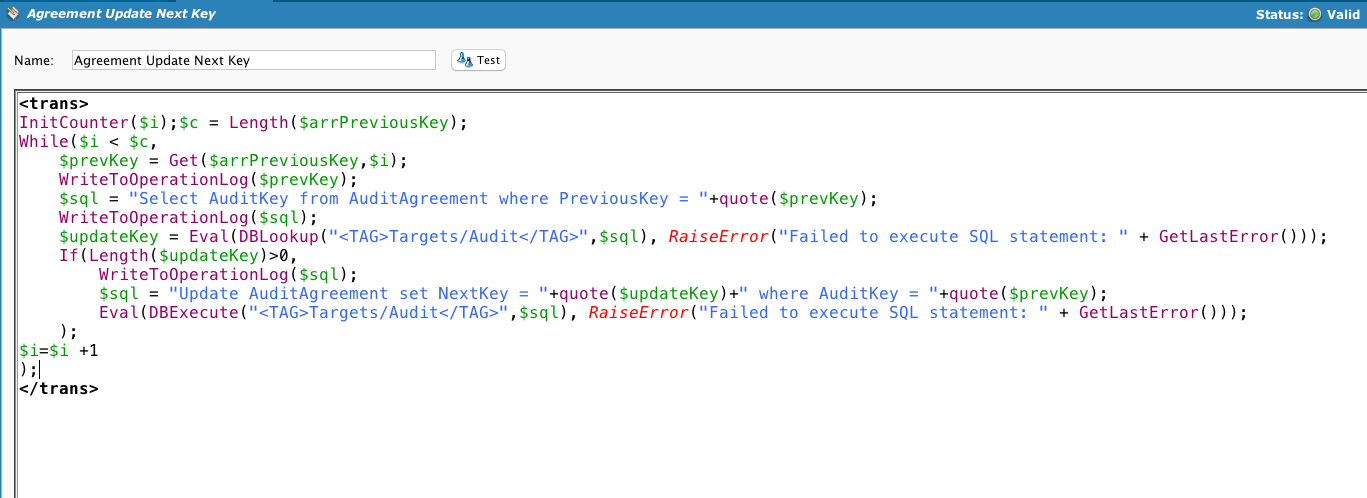
Ejemplo 2: Comparación entre organizaciones
Este ejemplo compara dos objetos de Salesforce simultáneamente.
En general, los pasos de Diff son:
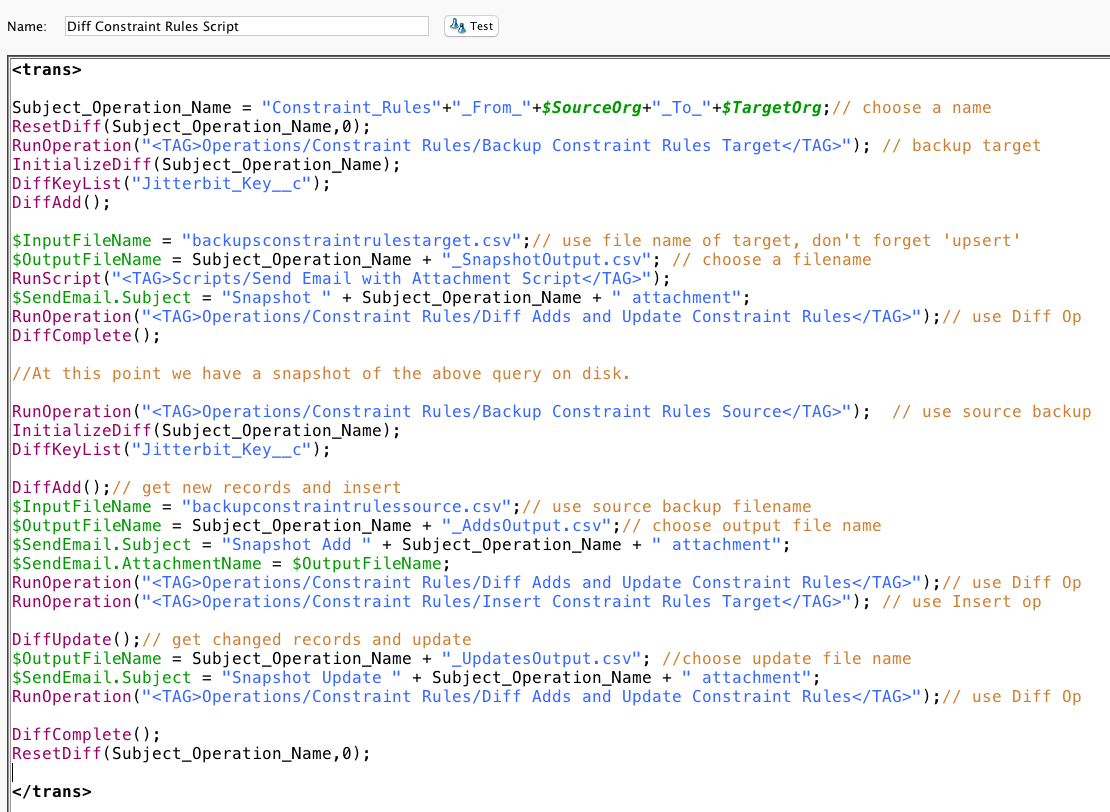
- Borrar el archivo Diff antiguo (ResetDiff). No estamos haciendo un seguimiento de los cambios a lo largo del tiempo. Estamos haciendo un seguimiento de las diferencias entre los archivos de origen y destino en este momento.
- Crear el Diff (InitializeDiff). Esto le asigna un nombre único que se utilizará como clave para el directorio Diff que se creará en el disco del servidor de agente privado. El nombre del objeto se utiliza como nombre del Diff.
- Establezca el campo clave (DiffKeyList). Esto le indicará a Diff qué campo de la fila es el campo clave y se utilizará para comparar filas específicas en el nuevo archivo Diff con filas en el archivo Diff anterior.
- Rellene el Diff (DiffAdd) desde la tabla de clientes de destino (en este caso, un archivo csv creado mediante una consulta a la tabla de clientes de destino). Las filas de la "fuente" (en este caso, el archivo csv creado mediante una consulta a la tabla de clientes de destino) se leen en el archivo Diff. El comportamiento es diferente si el archivo Diff está vacío, es decir, si es la primera vez que se crea el Diff.
- Guardar la Diff (DiffComplete). En este punto, hay una instantánea de la tabla de clientes de destino en el disco del servidor de agente privado.
- Iniciar la comparación del origen (en este caso, un archivo csv creado al consultar la tabla de clientes de origen) con el destino (un archivo csv creado al consultar la tabla de clientes de destino), comenzando con la lectura de los registros en el archivo csv de origen (DiffAdd). Por lo tanto, si bien estamos utilizando la misma función DiffAdd que la anterior, se comporta de manera diferente ya que existe un archivo Diff. Esta vez, compara los dos archivos y genera las nuevas filas según el campo establecido por DiffKeyList
- Comparación basada en cambios (DiffUpdate). Diff genera un hash de los registros individuales tanto en los archivos antiguos como en los nuevos, e identificará los registros modificados en función de la misma clave pero con diferentes hashes. Esto generará las filas modificadas.
- Guardar la Diff (DiffComplete).
- Eliminar la Diff (ResetDiff).
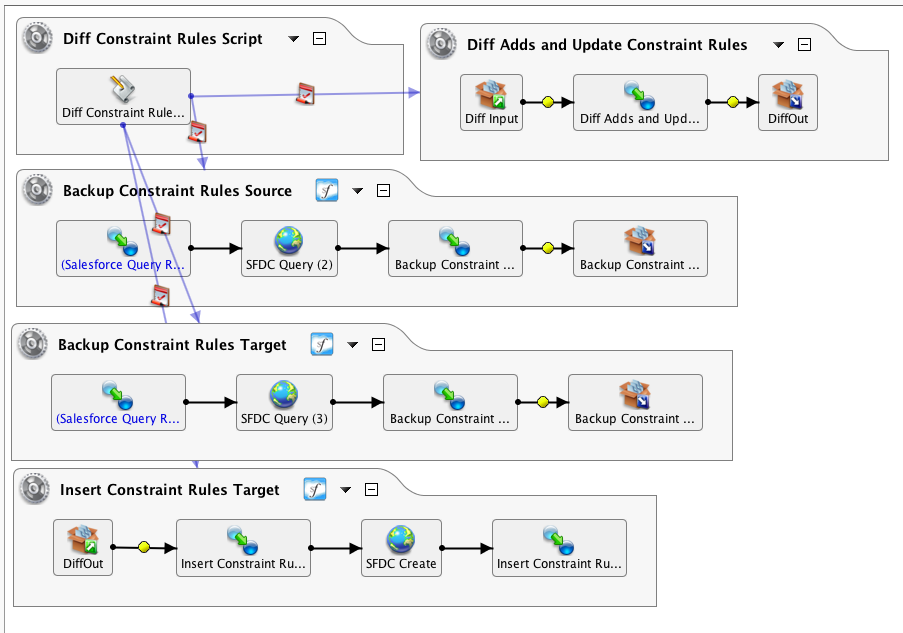
Este ejemplo tiene dos organizaciones de Salesforce con objetos y campos idénticos. La organización de origen contiene datos que se deben agregar o actualizar en la organización de destino. Debido al uso de activadores y actualizaciones, no es posible consultar simplemente la fuente en función de la marca de tiempo de un objeto. Realizar una copia completa, consultando toda la fuente y actualizando en el destino, es un método viable, pero para conjuntos de datos muy grandes puede llevar mucho tiempo. La preferencia aquí fue realizar una migración de las diferencias entre las organizaciones de origen y destino mediante Diff() funciones.
Dado que Diff solo puede trabajar con bases de datos o archivos CSV, las consultas de origen y destino se convierten a ese formato:
Esto consulta el destino y hay una operación similar que consulta la fuente.
Tenga en cuenta que la consultar se limita a los datos comerciales, excluyendo los datos del sistema como LastModifiedDate, que será diferente de la fuente y el destino, así como los ID de registro. Además, se seleccionan los encabezados, ya que son necesarios para ayudar al usuario a ver los datos. El destino de la copia de seguridad es idéntico, excepto por la organización de Salesforce.
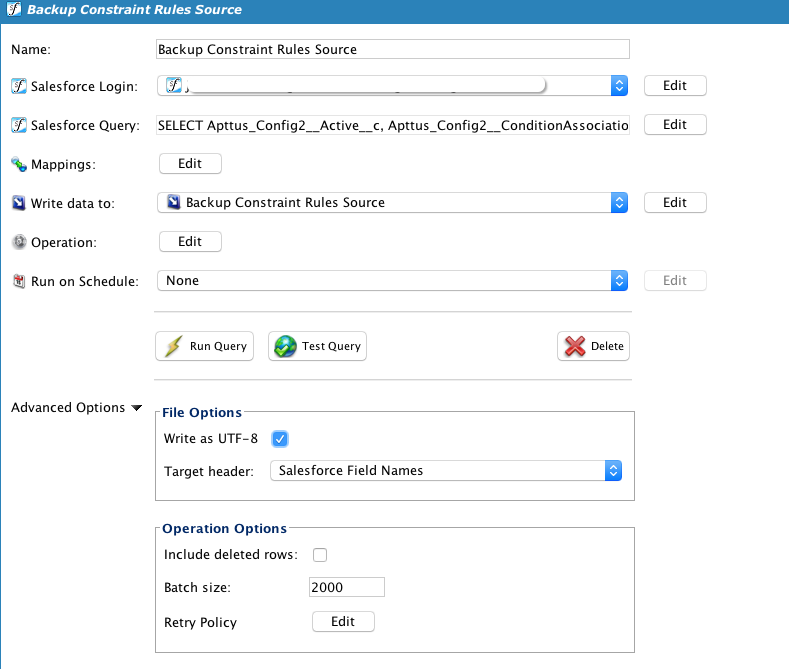

Se utiliza una fuente de almacenamiento temporal, donde se utiliza una variable global para el nombre del archivo y se ignora la primera línea.
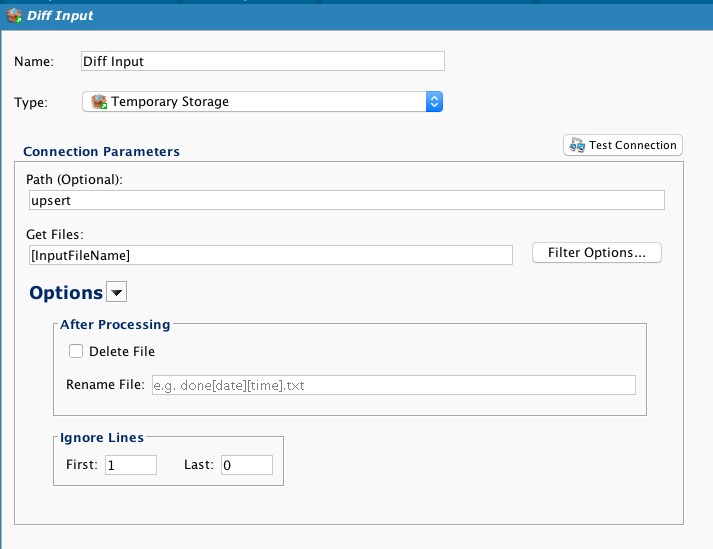
El destino es un archivo de almacenamiento temporal. Puede ser un sitio FTP o un recurso compartido de archivos en red. Nuevamente, se utiliza una variable global para seleccionar dinámicamente el nombre del archivo.
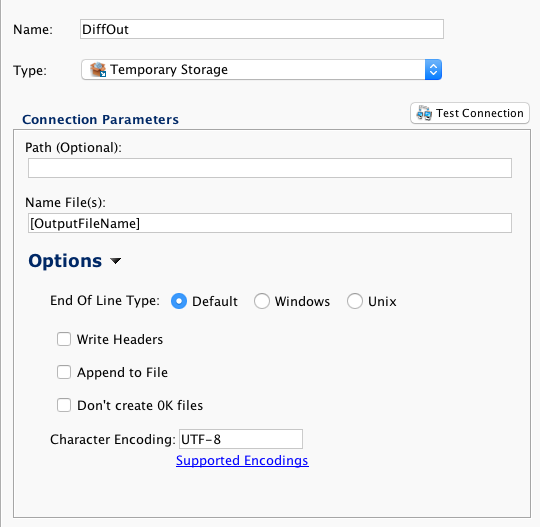
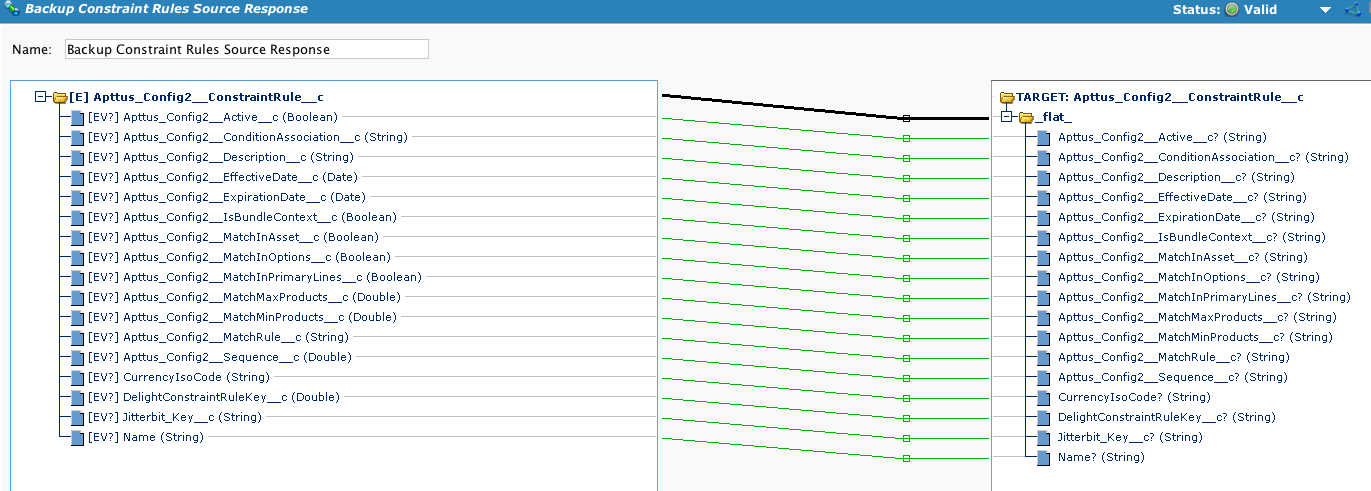
En este ejemplo se utiliza un objeto Apttus estándar. Este formato de archivo se utilizará repetidamente en la cadena de operaciones. En este caso, los objetos de origen y destino utilizan un identificador externo denominado "Jitterbit_Key" para asociar registros en las diferentes organizaciones. Diff lo utilizará para identificar las filas nuevas y las filas actualizadas.
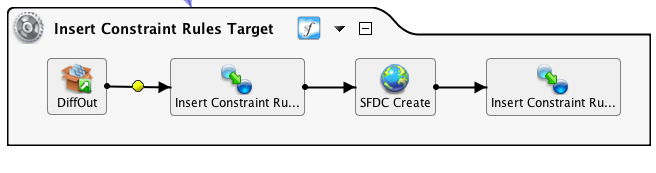
Esto realizará la inserción de datos según la salida del archivo Diff.
Nuevamente, el uso de una variable global para seleccionar dinámicamente un nombre de archivo:
Reutilización del formato de archivo, que ahora está asignado al objeto Apttus.

Notas importantes:
Subject_Operation_Name es una variable local y se utiliza para almacenar una cadena que se utiliza repetidamente.
Mejores prácticas
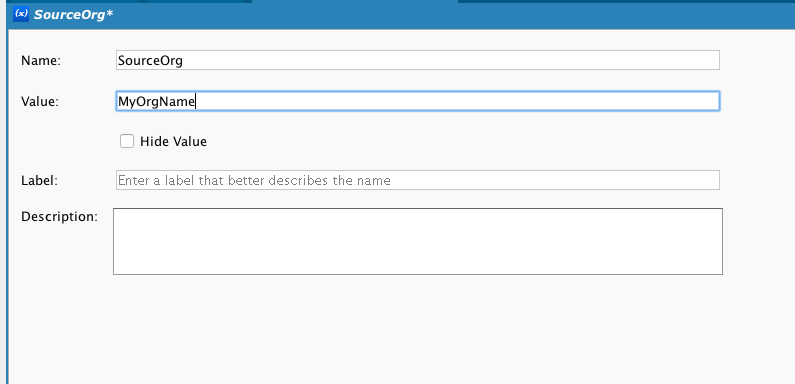
SourceOrg y TargetOrg son variables de proyecto de Jitterbit que contienen el nombre de la organización. Una variable de proyecto es un valor que está disponible para todos los objetos de Jitterbit que pueden trabajar con una variable. Tenga en cuenta que el formato en el editor de secuencia de comandos es verde y está en cursiva:
Las variables del proyecto se definen en Jitterbit Design Studio:
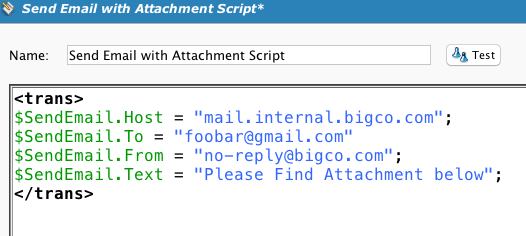
Otro secuencia de comandos llamado habilita la captura de la salida y la agrega como archivo adjunto a un correo. Para ello se requiere el uso de un complemento llamado Enviar correo con archivo adjunto en el destino. (Ver actualización a continuación).
El Diff Add and Update La operación se utiliza repetidamente ya que los orígenes y los destinos utilizan una variable ("$OutputFile") para seleccionar dinámicamente los archivos que se procesarán. Esto permite en gran medida la reutilización de operaciones.
Método actualizado que utiliza destinatarios de correo
Las versiones actuales de Harmony incluyen destinos de correo; son superiores para manejar archivos adjuntos de correo ya que no requieren el uso de un complemento.
Primero, crea un destino de Correo:
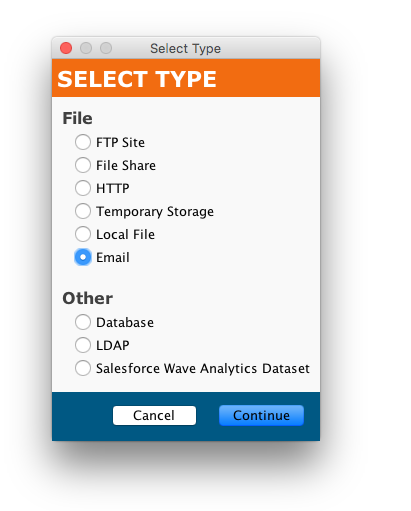
En segundo lugar, crea un correo y establece el límite de tamaño de los archivos adjuntos:
Ahora puede utilizar este destino de correo para enviar la salida capturada.