Persist data for later processing using Temporary Storage in Jitterbit Design Studio
Use case
A common pattern when integrating data is the use of files to temporarily hold data that is used as part of the process of transforming or moving the data from source to target.
Examples
Temporary files
A typical pattern is to query a source, save the output in a temporary file, then read the output in the next step.
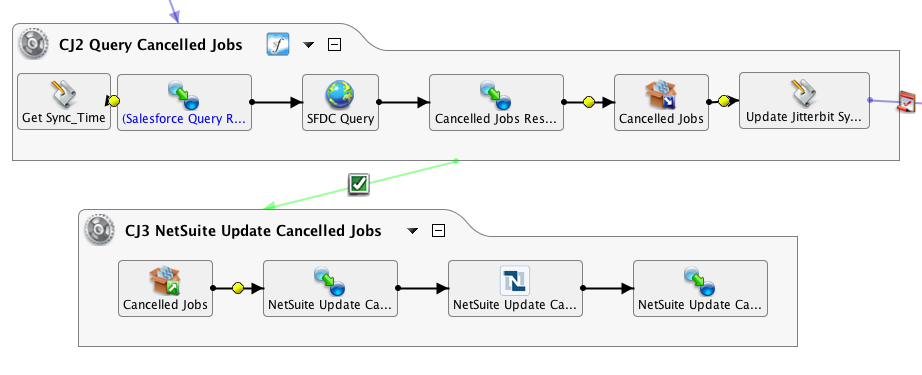
In the above example, a Salesforce query is run periodically, generating output which is written to a target called Cancelled Jobs. In the second operation, a source by the same name is read from as input into a NetSuite update.
Use Temporary Storage considerations
- Temporary Storage is written to the default operating system's temp directory on the agent that is performing the work. In the case of a single private agent, then it is that private agent's server host's default temp directory. If the agent group is running more than one private agent, then it is the temp directory on the server host for whichever particular agent is doing the work. If you are writing to Temporary Storage on cloud agents (which are clustered), it is written to whichever particular cloud agent's server host.
- By default, Temporary Storage is deleted after 24 hours by a Jitterbit Clean-up service
-
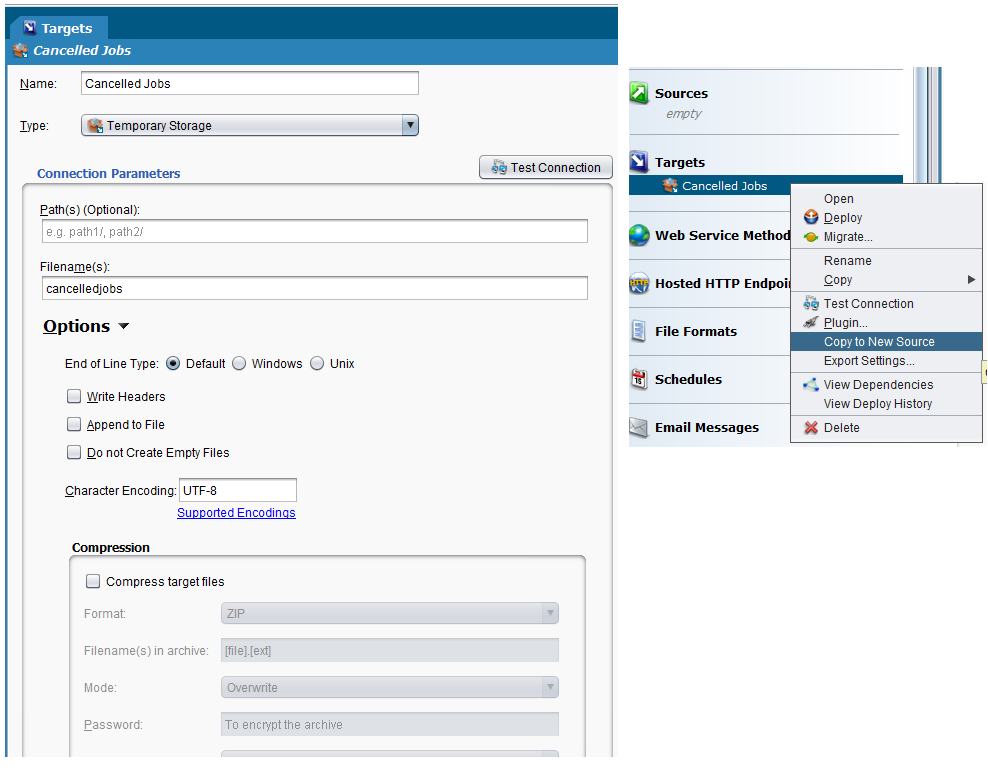
Building a source from a target is simple: First, build a target and give it a unique name. Then use the "Copy to New Source" option to create the source using the same filename (Right-click on the target name in the Project Items tree in the panel on the left side of the screen and select "Copy to New Source" in the dropdown menu.). The target and sources are actually independent, so unilaterally changing a filename in a target does not affect a source of the same name.
-
In a clustered agent environment (private or cloud agents), as long as the operations using the temporary storage are linked (chained) together, then all the temp file reads and writes will happen on the same server host.
-
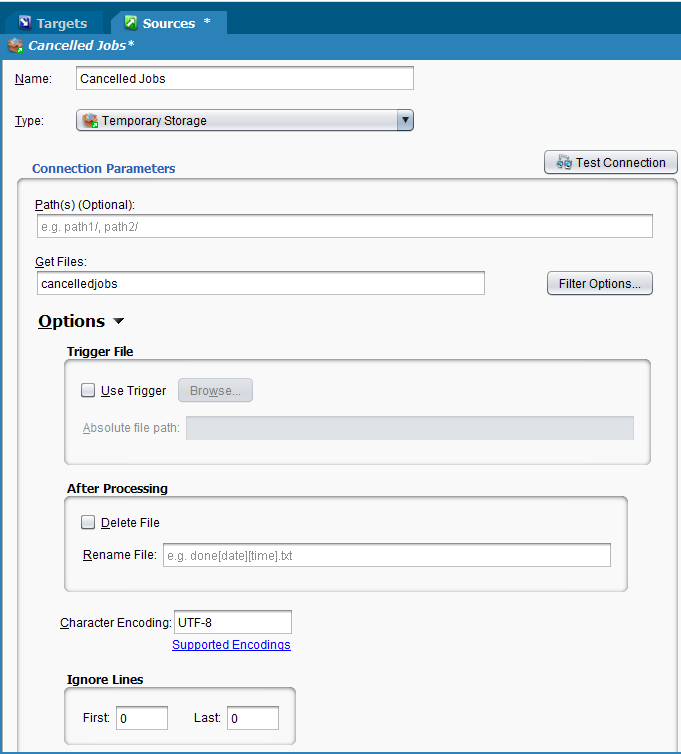
For targets, the default is to overwrite the file. This can be changed with the "Append to File" option (Double-click on the target, click on Options and click on the "Append to File" checkbox). When the file is read, it needs to be treated such that a later operation does not continue to append to the file. When the file is read as the source, usually the file is deleted or archived. A simple way to do this is to choose "Delete File" or "Rename File" in the source (Double-click on the source, click on Options and click on the "Delete File" checkbox or enter a name in "Rename File" field.).
-
There are several bracketed keywords that can be used in the file name:
- date - inserts YYYY-MM-DD
- date_time - inserts YYYY-MM-DD_HHMMSS
- time - inserts HHMMSS
- ext - substitutes the file extension
- file - substitutes the file name
- sequence - inserts the sequence number (1,2,3) of the file
- unique - inserts a GUID to create a unique file name. If this is used, the 'reading' operation will have to use a source type of "Use Source From Previous Operation", or a wildcard in the source.
- It is possible to construct your own 'unique' filename part by building a pre-operation script that uses a global variable assigned to a guid: $unique_filename = Guid(). Then pass '[unique_filename]' to the source and target.
- A temporary file can be read in the studio by building a script with the ReadFile() function: ReadFile("\<TAG>Sources/test\</TAG>"). Then test the script. Bear in mind that this only works reliably if there is a single private agent.
Temporary files vs global variables as sources and targets
Instead of reading and writing to temporary files on an agent, it is possible to use a global variable instead.
Advantages of using global variables as a source or target
- Easier to write. To write to a temporary file in a script, it takes two functions: WriteFile() and FlushFile(). The same can be done in a single script by simply assigning a value to a variable, such as $foo="123","456","789".
- Easier to use in functions. Having a global variable that can be passed to other functions, such as WriteToOperationLog(), is very convenient. The same can be done with temporary files, but requires a ReadFile() to get the data.
- No clean up. Since dealing with global variables, when the operation is completed, either successfully or not, the data is not persisted. In the case of temp files, a failure operation may leave orphaned files in temp that can quickly build up and exceed storage limits.
Advantages of using temporary files as a source or target
- Easier to Debug. If using a private agent, having access to the actual file can be very helpful to debug integration details
- Function-rich. There are many handy built-in keyword features for Target filenames. Examples are date, date_time, sequence, unique. Also can use SCOPE_CHUNK to break temporary files into chunks.
- Lots of options and more control. End of Line type, options to write headers, append to file, do not create empty files, character encoding and compression.
- Dynamic. The path and filename entries can be filled with a global variable, thus allowing the values to be set based on previous operation choices. If properly constructed, a single target and source can be reused by multiple operations.