Eine Datei in einzelne Datensätze aufteilen mit SCOPE_CHUNK in Jitterbit Studio
Einführung
Dieses Entwurfsmuster kann verwendet werden, um die Daten in einer Mehrfachdatensatzdatei in mehrere Dateien aufzuteilen, wobei jede Datei einen einzelnen Datensatz enthält, unter Verwendung der SCOPE_CHUNK-Präfixsyntax der Set Funktion.
Tipp
Dieses Muster wird empfohlen, wenn die Quelldaten flach (nicht-hierarchisch) sind und die Operation keine Transformation enthält, die bedingte Logik verwendet. Für komplexe (hierarchische) Quelldaten siehe Eine Datei in einzelne Datensätze aufteilen mit SourceInstanceCount.
Anwendungsfall
In diesem Szenario enthalten die Quelldaten mehrere Datensätze, und der Geschäftsprozess oder der Zielendpunkt erfordert, dass die Datensätze einzeln verarbeitet werden.
Entwurfsmuster
Dieses Entwurfsmuster besteht darin, die Datei mit einer Operation zu lesen, bei der die Transformation dasselbe Quell- und Zielschema verwendet. Dieses Muster hat folgende Hauptmerkmale:
- Im ersten Feld der Transformation, die die Daten verarbeitet, wird die
SetFunktion verwendet, um eine Variable festzulegen, die mitSCOPE_CHUNKbeginnt, gefolgt von zusätzlichem Text zur Konstruktion des Variablennamens. Das erste Argument erstellt den Ausgabedateinamen, typischerweise unter Verwendung eines Datensatzidentifikators aus den Quelldaten. Die Dateinamen müssen eindeutig sein, um ein Überschreiben zu vermeiden, daher kann ein Datensatzzähler oder eine GUID als Teil des Dateinamens verwendet werden. - Ein Dateispeicherziel wie Temporärer Speicher oder Lokaler Speicher muss verwendet werden. (Die Verwendung einer Variablen wird nicht unterstützt.) Es wird empfohlen, einen Pfad zu definieren. Der Dateiname sollte mit dem globalen Variablennamen konfiguriert werden, der in der
SetFunktion verwendet wird. - Die Betriebsoptionen müssen mit Chunking aktivieren ausgewählt, mit einer Chunk-Größe von
1, Anzahl der Datensätze pro Datei von1und Maximale Anzahl von Threads von1konfiguriert werden. - Zur Laufzeit wird jeder Datensatz gelesen und mit einem eindeutigen Dateinamen versehen und einzeln an das Ziel geschrieben.
Nach der Verwendung dieses Musters besteht der nächste Schritt typischerweise darin, die FileList Funktion zu verwenden, um das Array der Dateinamen im Verzeichnis abzurufen (konfigurieren Sie die Datei-Verzeichnis Lesen-Aktivität mit dem * Platzhalter), dann durch das Array zu iterieren und jede Datei in die Quelle für die nächste Operation zu lesen.
Beispiele
Beispiele, die das oben beschriebene Entwurfsmuster verwenden, werden für zwei verschiedene Arten von Quelldaten bereitgestellt: eine flache CSV-Datei und eine hierarchische JSON-Datei.
Flache CSV
Diese Operationenkette wendet das oben beschriebene Entwurfsmuster an, um flache CSV-Daten in eine Datei für jeden Datensatz zu splitten. Jede Nummer entspricht einer Beschreibung des Operationsschrittes unten. Für zusätzliche Details siehe die Screenshots für das hierarchische JSON Beispiel.
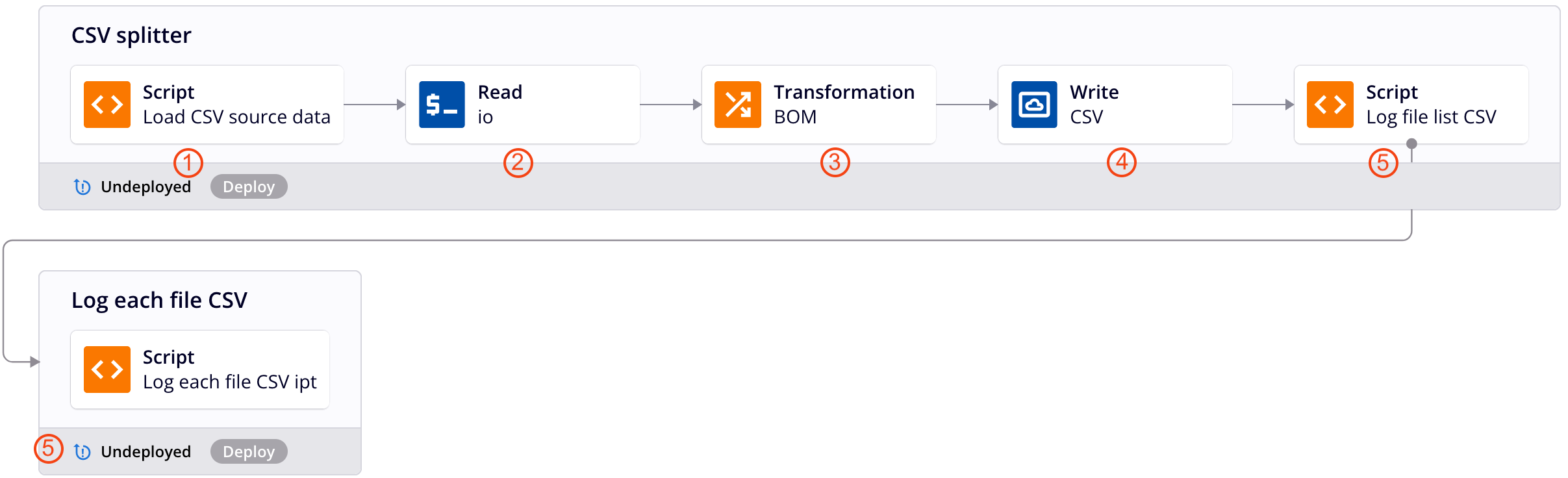
-
Das Skript weist die Quelldaten einer globalen Variablen mit dem Namen
io(Eingabe/Ausgabe) zu. (Ein Skript wird zu Demonstrationszwecken verwendet; die Quelldaten könnten auch von einem konfigurierten Endpunkt stammen.)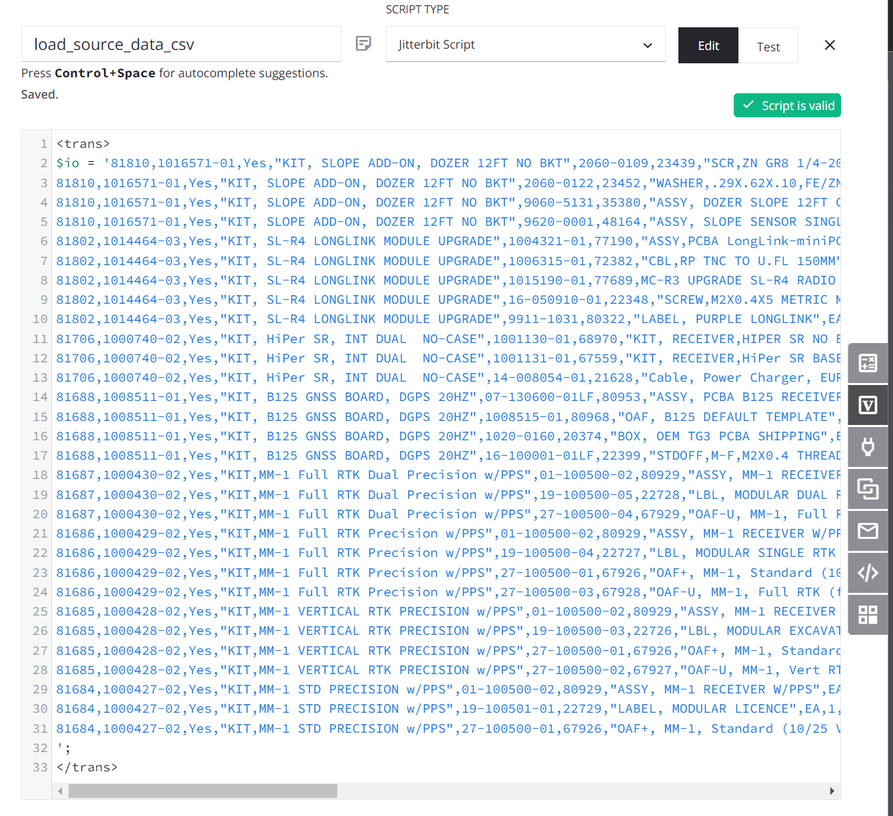
-
Die globale Variable
iowird verwendet, um einen Variablen Endpunkt zu konfigurieren, und eine zugehörige Variable Lesen-Aktivität wird von der Operation als Quelle der Transformation verwendet. -
Innerhalb der Transformation verwenden die Quelle und die Ziele dasselbe Schema, und alle Felder sind zugeordnet. Das erste Datenfeld im Zuordnungsskript der Transformation ist so konfiguriert, dass es
SCOPE_CHUNKverwendet. DieSetFunktion wird verwendet, um eine Variable zu erstellen, die mit dem SatzSCOPE_CHUNKbeginnt und mit der eindeutigen Datensatz-ID aus der Quelle sowie einem Datensatzzähler und einem Suffix von.csvverkettet wird: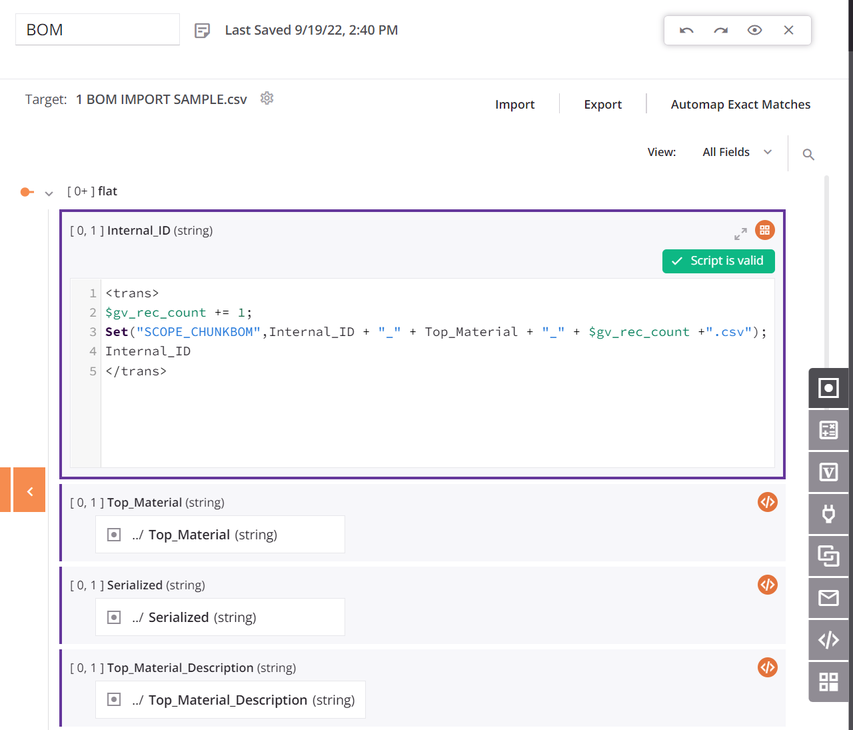
-
Das Ziel ist eine Temporäre Speicherung Schreib-Aktivität, die mit einem Standardpfad und der zuvor definierten globalen Variablen für den Dateinamen konfiguriert ist.
-
Die Skripte dienen der Protokollierung der Ausgabe und sind optional. Das erste Skript erhält eine Liste der Dateien aus dem Verzeichnis und durchläuft die Liste, protokolliert den Dateinamen und die Größe und übergibt dann den Dateinamen an eine Operation mit einem anderen Skript, das den Inhalt der Datei protokolliert. (Siehe die Screenshots für das Hierarchische JSON Beispiel oben.)
-
Die Operationsoptionen müssen mit Chunking aktivieren ausgewählt konfiguriert werden, mit einer Chunk-Größe von
1, Anzahl der Datensätze pro Datei von1und Maximale Anzahl von Threads von1.
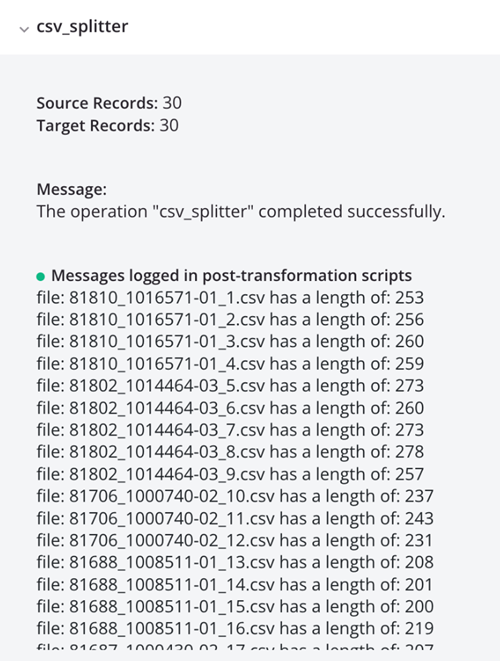
Das Ausführen der Operation führt zu einzelnen CSV-Datensätzen, die in der Protokollausgabe angezeigt werden:
Hierarchisches JSON
Diese Beispiel-Operationskette wendet das oben beschriebene Entwurfsmuster an, um hierarchische JSON-Daten in eine Datei für jeden Datensatz zu splitten. Jede Nummer entspricht einer Beschreibung des Operationsschrittes unten.
Hinweis
Dieses Entwurfsmuster ist nicht mehr die empfohlene Methode zum Splitten hierarchischer JSON-Daten. Für die empfohlene Methode siehe Eine Datei in einzelne Datensätze aufteilen mit SourceInstanceCount.
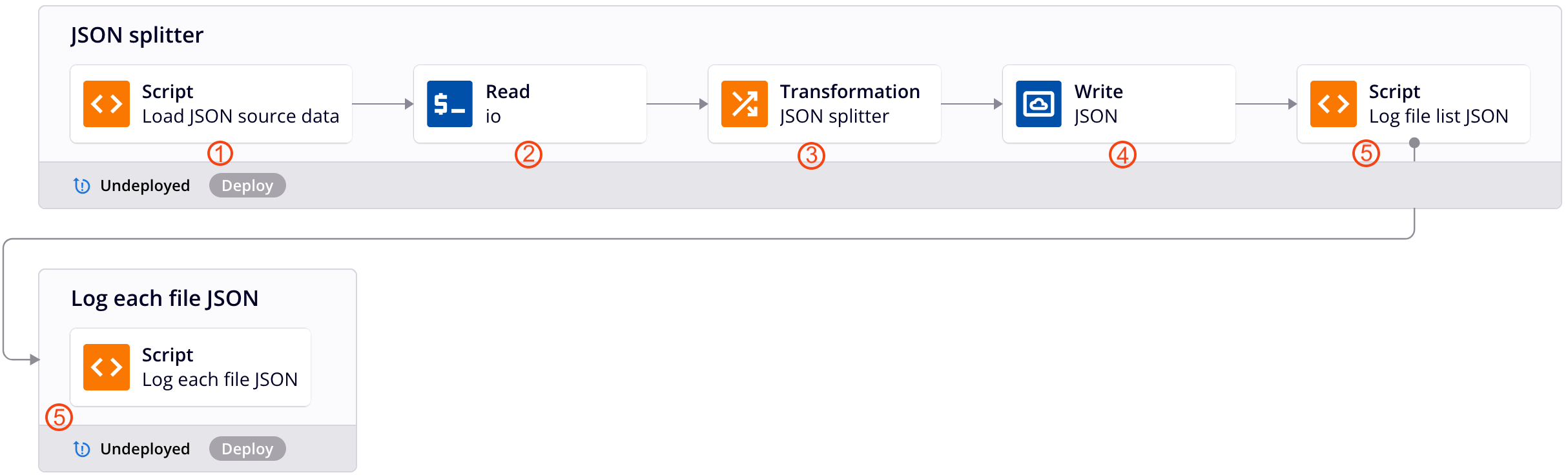
-
Das Skript weist die Quelldaten einer globalen Variablen mit dem Namen
io(Eingabe/Ausgabe) zu. (Ein Skript wird zu Demonstrationszwecken verwendet; die Quelldaten könnten auch von einem konfigurierten Endpunkt stammen.)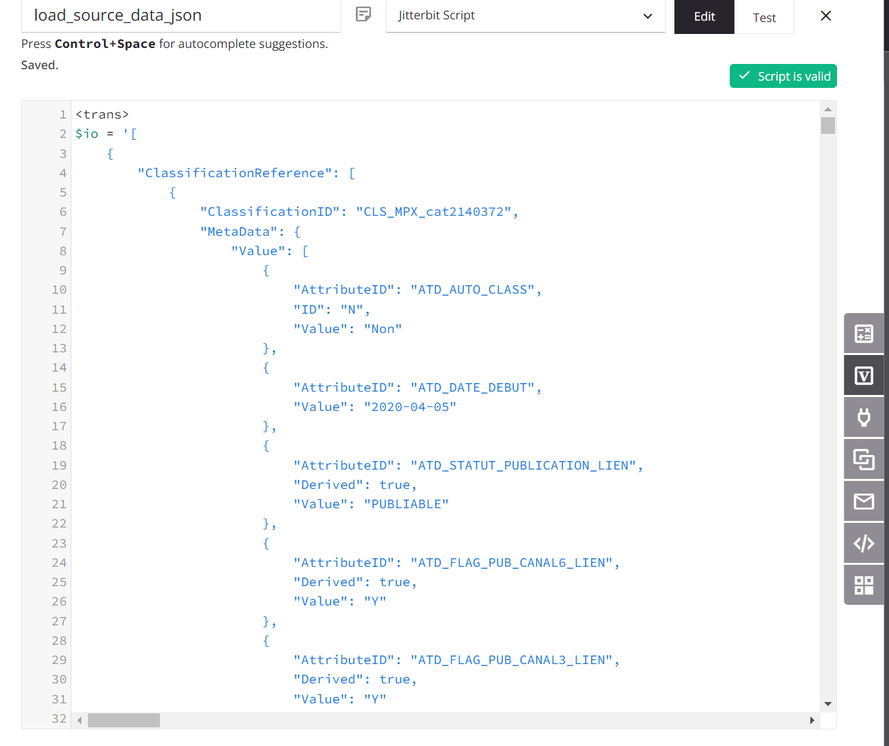
-
Die
io-Globale Variable wird verwendet, um einen Variable Endpunkt zu konfigurieren, und eine zugehörige Variable Read-Aktivität wird von der Operation als Quelle der Transformation verwendet:
-
Innerhalb der Transformation verwenden die Quelle und das Ziel dasselbe Schema, und alle Felder sind zugeordnet:
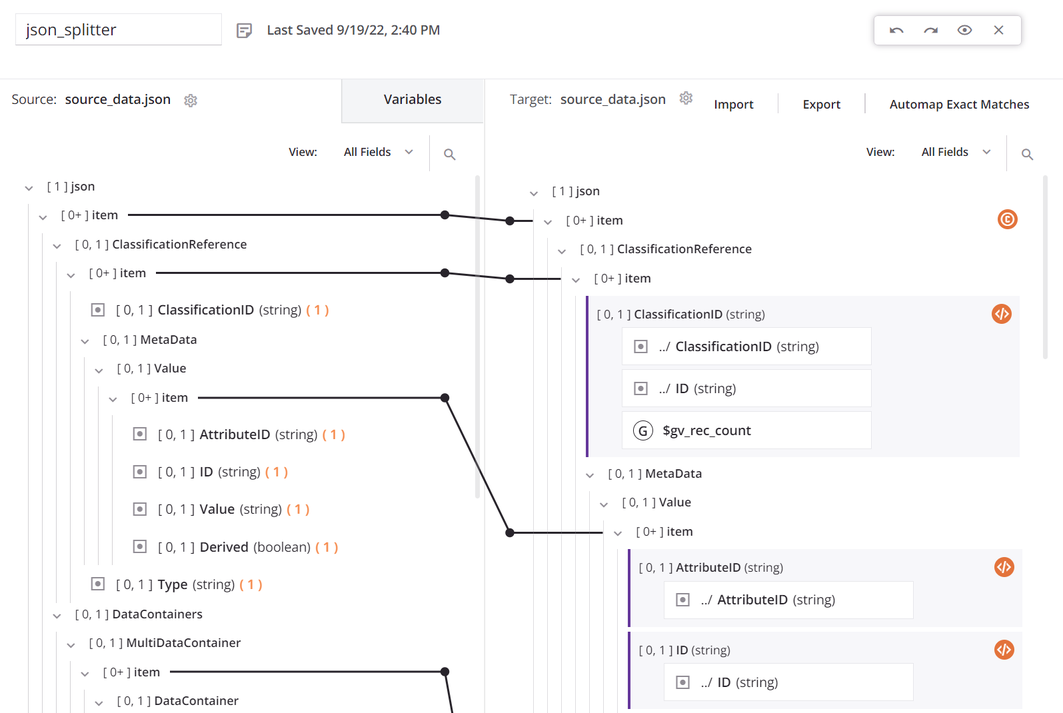
Der oberste
item-Knoten hat eine Bedingung, um die Anzahl der Datensätze zu generieren. Das erste Datenfeld in der Transformationszuordnung ist so konfiguriert, dass esSCOPE_CHUNKverwendet. DieSetFunktion wird verwendet, um eine Variable zu erstellen, die mit dem SatzSCOPE_CHUNKbeginnt und mit der eindeutigen Datensatz-ID aus der Quelle sowie einem Datensatzzähler und einem Suffix von.jsonverkettet wird: -
Das Ziel ist eine Temporary Storage Write-Aktivität, die mit einem Standardpfad und der zuvor definierten globalen Dateinamen-Variable konfiguriert ist:
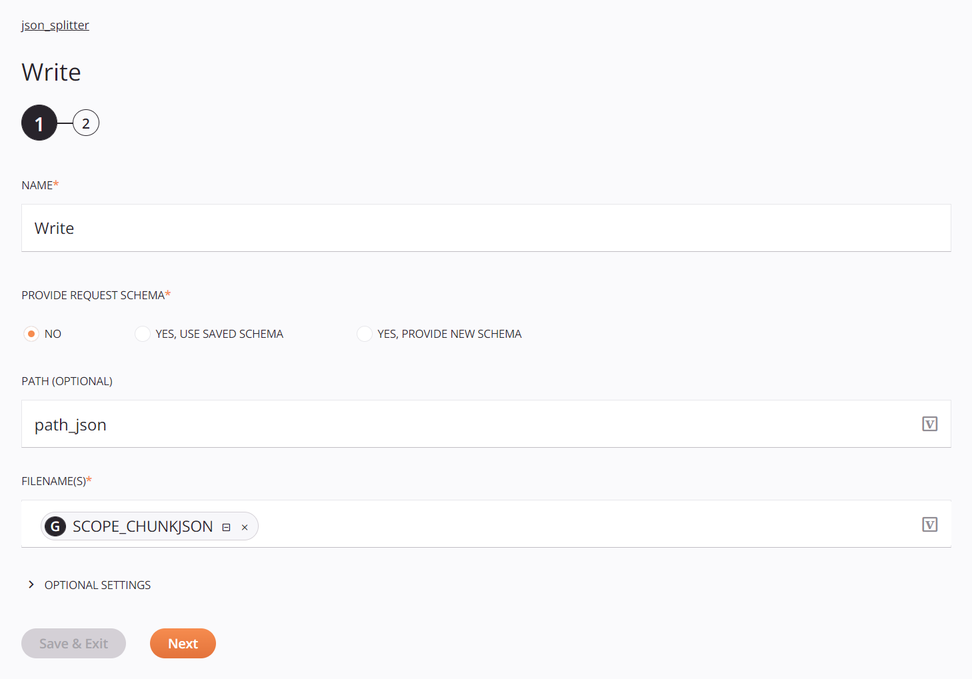
-
Die Skripte dienen der Protokollierung der Ausgabe und sind optional. Das erste Skript erhält eine Liste der Dateien aus dem Verzeichnis und durchläuft die Liste, protokolliert den Dateinamen und die Größe und übergibt dann den Dateinamen an eine Operation mit einem anderen Skript, das den Inhalt der Datei protokolliert:
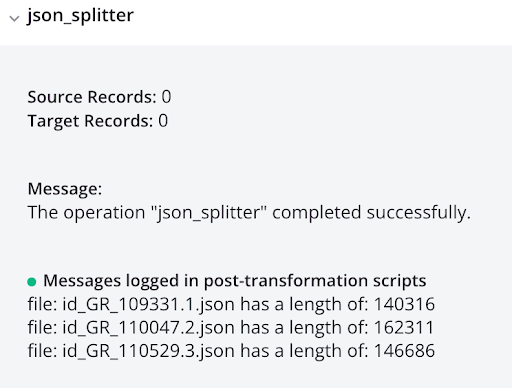
log_file_list_json<trans> arr = Array(); arr = FileList("<TAG>activity:tempstorage/json_splitter/tempstorage_read/Read</TAG>"); cnt = Length(arr); i = 0; While(i < cnt, filename = arr[i]; file = ReadFile("<TAG>activity:tempstorage/json_splitter/tempstorage_read/Read</TAG>",filename); WriteToOperationLog("file: " + filename + " has a length of: " + Length(file)); $gv_file_filter = filename; RunOperation("<TAG>operation:log_each_file_json</TAG>"); i++ ); </trans>log_each_file_json<trans> WriteToOperationLog(ReadFile("<TAG>activity:tempstorage/json_splitter/tempstorage_read/Read</TAG>",$gv_file_filter)); </trans> -
Die Betriebsoptionen müssen so konfiguriert werden, dass Chunking aktivieren ausgewählt ist, mit einer Chunk-Größe von
1, Anzahl der Datensätze pro Datei von1und Maximale Anzahl von Threads von1: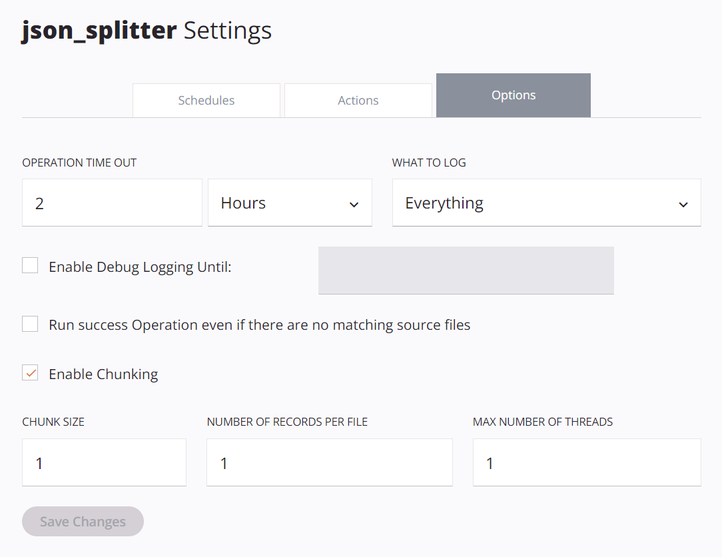
Das Ausführen der Operation führt zu einzelnen JSON-Datensätzen, die im Protokollausgang angezeigt werden: