Schlüsselkonzepte für Transformationen in Jitterbit Studio
Diese Seite erklärt die grundlegenden Konzepte, die Sie verstehen sollten, wenn Sie Transformationen entwerfen und Probleme beheben.
Schemata
Ein Schema definiert die Struktur und Datentypen Ihrer Eingabe- oder Ausgabedaten. Schemata geben an, welche Felder verfügbar sind, ihre Datentypen und wie die Felder organisiert sind:
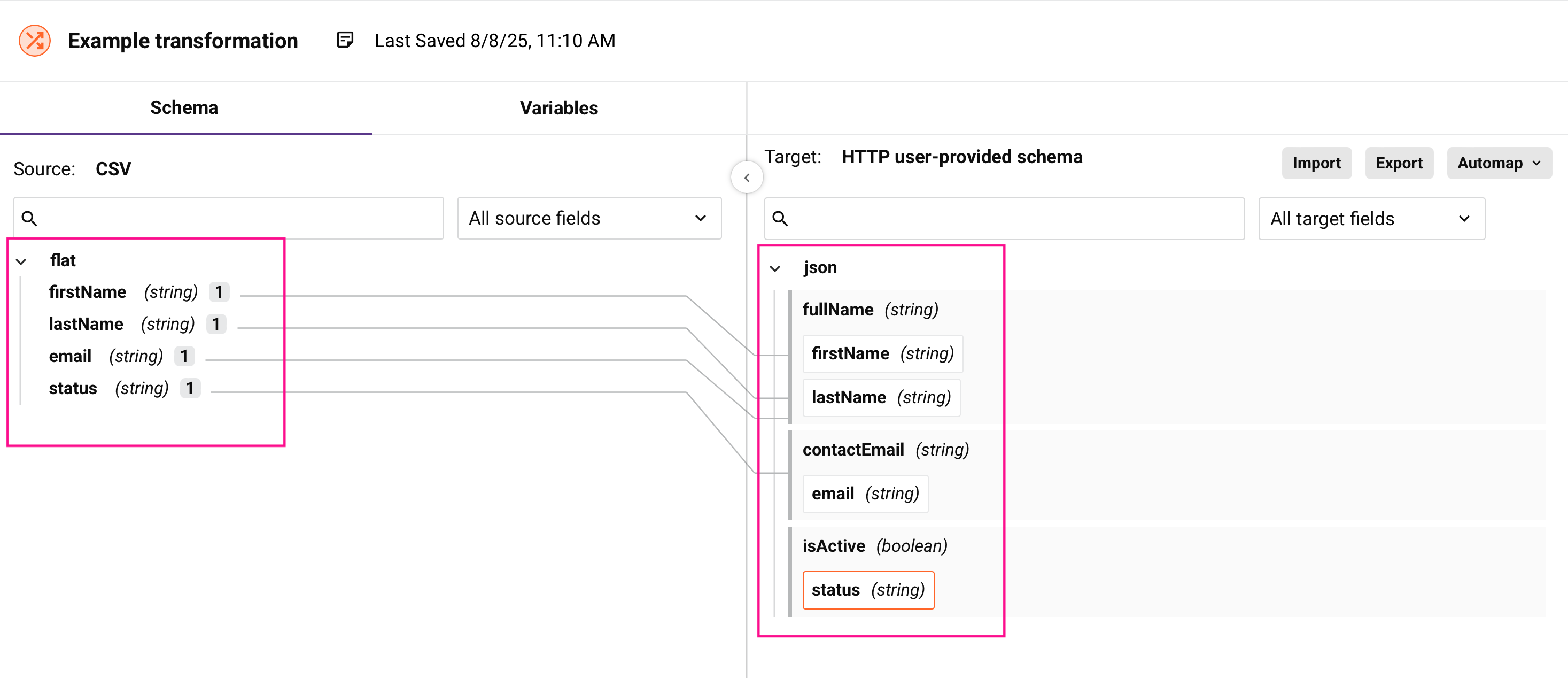
Quellschemata
Das Quellschema beschreibt die Struktur der Daten, die in Ihre Transformation eingehen. Quellschemata können aus diesen Quellen stammen:
-
Aktivitätsgenerierte Schemata: Automatisch erstellt durch Connector-Aktivitäten wie Datenbankabfragen oder API-Aufrufe.
-
Benutzerdefinierte Schemata: Benutzerdefinierte Schemata, die Sie erstellen oder hochladen.
Quellschemata sind optional. Sie benötigen kein Quellschema, wenn Sie nur Variablen, benutzerdefinierte Werte oder skriptbasierte Logik in Ihren Zuordnungen verwenden.
Für weitere Informationen siehe Wählen Sie Schemasourcen.
Zielschemata
Das Zielschema beschreibt die Struktur der Daten, die Ihre Transformation verlassen. Wie Quellschemata können Zielschemata aktivitätsgeneriert oder benutzerdefiniert sein.
Zielschemata sind immer erforderlich. Jede Transformation muss ein Zielschema haben, das die Ausgabestruktur definiert.
Für detaillierte Anleitungen zum Erstellen und Konfigurieren von Schemata siehe Erstellen Sie eine Transformation und konfigurieren Sie Schemata.
Datenstrukturen
Datenstrukturen definieren, wie Informationen innerhalb von Schemata organisiert sind.
Flache Strukturen
Flache Strukturen enthalten Felder auf einer einzigen Ebene ohne Verschachtelung. Beispiele sind diese Formate:
- CSV-Dateien mit Spalten
- Einzelne Datenbanktabellen
- Einfache XML-Dateien ohne verschachtelte Elemente
Beispiel
<customer>
<id>10123</id>
<fullname>ABC Co.</fullname>
<street>1 Main St.</street>
<city>Anytown</city>
<state>NY</state>
<zip>12345</zip>
</customer>
Hierarchische Strukturen
Hierarchische Strukturen enthalten geschachtelte Beziehungen zwischen Feldern und Datensätzen. Beispiele sind diese Formate:
- Komplexe XML-Dateien mit geschachtelten Elementen
- JSON-Objekte mit geschachtelten Eigenschaften
- Datenbankverknüpfungen über mehrere Tabellen
Example
<customer>
<id>10123</id>
<name>ABC Co.</name>
<addresses>
<address>
<street>1 Main St.</street>
<city>Anytown</city>
<state>NY</state>
<zip>12345</zip>
</address>
<address>
<street>1 Time Square</street>
<city>New York City</city>
<state>NY</state>
<zip>54321</zip>
</address>
</addresses>
</customer>
Für weitere Informationen zur Arbeit mit Datenstrukturen siehe Daten abbilden.
Für komplexe hierarchische Datenszenarien siehe Mit hierarchischen Daten arbeiten.
Knoten und Felder
Schemas werden als Baumstrukturen angezeigt, die Knoten und Felder enthalten. Knoten sind Container, die Felder in hierarchischen Strukturen organisieren. Felder enthalten die tatsächlichen Datenwerte.
Jeder Knoten und jedes Feld zeigt diese visuellen Indikatoren:

- Kardinalitäts-Schlüssel: Zeigt Auftretensregeln in Klammern an.
- Name: Der Elementbezeichner aus dem Schema
- Datentyp: Nur für Felder (String, Integer, Boolean usw.)
-
Attribut-/Wertindikatoren: Einige XML-Strukturen enthalten zusätzliche Symbole:
Symbol Bedeutung @Elementattributdaten, zum Beispiel @image#Elementtextdaten, zum Beispiel #text
Knoten
Knoten sind Container, die Felder in hierarchischen Strukturen organisieren:
- Caret: Knoten erweitern und reduzieren.
- Fette Namen: Zeigen Knoten an, die Zuordnungen enthalten, wenn sie reduziert sind.
- Standarderweiterung: 8 Ebenen tief für Schemata mit weniger als 750 Knoten, 5 Ebenen tief für größere Schemata.
Sie können Daten nicht direkt auf Knoten abbilden. Stattdessen bilden Sie Daten auf die Felder ab, die Knoten enthalten.
Felder
Felder halten die tatsächlichen Datenwerte und haben diese Eigenschaften:
- Name: Der Bezeichner des Feldes.
- Datentyp: Der Datentyp, wie String, Integer, Boolean, Datum und andere.
- Format: Optionale Formatierung für Daten oder Währungen.
-
Standardwerte: Wenn ein XSD- oder WSDL-Schema einen Standardwert für ein Element oder Attribut angibt, erscheint der Wert neben dem Feldnamen in der Transformationsoberfläche:

Kardinalitätsnotation
Kardinalitätsschlüssel geben die Auftretensregeln mit UML-ähnlicher Notation an:
| Kardinalitätsschlüssel | Definition |
|---|---|
[1] |
Genau ein Element (erforderlich) |
[1+] |
Eins oder mehrere Elemente (erforderlich, wiederholbar) |
[0,1] |
Null oder ein Element (optional) |
[0+] |
Null oder mehr Elemente (optional, wiederholbar) |
Zuordnungen
Eine Zuordnung verbindet Quelldaten mit Ziel-Feldern und definiert, wie Daten transformiert werden sollen.
Arten von Zuordnungen
-
Direkte Feldzuordnungen: Verbinden Quellfelder direkt mit Zielfeldern. Siehe Felder manuell zuordnen.
-
Benutzerdefinierte Wertzuordnungen: Weisen statische Werte oder Ausdrücke zu. Siehe Benutzerdefinierte Werte verwenden.
-
Variablenzuordnungen: Verweisen auf Projekt- oder globale Variablen. Siehe Variablen zuordnen.
-
Skriptzuordnungen: Verwenden Funktionen und Logik zur Datenumwandlung. Siehe Zuordnung mit Skripten.
-
Bedingte Logik: Wenden unterschiedliche Logik basierend auf Bedingungen an. Siehe Bedingte Logik.
Zuordnungs-Skripte
Alle Zuordnungen werden als Skripte auf Zielfeldern implementiert. Selbst visuelle Zuordnungen wie Drag-and-Drop erstellen zugrunde liegende Skripte. Sie können diese Skripte direkt für komplexe Transformationen bearbeiten.
Für die automatische Zuordnung ähnlicher Strukturen siehe Identische Strukturen zuordnen.
Schleifen-Knoten
Schleifen-Knoten verarbeiten wiederholende Daten, wie mehrere Datensätze oder Arrays. Wenn Sie Felder innerhalb von Schleifen-Knoten zuordnen, verarbeitet die Transformation jede Iteration der Daten.
Automatische Schleifenerzeugung
Schleifenknoten werden automatisch generiert, wenn Sie Felder aus sich wiederholenden Quelldaten auf sich wiederholende Zielstrukturen abbilden. Eine Iteratorzeile erscheint, die zeigt, wie die Transformation durch die Daten schleifen wird.
Manuelle Schleifendefinition
Sie können Schleifenknoten manuell definieren, wenn die automatische Generierung nicht Ihren Datenverarbeitungsanforderungen entspricht. Dies ist nützlich, wenn Sie mehrere Ebenen von sich wiederholenden Daten haben und steuern müssen, welche Ebene die Iteration antreibt.
Für umfassende Anleitungen zur Arbeit mit sich wiederholenden Daten siehe Daten Schleifen steuern.
Variablen
Variablen sind dafür konzipiert, Werte, Konfigurationseinstellungen und kleine Datenmengen zwischen verschiedenen Komponenten Ihrer Integration zu übergeben. Variablen sind nützlich, wenn Sie Informationen wie Sitzungs-IDs, Konfigurationsparameter oder berechnete Werte über Skripte, Transformationen und Operationen hinweg teilen müssen. Diese Variablentypen stehen zur Verfügung:
| Typ | Geltungsbereich | Am besten geeignet für |
|---|---|---|
| [Lokal] | Einzelnes Skript | Berechnungen und temporäre Werte |
| Global | Operationskette | Daten zwischen Operationen übergeben |
| [Projekt] | Gesamtes Projekt | Konfiguration und Anmeldeinformationen |
| Jitterbit | Systemdefiniert | Laufzeitinformationen |
Für Beispiele und detaillierte Informationen zu jedem Variablentyp siehe die jeweiligen Dokumentationsseiten.
Für praktische Beispiele zur Verwendung von Variablen in Transformationen siehe Variablen abbilden.
Datenfluss
Der Datenfluss durch Transformationen erfolgt in dieser Reihenfolge:
-
Eingabe: Eine Quellaktivität liefert Daten, die dem Quellschema entsprechen.
-
Verarbeitung: Eine Transformation wendet Abbildungen, Funktionen und Geschäftslogik an.
-
Ausgabe: Die transformierten Daten, die dem Zielschema entsprechen, gehen an die Zielaktivität.
Das Verständnis dieses Flusses hilft Ihnen, Mappings zu entwerfen, die Daten korrekt verarbeiten, und Probleme zu beheben, wenn Daten nicht wie erwartet transformiert werden.
Für Anleitungen zur Validierung und Fehlersuche siehe Testen und Validieren von Transformationen und Konflikte und Fehler bei der Transformation von Mappings beheben.