Arbeiten mit hierarchischen Daten in Jitterbit Studio
Einführung
Hierarchische Datenstrukturen enthalten eine oder mehrere Eltern-Kind- oder geschachtelte Beziehungen zwischen Feldern und Datensätzen. Häufige Beispiele sind Kunden mit mehreren Adressen, Bestellungen mit Positionen oder Unternehmen mit mehreren Standorten.
In Studio werden hierarchische Strukturen auch als relationale, mehrstufige, komplexe Daten oder Baumstrukturen bezeichnet.
Für Informationen zur Notation von Knoten und Feldern siehe Knoten und Felder in Schlüsselkonzepte.
Hierarchische Strukturen identifizieren
Hierarchische Daten erscheinen in Transformationen als Baumstruktur:
<customer>
<id>10123</id>
<name>ABC Co.</name>
<addresses>
<address>
<street>1 Main St.</street>
<city>Anytown</city>
<state>NY</state>
<zip>12345</zip>
</address>
<address>
<street>1 Time Square</street>
<city>New York City</city>
<state>NY</state>
<zip>54321</zip>
</address>
</addresses>
</customer>
Hierarchische Daten zuordnen
Wenn Sie hierarchische Strukturen zuordnen, müssen Sie innerhalb derselben Ebene zuordnen. Zum Beispiel:
- Elternfelder werden den Elternfeldern zugeordnet.
- Kindfelder werden den entsprechenden Kindfeldern zugeordnet.
- Schleifenknoten werden automatisch für wiederholende Elemente generiert.
Wenn die automatische Zuordnung für Ihre Struktur nicht funktioniert, siehe Daten-Schleifen steuern.
Umgang mit Strukturabweichungen
Wenn sich Quell- und Zielstrukturen unterscheiden, können Sie diese mit einer der folgenden Methoden behandeln:
-
Mehrere Instanzen auf eine einzelne Instanz zuordnen: Wenn Sie Arrays auf einzelne Objekte zuordnen, sehen Sie diesen Dialog:
Zitat
Eine Quelle mit mehreren Instanzen kann nicht auf ein Ziel mit einer einzelnen Instanz zugeordnet werden. Möchten Sie die Zuordnung ändern, um die erste Instanz für jede Quelle zu verwenden?
Ein Klick auf Ja ordnet nur den ersten Datensatz zu, indem
#1zum Pfad hinzugefügt wird. -
Hierarchische in flache Strukturen umwandeln: Um einen Ausgabedatensatz pro Kind-Element zu erstellen, befolgen Sie diese Schritte:
- Ordnen Sie Felder vom tiefsten wiederholenden Knoten zu.
- Die Elterndaten wiederholen sich automatisch für jedes Kind.
- Die Iteratorzeile wechselt zur Kind-Ebene.
Datennormalisierung
Datennormalisierung ist der Prozess, flache Quelldatensätze in einen hierarchischen Baum umzuformen. Dies ist notwendig, wenn flache Daten (wie CSV- oder Datenbankzeilen) auf ein hierarchisches Ziel (wie XML oder JSON) abgebildet werden, um sicherzustellen, dass Eltern-Kind-Beziehungen korrekt erstellt werden, ohne dass Elternknoten dupliziert werden.
Standardmäßig verwendet Harmony einen Normalisierungsalgorithmus, um den Zielbaum zu konstruieren. Dieser Prozess wandelt die flache Struktur der Quelle in eine hierarchische Quellstruktur um, die dann auf das hierarchische Ziel abgebildet werden kann.
Die Normalisierung kann mithilfe einer Jitterbit-Variablen deaktiviert werden, abhängig von der Zielstruktur, auf die Sie abbilden:
- Flach-zu-flach:
jitterbit.transformation.disable_normalization - Flach-zu-XML:
jitterbit.transformation.flat_to_xml.disable_normalization
Das Verhalten der Transformationszuordnung ändert sich, je nachdem, ob die Normalisierung aktiviert ist:
-
Mit Normalisierung (Standard): Redundante Daten in flachen Zeilen werden zusammengefasst. Wenn Sie beispielsweise fünf Zeilen von
Order-Positionen für eineOrder IDhaben, wird einOrder-Elternteil mit fünf Kindpositionen erstellt. -
Ohne Normalisierung: Jeder flache Datensatz wird als einzigartiger Zweig behandelt. Im obigen Beispiel würde dies zu fünf separaten Bestellungen führen, von denen jede einen einzelnen Artikel enthält.
Einzelinstanzknoten
Wenn ein Zielknoten als Einzelinstanzknoten definiert ist, wird nur der erste gefundene Datensatz für diesen Knoten beibehalten. Alle nachfolgenden flachen Datensätze, die ansonsten auf diesen Knoten abgebildet werden würden, werden ignoriert.
Umgang mit komplexen XML-Schemas
Wenn Sie ein Schema verwenden, das abgeleitete Typen oder Substitutionsgruppen enthält, müssen Sie einige Eingaben bereitstellen, bevor Sie mit der Transformationszuordnung fortfahren können.
Wichtig
Spiegelte Schemata, die Substitutionsgruppen verwenden, werden nicht unterstützt und führen zu einem Betriebszeitfehler.
Schema angeben
Abgeleitete Typen oder Substitutionsgruppen sind in XML-basierten XSD- und WSDL-Schemata üblich. Sie können diese Arten von Schemata in einer Aktivität oder in einer Transformation hochladen, oder sie können von einigen Konnektoren direkt vom Endpunkt abgerufen werden. Beispielsweise enthalten Antwortschemata, die von einer gespeicherten Suche in einer NetSuite-Suchaktivität zurückgegeben werden, häufig abgeleitete Typen.
Für weitere Informationen siehe Schemaquellen auswählen.
Abgeleitete Typen oder Substitutionsgruppe auswählen
Nachdem Sie das Schema angegeben haben, wählen Sie die abgeleiteten Typen oder die Substitutionsgruppe innerhalb der Transformation aus. Es kann Knoten geben, für die Sie abgeleitete Typen entweder auf der Quell- oder der Zielseite der Transformation auswählen können.
Ein Link zu Abgeleiteter Typ(en) auswählen oder Substitutionsgruppe wird neben dem Knotennamen angezeigt, sofern zutreffend:
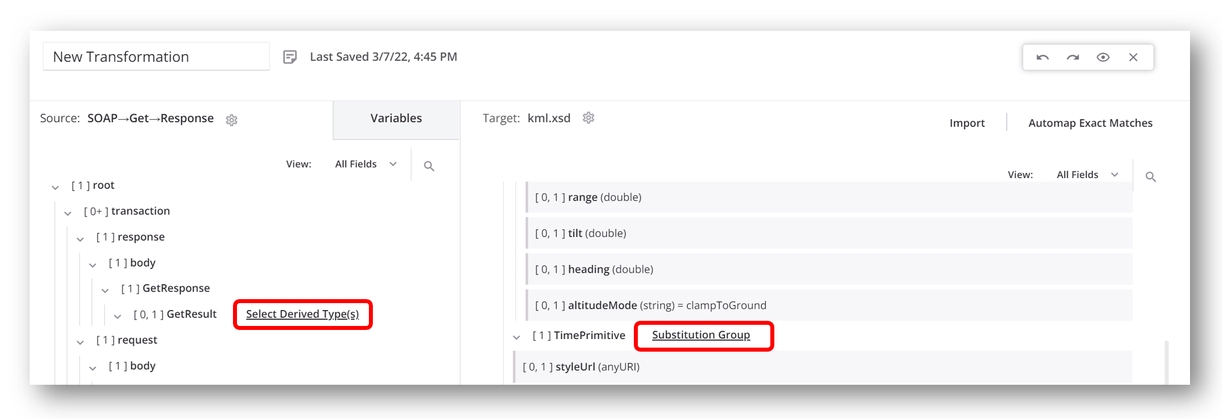
Die Benutzeroberfläche ist sowohl für die Auswahl abgeleiteter Typen als auch für die Auswahl einer Substitutionsgruppe gleich.
Klicken Sie auf den Link Abgeleiteter Typ(en) auswählen oder Substitutionsgruppe, um einen Dialog zu öffnen, in dem Sie aus den verfügbaren Knoten auswählen können:
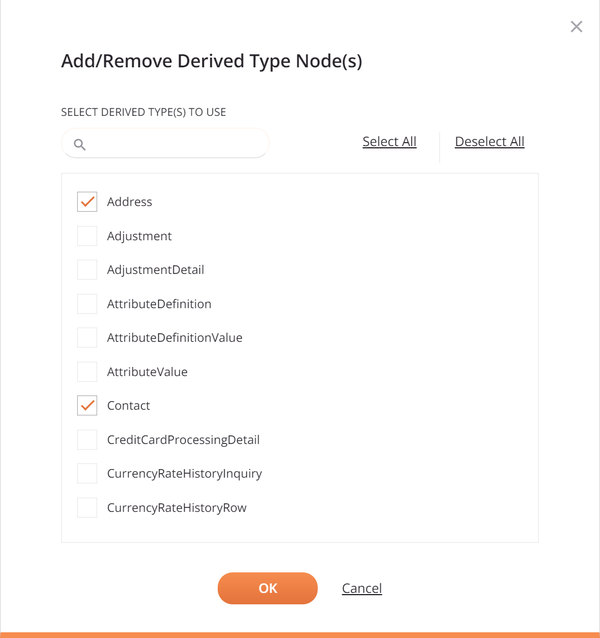
Um die Liste der Knoten zu filtern, geben Sie einen Teil des Knotennamens in das Suchfeld ein. Die Suche ist nicht groß-/kleinschreibungsempfindlich.
Wählen Sie die Knoten aus, die Sie mithilfe der Kontrollkästchen neben den Knotennamen möchten. Die Links Alle auswählen und Alle abwählen können verwendet werden, um alle Knoten auf einmal auszuwählen oder zu löschen. Klicken Sie dann auf OK, um die abgeleiteten Knoten innerhalb des Schemas zu verwenden.
Hinweis
Wenn Sie eine große Anzahl von abgeleiteten Knoten auf einmal (30 oder mehr) auswählen, kann das System beim Aktualisieren der Transformation langsam reagieren.
Die ausgewählten Knoten werden dann im Schema angezeigt. Sie können sie erweitern oder reduzieren, um zusätzliche untergeordnete Knoten und Felder innerhalb dieser anzuzeigen:

Nachdem Sie Knoten ausgewählt haben, können Sie Ihre Auswahl ändern, indem Sie den Link Abgeleitete(r) Typ(e) auswählen oder Substitutionsgruppe erneut anklicken, um zum Auswahlbildschirm zurückzukehren und Knoten nach Bedarf hinzuzufügen oder zu entfernen.
Sie können dann wie gewohnt mit der Transformationszuordnung fortfahren, indem Sie die Quellfelder innerhalb der ausgewählten Knoten den Ziel-Feldern zuordnen oder indem Sie den Ziel-Feldern innerhalb der ausgewählten Knoten zuordnen.