Steuern von Datenzyklen in Transformationen in Jitterbit Studio
Einführung
Schleifen-Knoten Iteratorlinien, die die Quell- und Zielknoten anzeigen, deren zugeordnete Felder eine Transformation durchlaufen wird, werden automatisch während des Mapping-Prozesses generiert, entweder beim Einsatz von Automapping oder beim manuellen Zuordnen von Quellobjekten zu Ziel-Feldern.
Normalerweise ist die automatische Generierung von Schleifen-Knoten während des Mappings für den Datensatz geeignet. Wenn die Daten jedoch so beschaffen sind, dass es mehrere Sätze sich wiederholender Datenwerte — oder mehrere Schleifen-Knoten — gibt, müssen Sie möglicherweise einen Schleifen-Knoten manuell definieren, um die Daten dazu zu bringen, auf einem anderen Knoten zu wiederholen. Wenn Sie Validierungsfehler feststellen, siehe Mapping-Konflikte lösen.
In bestimmten Situationen kann ein zugeordnetes Quellfeld eine Iteratorlinie darüber haben, die so konfiguriert ist, dass sie neue Datensätze auf einem höheren Niveau im Ziel aus einem niedrigeren Niveau in der Quelle generiert. Diese Mapping-Konfiguration ist gültig, führt jedoch möglicherweise nicht zu den gewünschten Daten im Ziel. In diesem Fall müssen Sie möglicherweise das Mapping manuell anpassen.
Sie können auch, falls erforderlich, Schleifen-Knoten entfernen, sowohl die automatisch generierten als auch die manuell definierten.
Verständnis von Schleifen-Knoten
Schleifen-Knoten steuern, wie Transformationen durch sich wiederholende Datenstrukturen wie Arrays und Listen iterieren. Sie verwenden visuelle Iteratorlinien, um den Datenfluss von der Quelle zum Ziel zu zeigen.
Schleifen-Knoten dienen drei Hauptzwecken:
-
Steuerung der Dateniteration: Sie bestimmen, welche Datenelemente sich wiederholen und wie oft.
-
Festlegung der Verarbeitungsreihenfolge: Sie legen die Reihenfolge für die Verarbeitung verschachtelter Datenstrukturen fest.
-
Zuordnung von Datenbeziehungen: Sie verbinden verwandte Daten zwischen Quell- und Zielstrukturen.
Sie können Schleifen-Knoten an ihren Iteratorlinien erkennen:
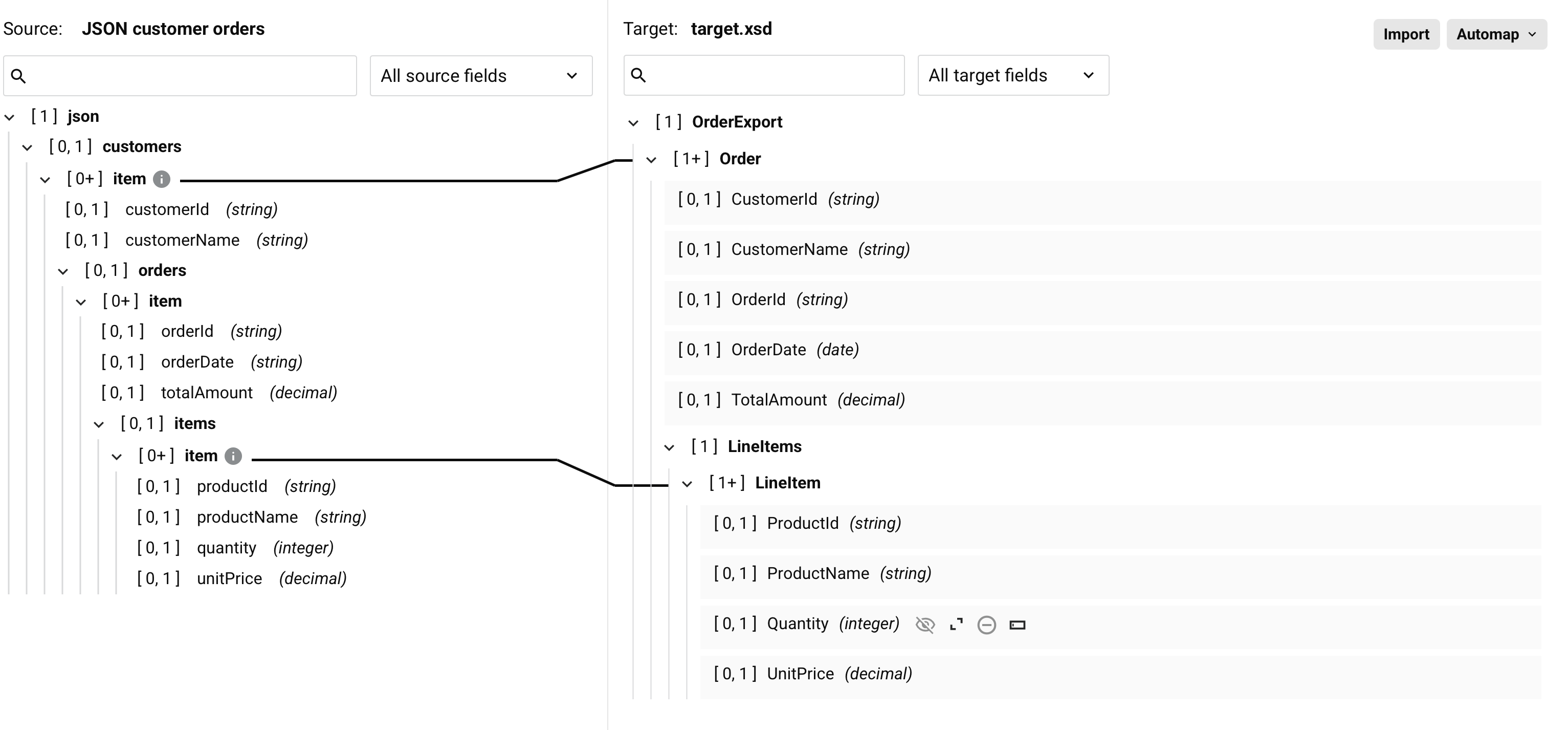
Feste schwarze Linien verbinden Quellknoten mit Zielknoten. Diese Linien zeigen genau, wo Daten in einer Schleife verarbeitet werden.
Hinweis
Mehrere Iteratorlinien werden hierarchisch von oben nach unten in der Zielstruktur verarbeitet.
Wenn eine Transformation ausgeführt wird, steuern Schleifen-Knoten den Datenfluss:
-
Die Transformation beginnt mit der obersten (äußeren) Schleife.
-
Jedes Quellobjekt erzeugt einen oder mehrere Zieldatensätze.
-
Alle zugeordneten Felder innerhalb der Schleife werden für jede Iteration verarbeitet.
-
Innere Schleifen werden vollständig abgeschlossen, bevor die obere/äußere Schleife fortgesetzt wird.
-
Die Verarbeitung wird fortgesetzt, bis alle Quelldaten verbraucht sind.
Wann Schleifen-Knoten automatisch erstellt werden
Schleifen-Knoten erscheinen automatisch, wenn Sie:
- Felder zwischen sich wiederholenden Strukturen (Arrays mit
[0+]oder[1+]Kardinalität) zuordnen - Automapping zwischen kompatiblen Quell- und Ziel-Arrays verwenden
- Die erste Feldzuordnung zwischen sich wiederholenden Strukturen erstellen
Für die automatische Erstellung von Schleifen-Knoten müssen diese Anforderungen erfüllt sein:
- Sowohl Quell- als auch Zielknoten müssen Wiederholungen unterstützen (
[0+]oder[1+]Kardinalität) - Sie müssen mindestens ein Feld zwischen den sich wiederholenden Strukturen zuordnen
Schleifen-Knoten definieren
Beim Einsatz von Automapping werden Schleifen-Knoten automatisch generiert.
Schleifen-Knoten können auch manuell auf Zielknoten definiert werden, die beide dieser Bedingungen erfüllen:
- Die Kardinalität des Zielknotens muss
0+oder1+sein. - Es dürfen keine Zuordnungen auf direkten Blattfeldern innerhalb des Zielknotens vorhanden sein.
Darüber hinaus muss die Kardinalität des Quellknotens, der verwendet wird, um den Ziel-Schleifen-Knoten zu erstellen, 0+ oder 1+ sein.
Um einen Schleifen-Knoten manuell zu definieren, ziehen Sie einen qualifizierten Quellknoten zu einem qualifizierten Zielknoten:
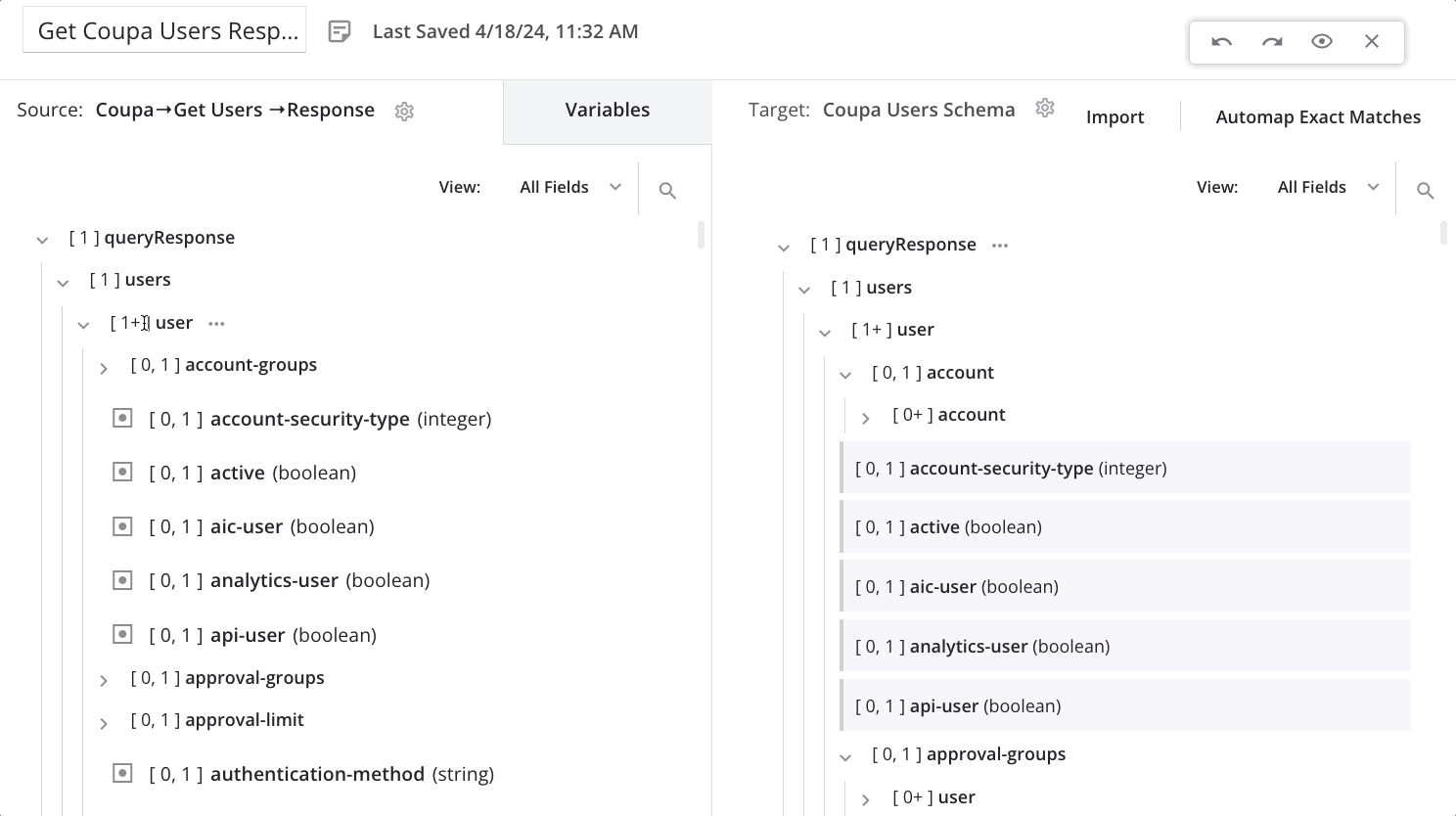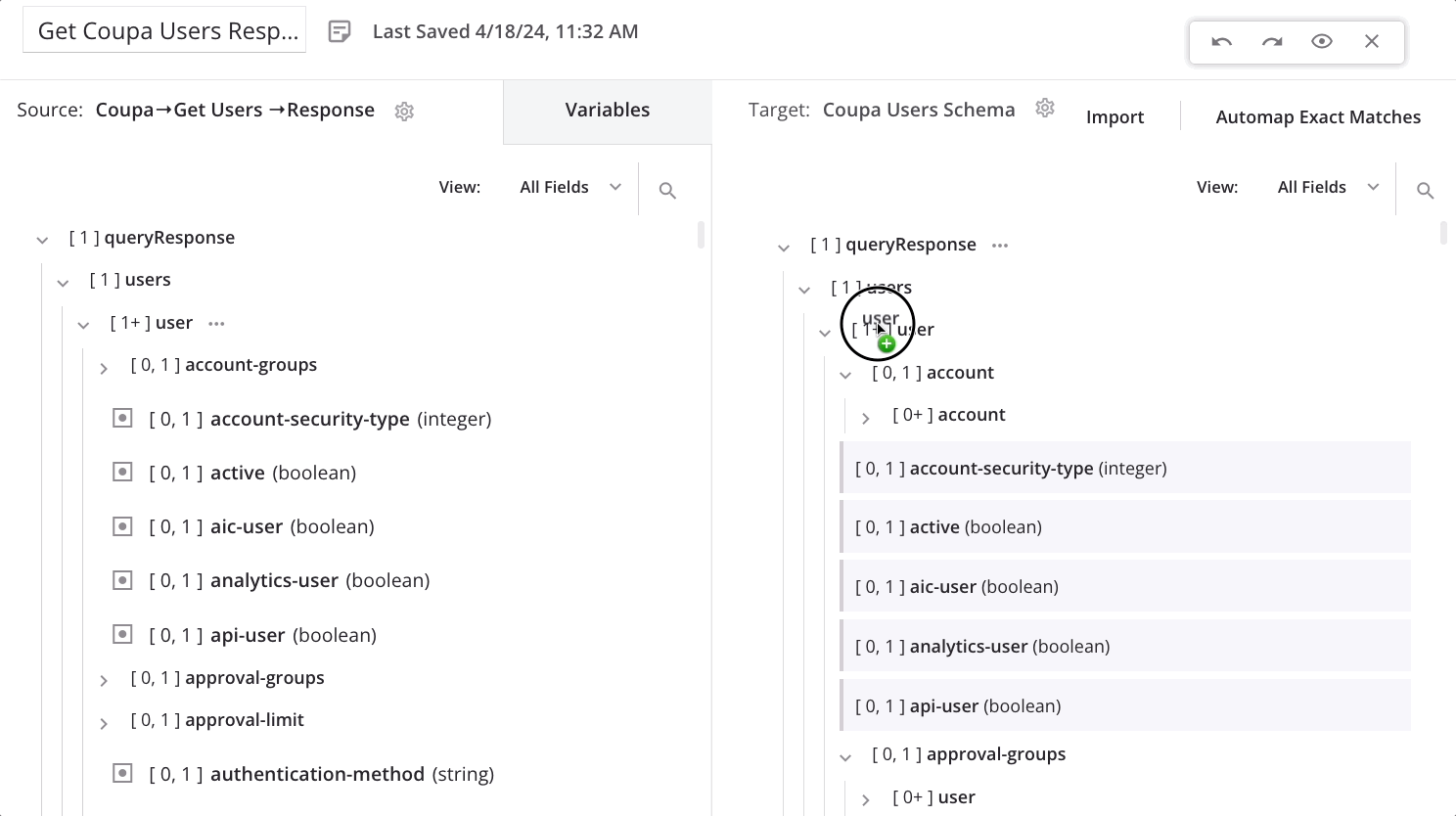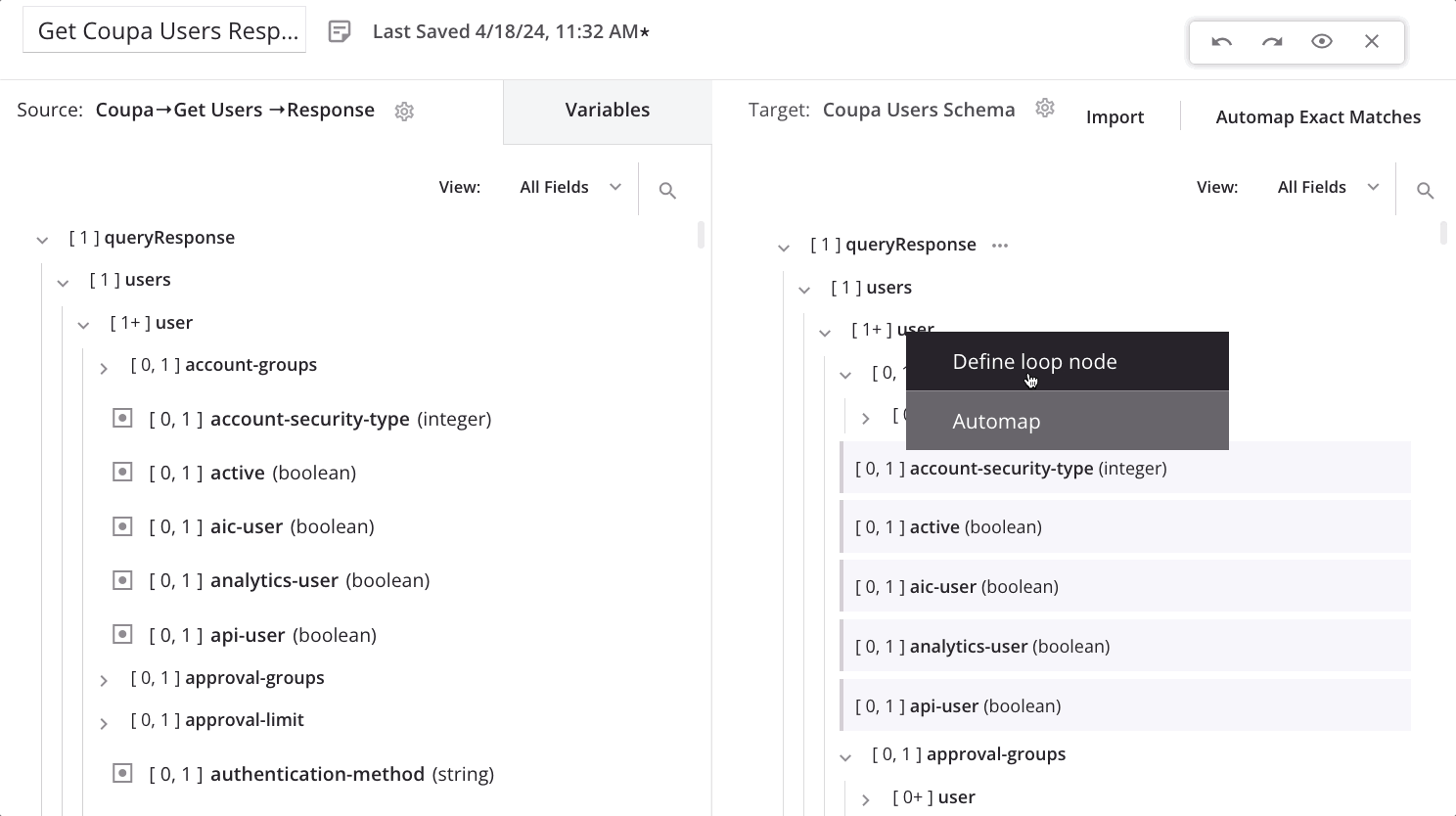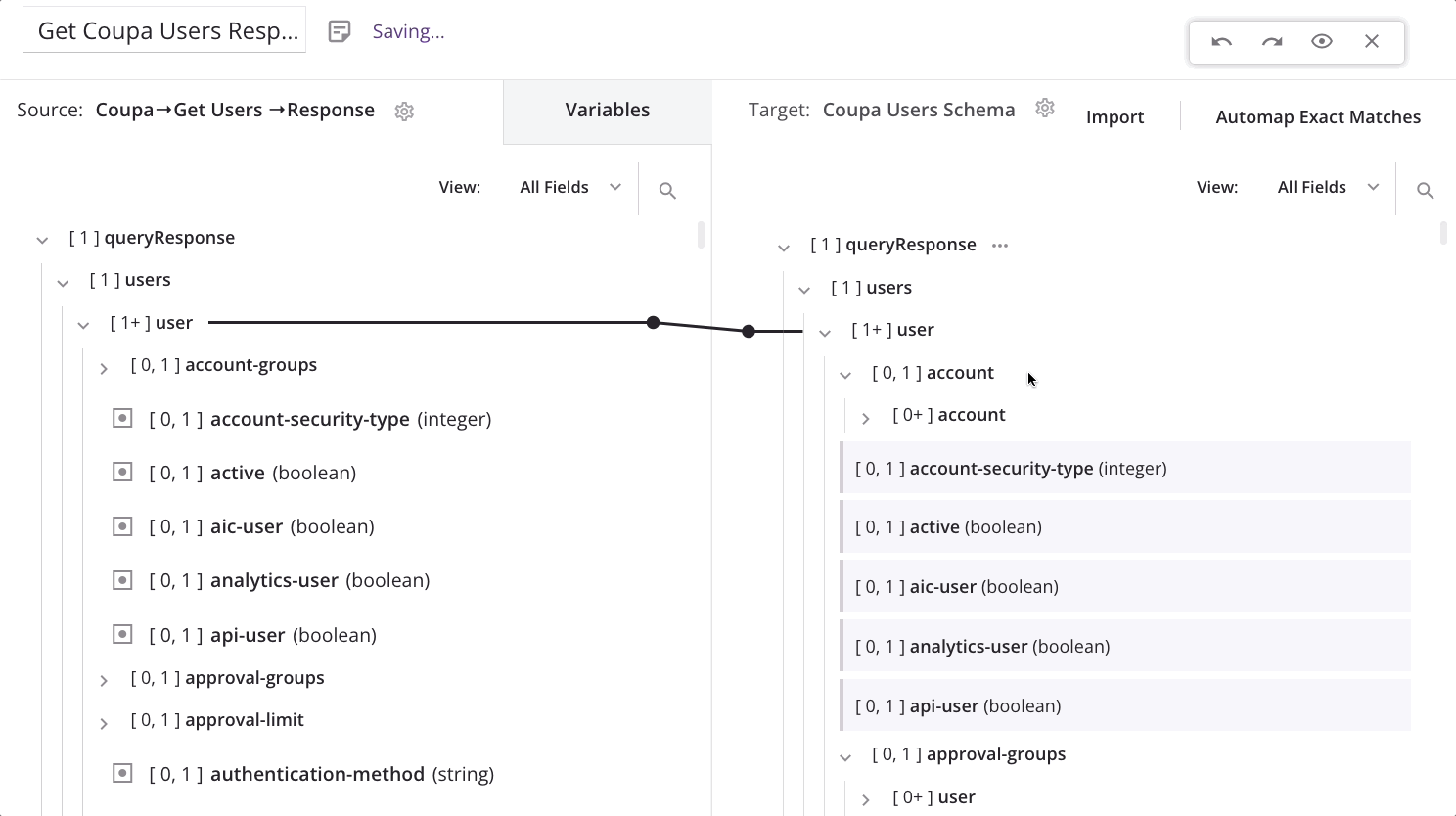
Beim Ablegen des Quellknotens auf den Zielknoten erscheint ein Menü. Wählen Sie die Option Schleifenknoten definieren.
Der Schleifenknoten ist jetzt definiert, und die Iteratorlinie wird angezeigt, die angibt, wie die Transformation durch den Quell-Datensatz schleifen wird. Die Linie wird angezeigt, auch wenn es noch keine direkten Blattzuordnungen für Felder unter dem Knoten gibt. Vervollständigen Sie die Zuordnung der Felder unter dem Schleifenknoten wie gewohnt:
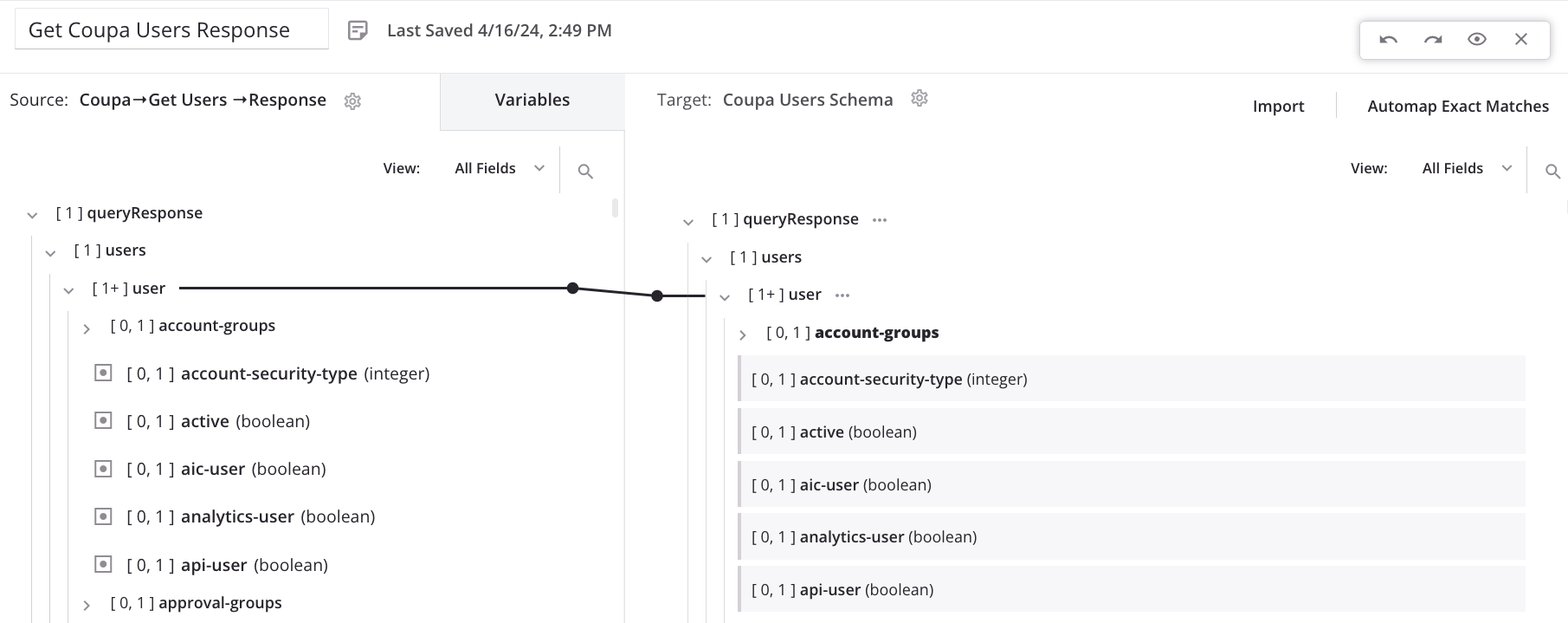
Zusammengeklappte Knoten, die Schleifenknoten-Zuordnungen enthalten, werden mit einer gestrichelten Iteratorlinie angezeigt. Klicken Sie auf den Pfeil , um untergeordnete Knoten zu erweitern, bis Sie den Schleifenknoten finden:

Manuell automatisch generierte Schleifenknoten anpassen
Nachdem Schleifenknoten automatisch generiert wurden, müssen Sie diese möglicherweise manuell anpassen. Im folgenden Beispiel bietet eine Anfrage-Transformation Filter, die in einer HubSpot-Suchaktivität verwendet werden, um Unternehmensdatensätze abzufragen. Unten zeigen wir zunächst die Ausgabe, wenn der automatisch generierte Schleifenknoten verwendet wird, und dann, wie sich die Ausgabe ändert, wenn der Schleifenknoten manuell neu definiert wird.
Automatische Schleifenknotengenerierung
Nach der Automapping und der automatischen Generierung eines Schleifenknotens zeigt die Transformationszuordnung, dass Daten auf dem zweiten item-Knoten des Ziels schleifen:
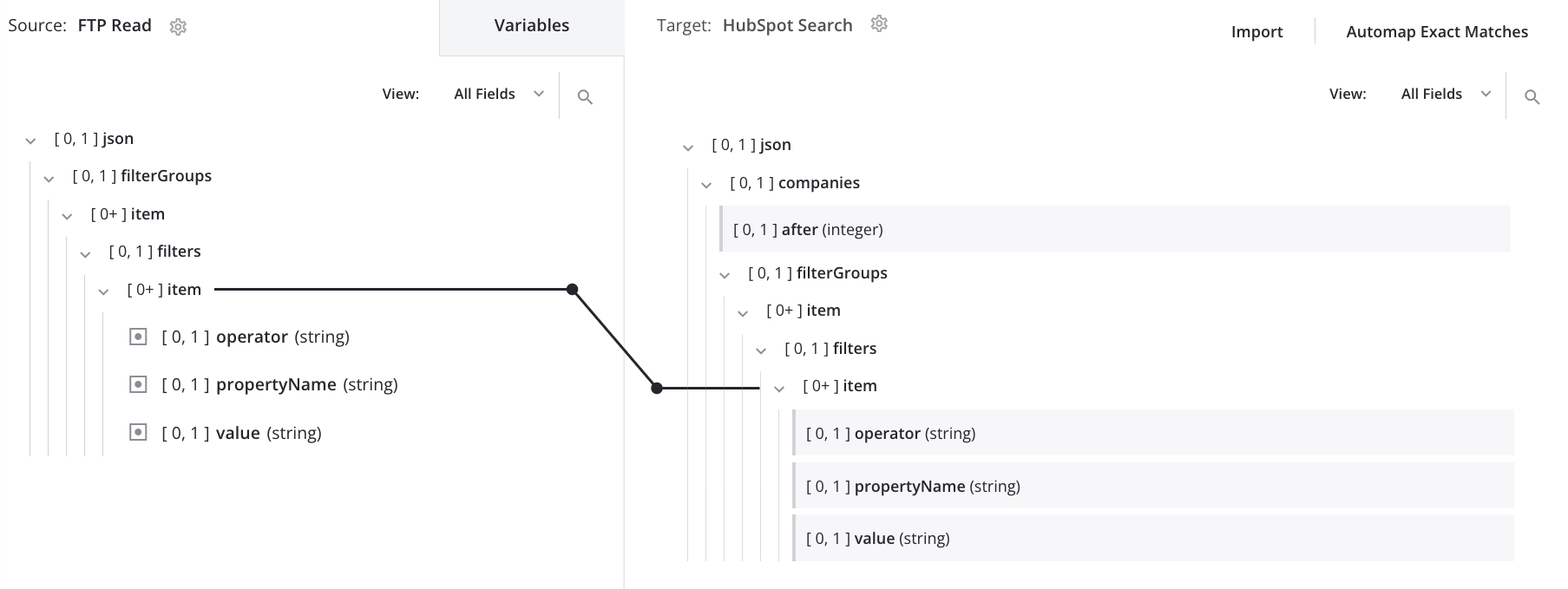
Wenn die obige Zuordnung mit den untenstehenden Eingabedaten verarbeitet wird, ergibt sich diese Ausgabe, die die Eingabestruktur in eine einzige Liste von Filtern abflacht:
{
"filterGroups": [
{
"filters": [
{
"operator": "EQ",
"propertyName": "name",
"value": "AZ INC"
}
]
},
{
"filters": [
{
"operator": "EQ",
"propertyName": "name",
"value": "IQ services"
},
{
"operator": "EQ",
"propertyName": "hs_object_id",
"value": "4403735338"
}
]
}
]
}
{
"filterGroups": [
{
"filters": [
{
"operator": "EQ",
"propertyName": "name",
"value": "AZ INC"
},
{
"operator": "EQ",
"propertyName": "name",
"value": "IQ services"
},
{
"operator": "EQ",
"propertyName": "hs_object_id",
"value": "4403735338"
}
]
}
]
}
Manuelle Definition des Schleifen-Knotens
Um den Knoten zu ändern, über den die Daten schleifen, ziehen Sie den zweiten item-Knoten der Quelle auf den ersten item-Knoten des Ziels und wählen Sie Schleifenknoten definieren:
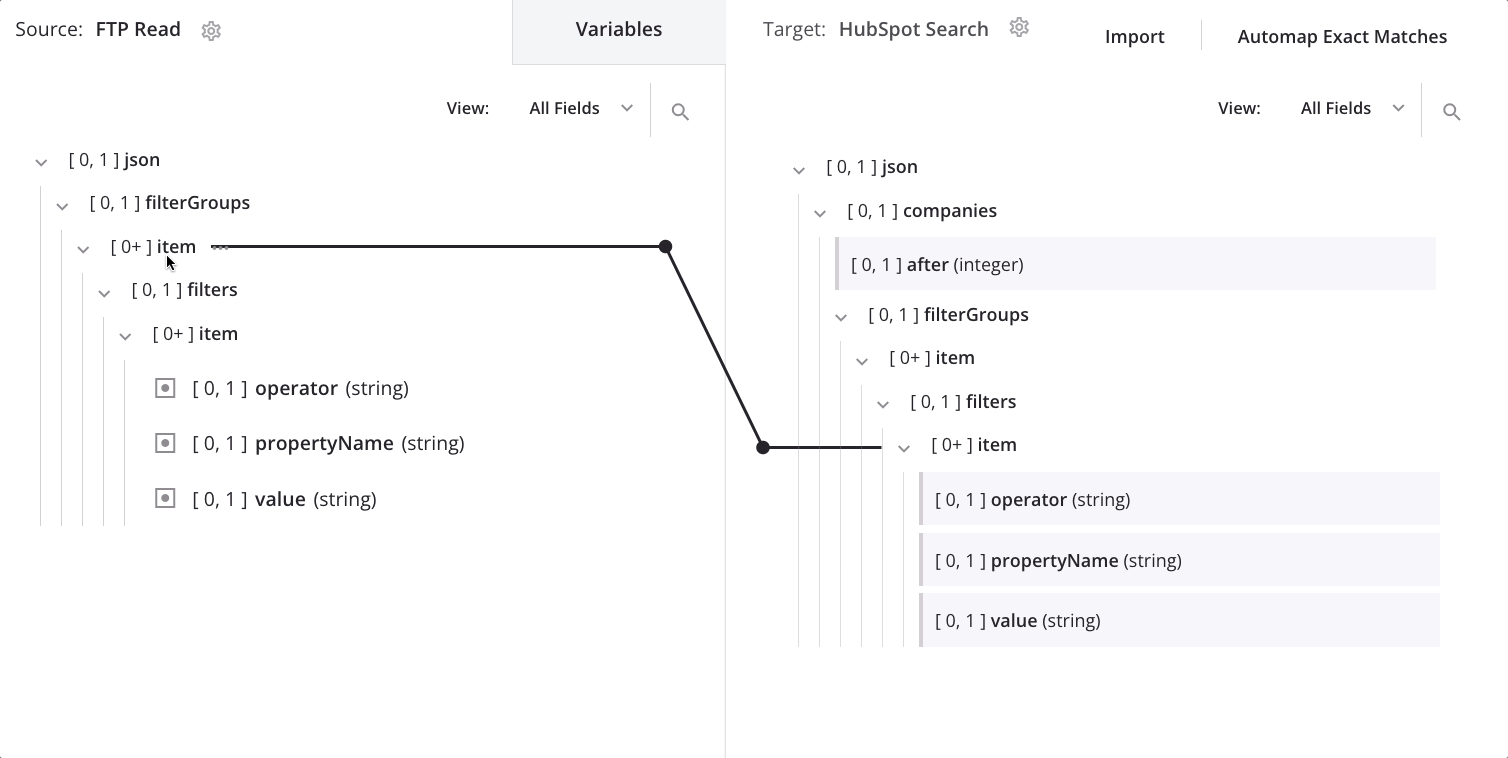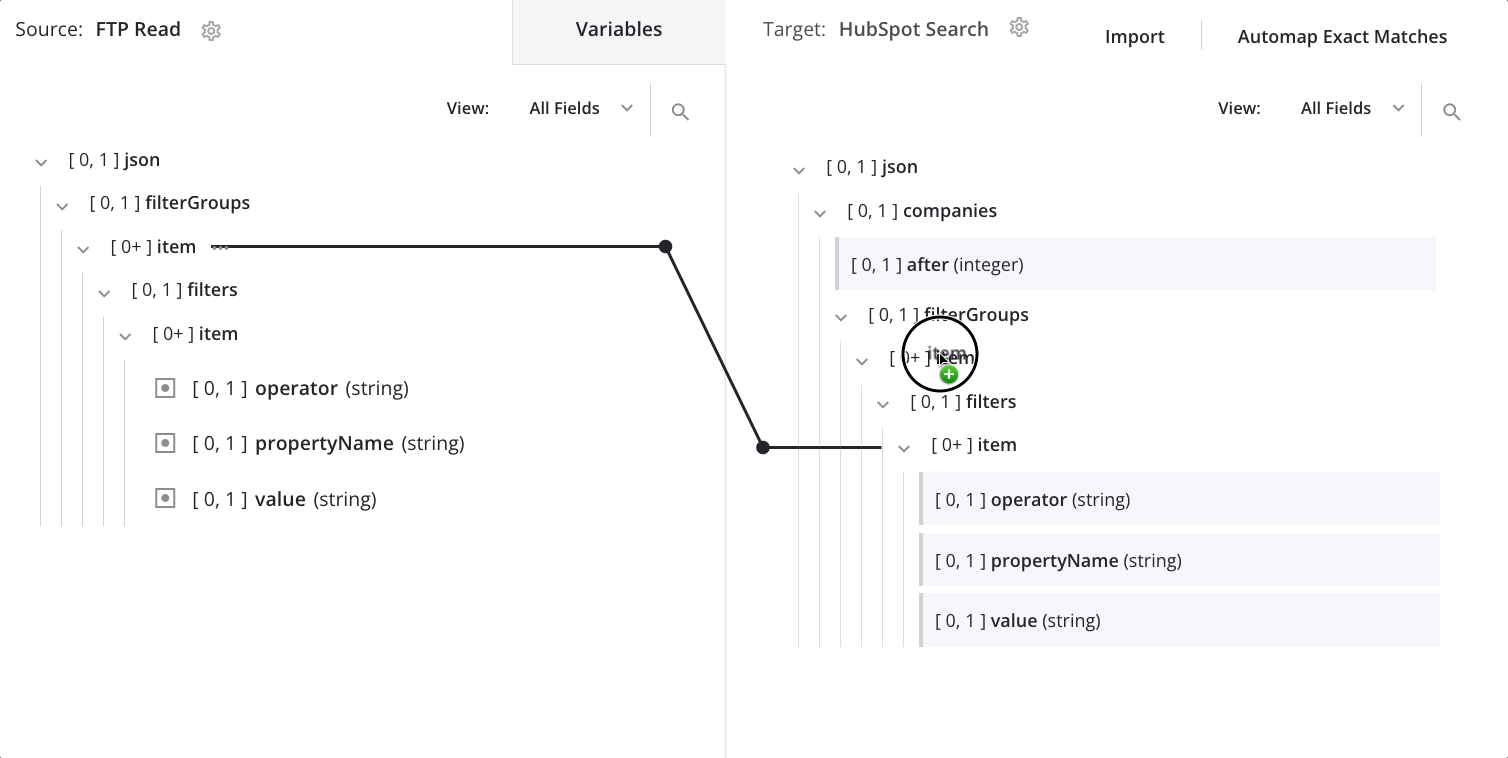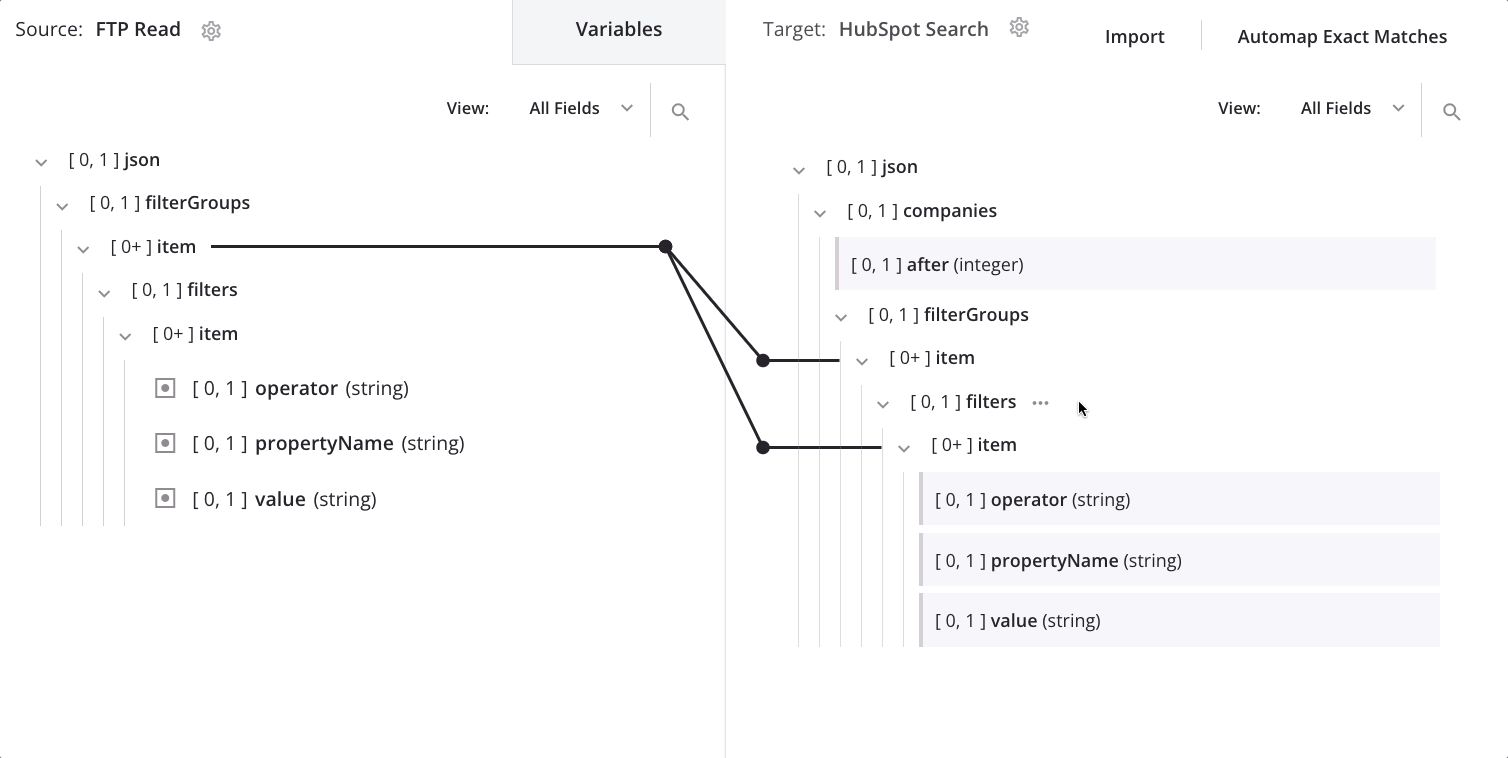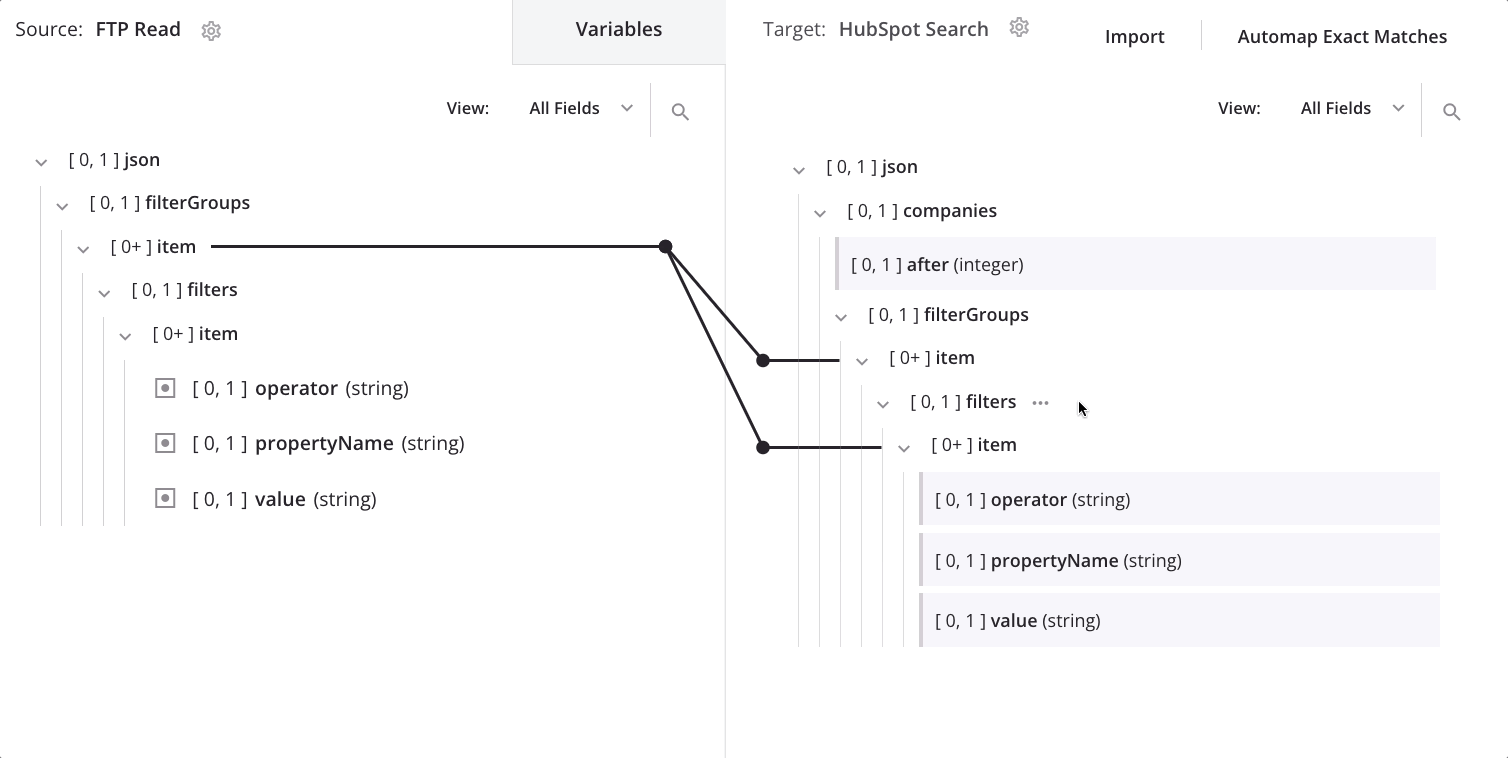
Jetzt sehen wir die Schleifenknoten-Iteratorlinie auf dem ersten und zweiten item-Knoten des Ziels:
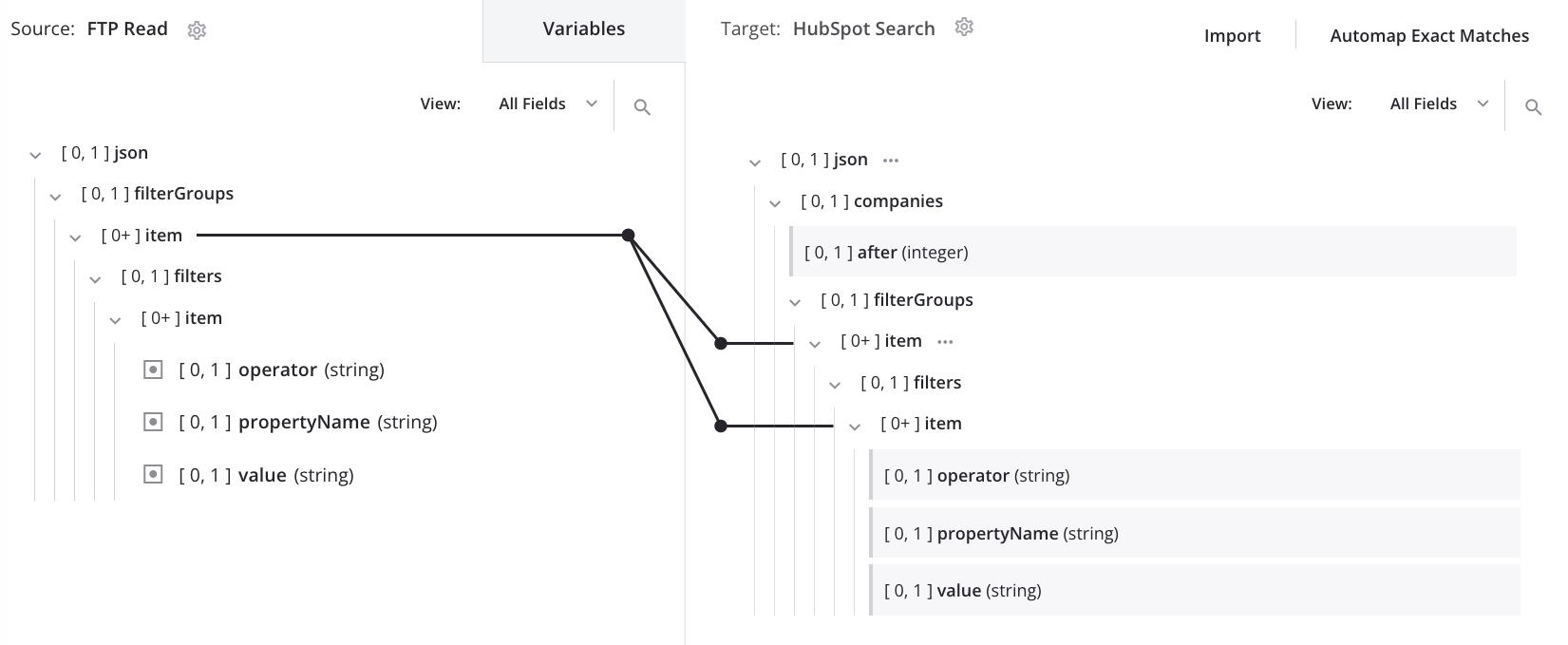
Wenn die obige Zuordnung mit denselben Eingabedaten verarbeitet wird, die auch bei der automatischen Schleifenknotengenerierung verwendet wurden, ergibt sich die gewünschte Ausgabe, die die Eingabestruktur beibehält:
{
"filterGroups": [
{
"filters": [
{
"operator": "EQ",
"propertyName": "name",
"value": "AZ INC"
}
]
},
{
"filters": [
{
"operator": "EQ",
"propertyName": "name",
"value": "IQ services"
},
{
"operator": "EQ",
"propertyName": "hs_object_id",
"value": "4403735338"
}
]
}
]
}
{
"filterGroups": [
{
"filters": [
{
"operator": "EQ",
"propertyName": "name",
"value": "AZ INC"
}
]
},
{
"filters": [
{
"operator": "EQ",
"propertyName": "name",
"value": "IQ services"
},
{
"operator": "EQ",
"propertyName": "hs_object_id",
"value": "4403735338"
}
]
}
]
}
Manuelle Anpassung einer Zuordnung bei nicht übereinstimmenden Quell- und Zielschleifenknoten
Ein zugeordnetes Quellfeld kann eine Iteratorlinie darüber haben, die so konfiguriert ist, dass sie neue Datensätze auf einer Ebene im Ziel aus einer niedrigeren Ebene in der Quelle generiert (auch mit einem Informationssymbol neben dem Quellknoten angezeigt). Diese Zuordnungskonfiguration ist gültig, führt jedoch möglicherweise nicht zu den gewünschten Daten im Ziel.
Sie möchten die Zuordnung möglicherweise manuell anpassen, wenn eines dieser Kriterien für Ihren Anwendungsfall zutrifft:
- Sie möchten keine doppelten Werte in separaten Datensätzen in der Zieldatei erstellen.
- Sie möchten keine Werte aus den Datensätzen in der Zieldatei weglassen (aufgrund eines fehlenden untergeordneten Datensatzes).
- Sie haben Quelldaten, bei denen der gewünschte untergeordnete Datensatz an einem konstanten Index ist oder durch einen Suchwert im Array der untergeordneten Datensätze gefunden werden kann.
- Sie benötigen keine Werte aus anderen untergeordneten Datensätzen im Array der untergeordneten Datensätze.
Die folgenden Unterabschnitte erläutern einen Anwendungsfall, bei dem Anpassungen der Zuordnung erforderlich sind, um Werte aus den Quelldatensätzen in der Zieldatei beizubehalten. Diese Animation bietet einen Überblick über die im Folgenden detaillierten Schritte:
In diesem Szenario haben die Quell- und Ziel-Schemas folgende Merkmale:
| Quelle | Ziel |
|---|---|
|
|

Automatische Generierung von Schleifen-Knoten
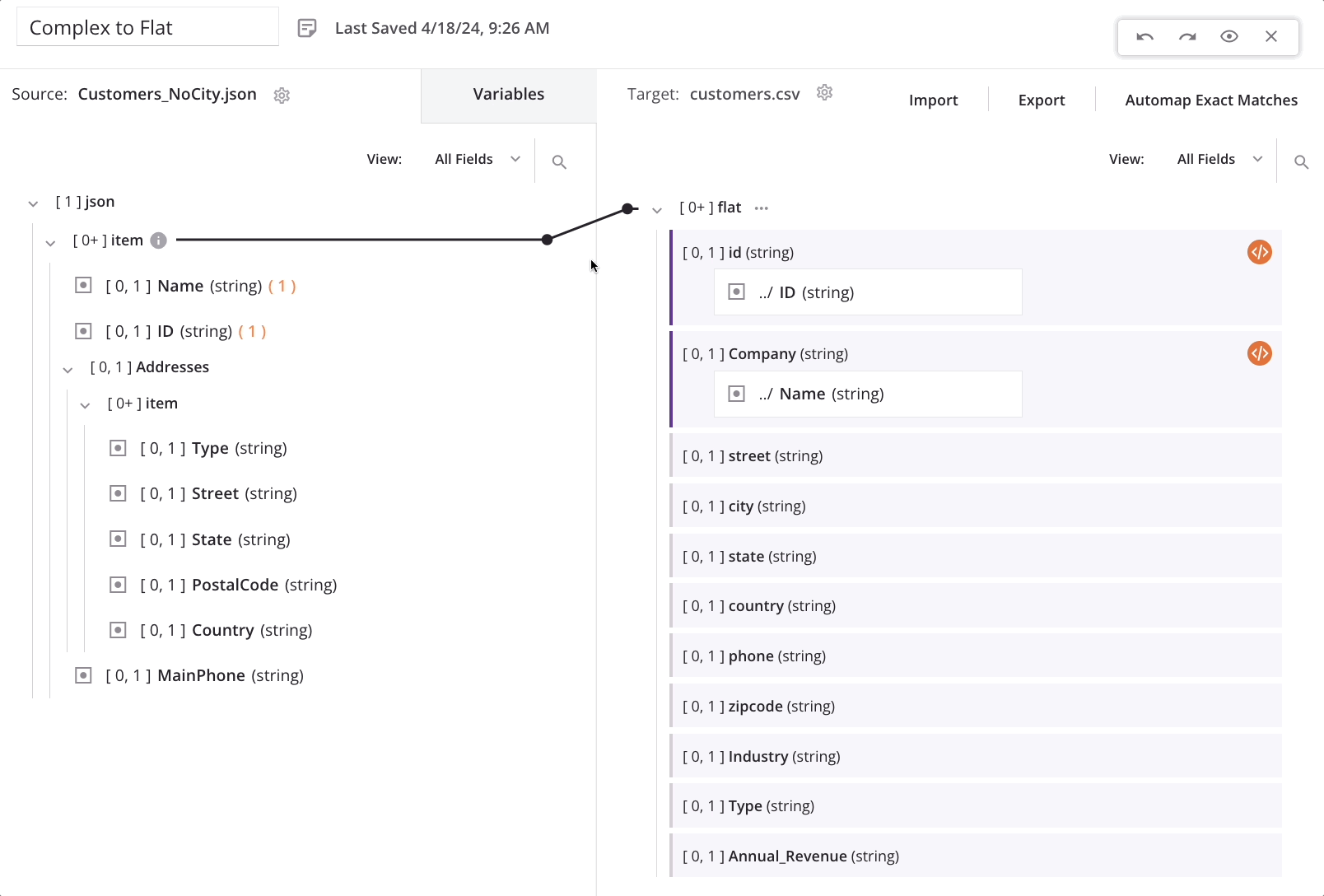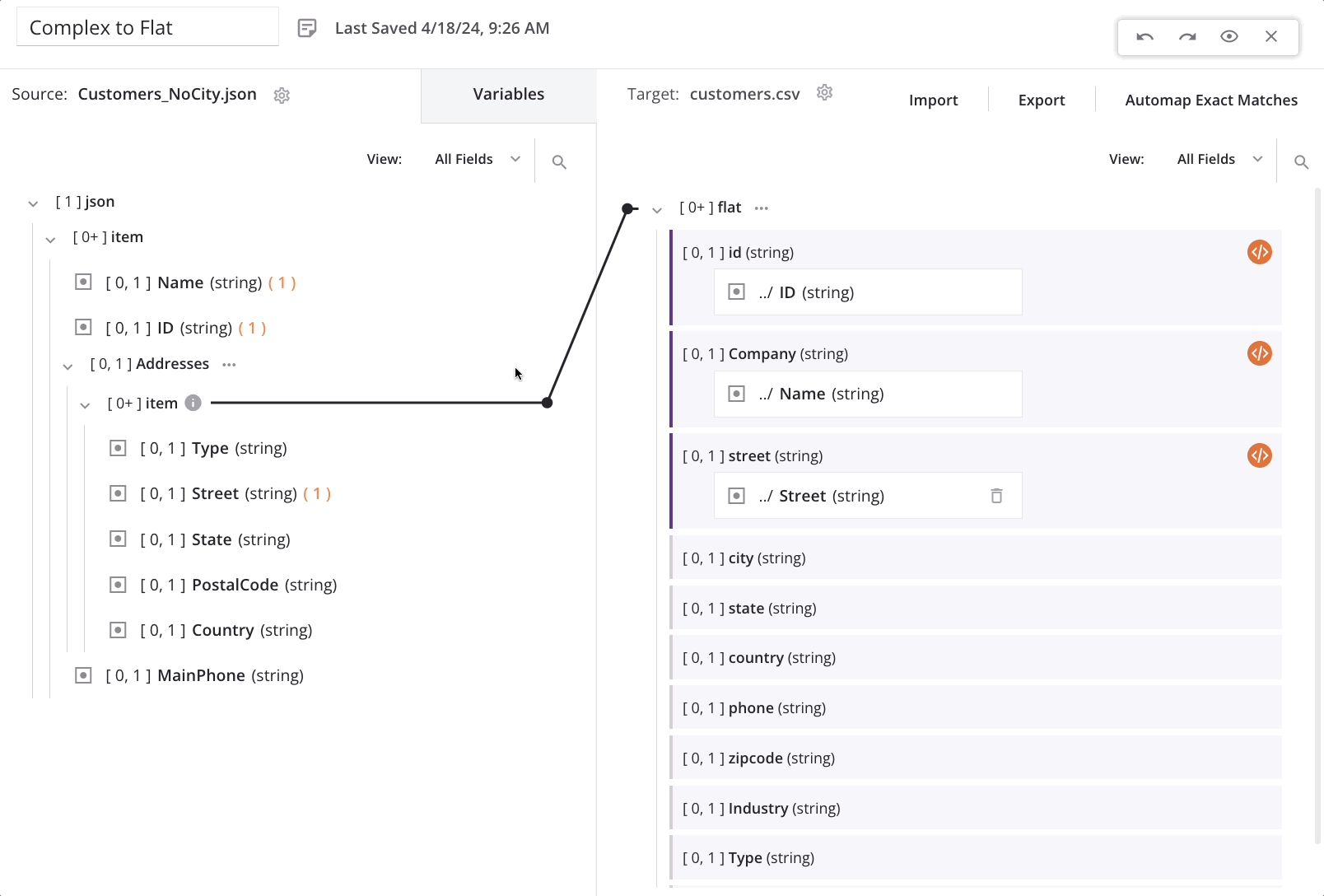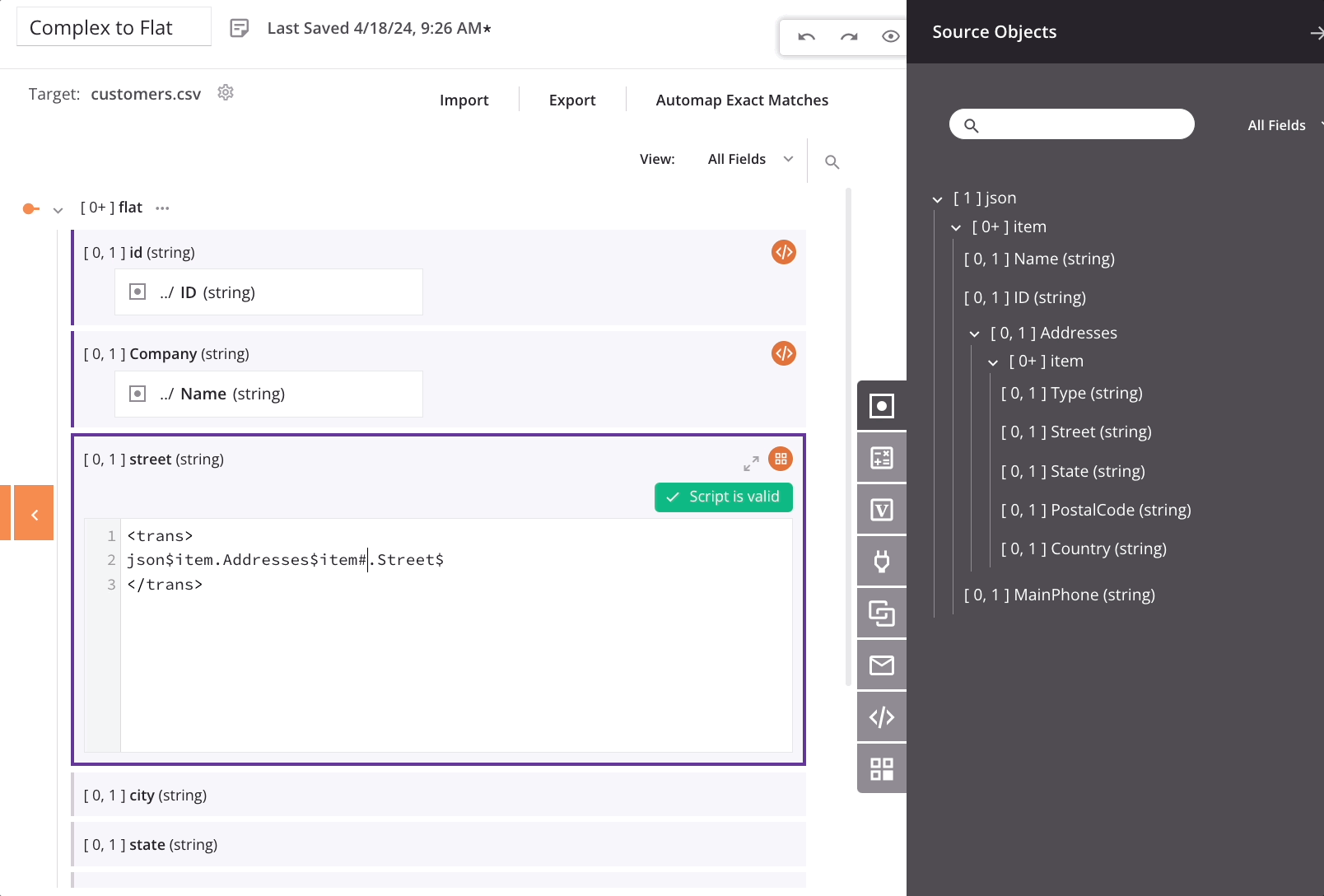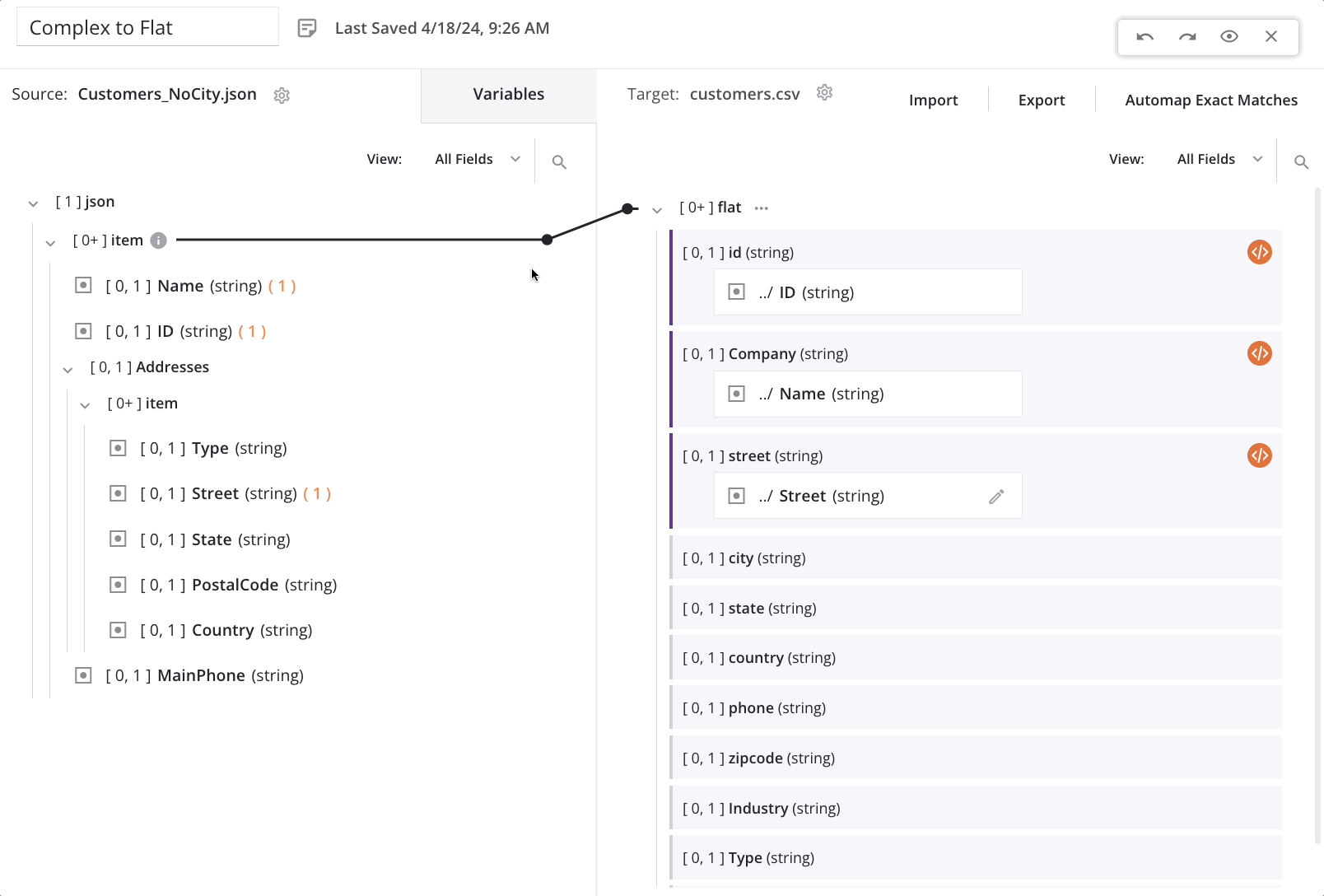
Wenn wir beginnen, Felder (wie Name) vom obersten Quellknoten zum obersten Zielknoten zuzuordnen, wird automatisch eine Schleifen-Knoten-Iteratorlinie vom obersten Quell-Kunden-/Artikel-Array-Knoten zum Ziel-Kunden-/Flach-Array-Knoten generiert. Dies zeigt an, dass für jeden neuen Kunden-Datensatz in der Quelle ein neuer Kunden-Datensatz im Ziel generiert wird:
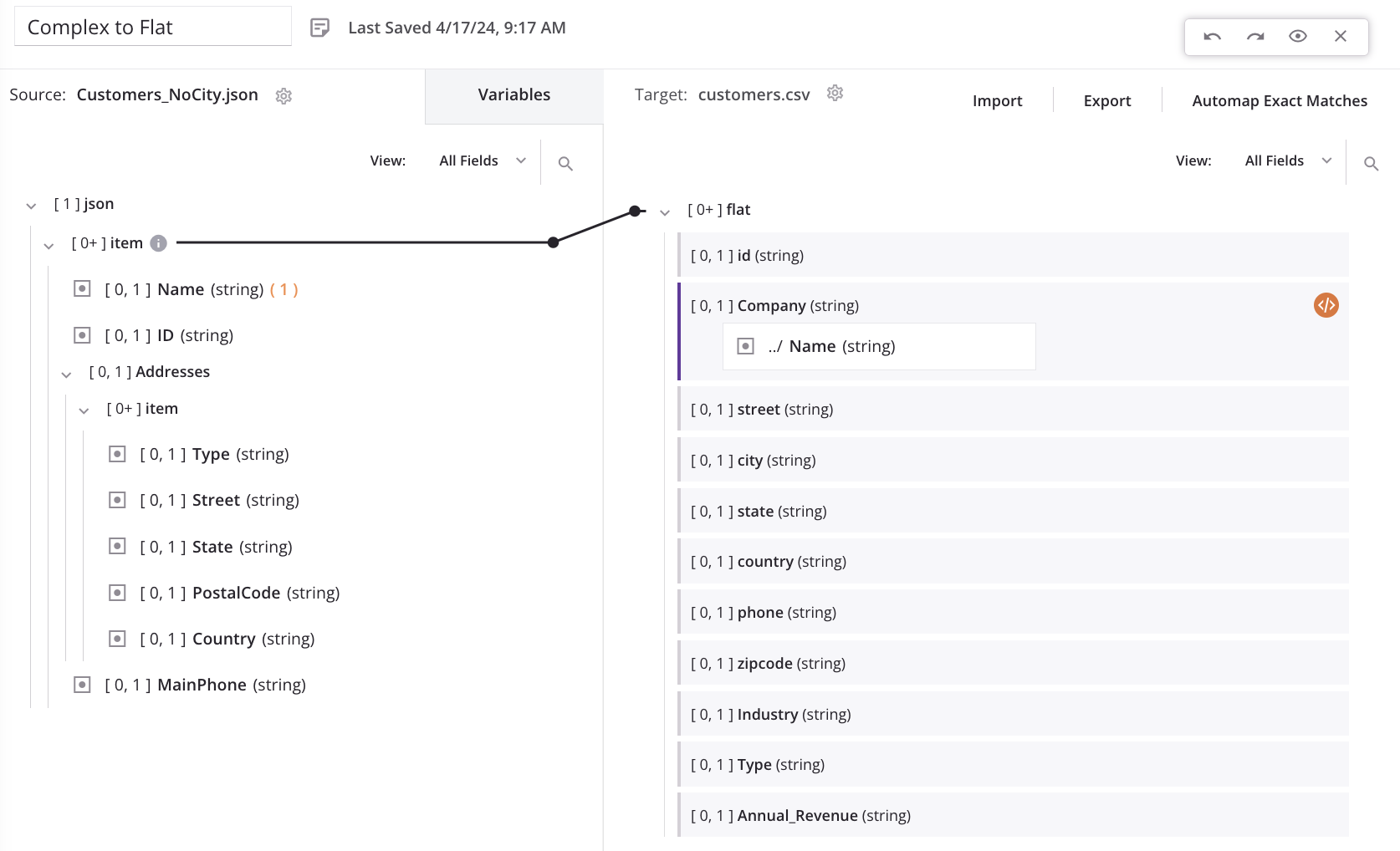
Wenn wir das erste Feld im sich wiederholenden Quelladresse-Knoten (Street) dem entsprechenden Zieladresse-Feld (street) zuordnen, wird eine Nachricht angezeigt, die darauf hinweist, dass neue Ziel-Datensätze aus einer niedrigeren Ebene in der Quelle generiert werden:
Dialogtext
Iterator wird neu konfiguriert
Das Erstellen dieser Zuordnung konfiguriert die obenstehende Iteratorlinie, um neue Ziel-Datensätze aus einer niedrigeren Ebene in der Quelle zu generieren. Um mehr über die Generierung von Schleifen-Knoten zu erfahren, besuchen Sie bitte link.
Ein Klick auf Bestätigen führt dazu, dass das Quende der Schleifen-Iteratorlinie automatisch vom obersten Kunden-/Artikel-Array-Knoten zu dem geschachtelten Adressen-/Artikel-Array-Knoten (auch angezeigt mit einem Informationssymbol neben dem Quellknoten) verschoben wird.
Für dieses Beispiel-Szenario bedeutet dies, dass für jeden neuen Adressdatensatz in der Quelle ein neuer Kunden-Datensatz im Ziel generiert wird:
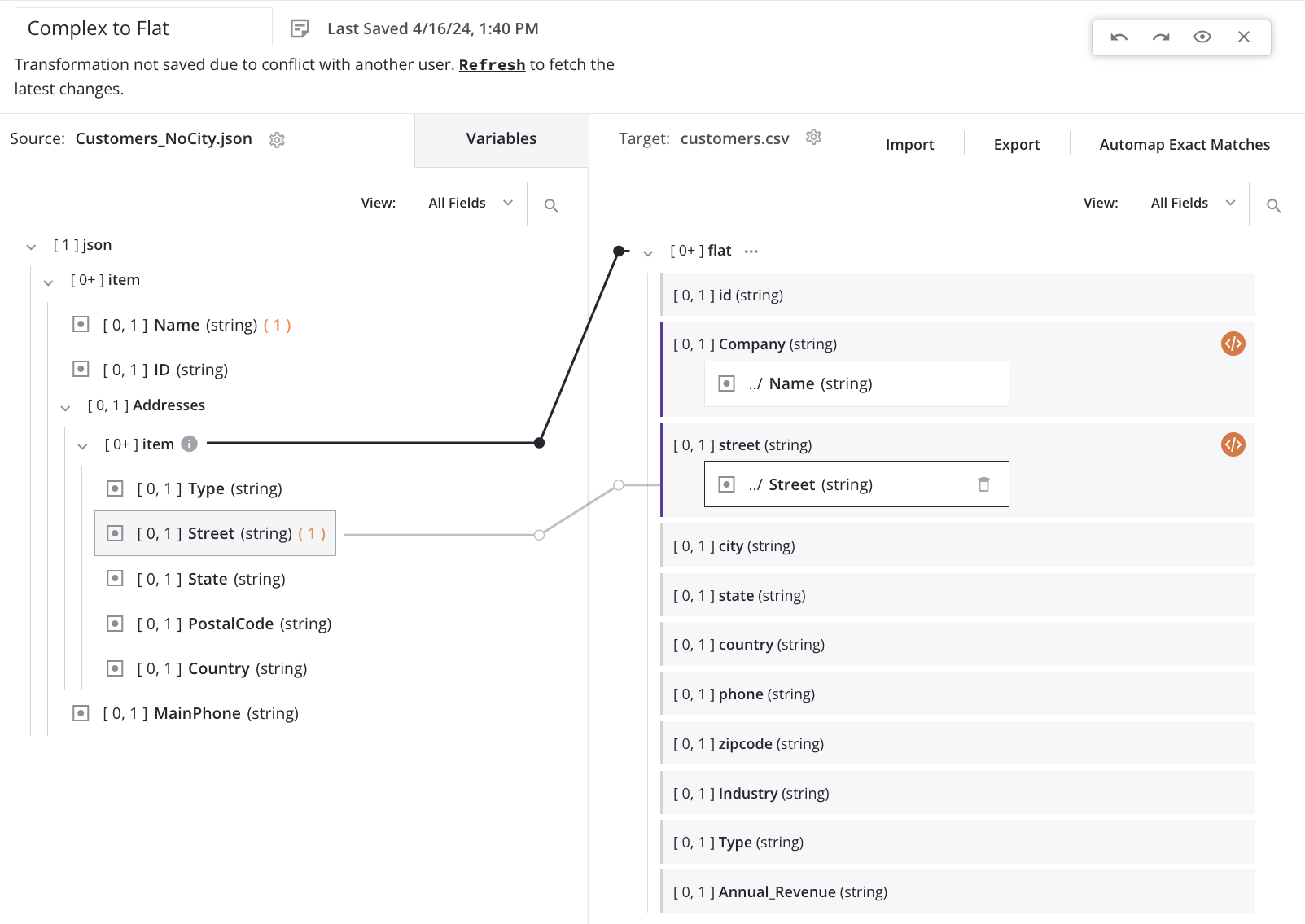
Dies führt dazu, dass ein einzelner Quell-Kunden-Datensatz im Ziel-Datei einmal für jede Adresse im Quelladresse-Array für diesen Kunden erscheint. Jeder Kunden-Datensatz hat die gleichen Werte für die obersten Felder mit einzigartigen Werten in den Adressfeldern. Zum Beispiel, wenn der erste Quell-Kunden-Datensatz zwei Adressen enthält, dann wird das Ziel zwei Kunden-Datensätze enthalten: einen mit der ersten Adresse und einen mit der zweiten Adresse.
Wichtig
Mit der automatischen Generierung von Schleifen-Knoten in diesem Szenario wird ein Quellkunden-Datensatz ohne Adressen keinen Zielkunden-Datensatz generieren.
Map von einer Mehrfachinstanz-Quelle zu einer Einzelinstanz-Ziel
Wenn der generierte Ziel-Schleifen-Knoten von mehr als einem Quell-Schleifen-Knoten abhängt, müssen Sie möglicherweise eine Vorkommen-Mismatch mit der Zuordnung beheben.
Wenn die Quell-Datenstruktur ein Multi-Objekt-Array ist und auf eine Ziel-Datenstruktur mit einem einzelnen Objekt abgebildet wird, wird dieser Dialog angezeigt:
Dialogtext
Vorkommen-Mismatch
Eine Mehrfachinstanz-Quelle kann nicht auf ein Einzelinstanz-Ziel abgebildet werden. Möchten Sie die Zuordnung ändern, um die erste Instanz für jede Quelle zu verwenden?
Um die erste Instanz der Quelle in der Zuordnung zu verwenden, wählen Sie Ja, um automatisch ein Hash-Symbol (#) im Referenzpfad des Datenelements einzufügen. Das bedeutet, dass nur der erste Datensatz abgebildet wird. Für ein vollständiges Beispiel siehe Datenstrukturen.
Wenn Sie nicht möchten, dass die erste Instanz der Quelle verwendet wird, können Sie Instanzen manuell angeben (siehe unten) oder andere Logik mit instanzauflösenden Funktionen verwenden (siehe Instanzfunktionen).
Manuelle Zuordnungsanpassung
Anhand des Beispielszenarios möchten wir keine Kunden-Datensätze aufgrund einer fehlenden Adresse verlieren, daher müssen wir jede Feldzuordnung des Kind-Arrays manuell anpassen. Wenn jede Zuordnung angepasst wird, verschiebt sich die generierte Schleifen-Knoten-Iteratorzeile automatisch an die richtige Stelle für die gewünschte Zielausgabe (basierend auf der Zuordnungsanpassung).
Um die Zuordnung für jedes Ziel-Feld im Kind-Array (wie street) anzupassen, fügen wir ein Hash-Symbol gefolgt von einer Ganzzahl zum addresses/item-Array im Zuordnungsskript hinzu. Das Hinzufügen der Referenz #1 gibt das erste Element eines Arrays zurück, was zur Erstellung eines einzelnen Kunden-Datensatzes im Ziel für jeden Kunden-Datensatz in der Quelle führt. Mit dieser Konfiguration enthält jeder im Ziel erstellte Kunden-Datensatz nur die erste Adresse aus dem Adressen-Array des Quellkunden-Datensatzes — die verbleibenden Adressen werden nicht ins Ziel verschoben.
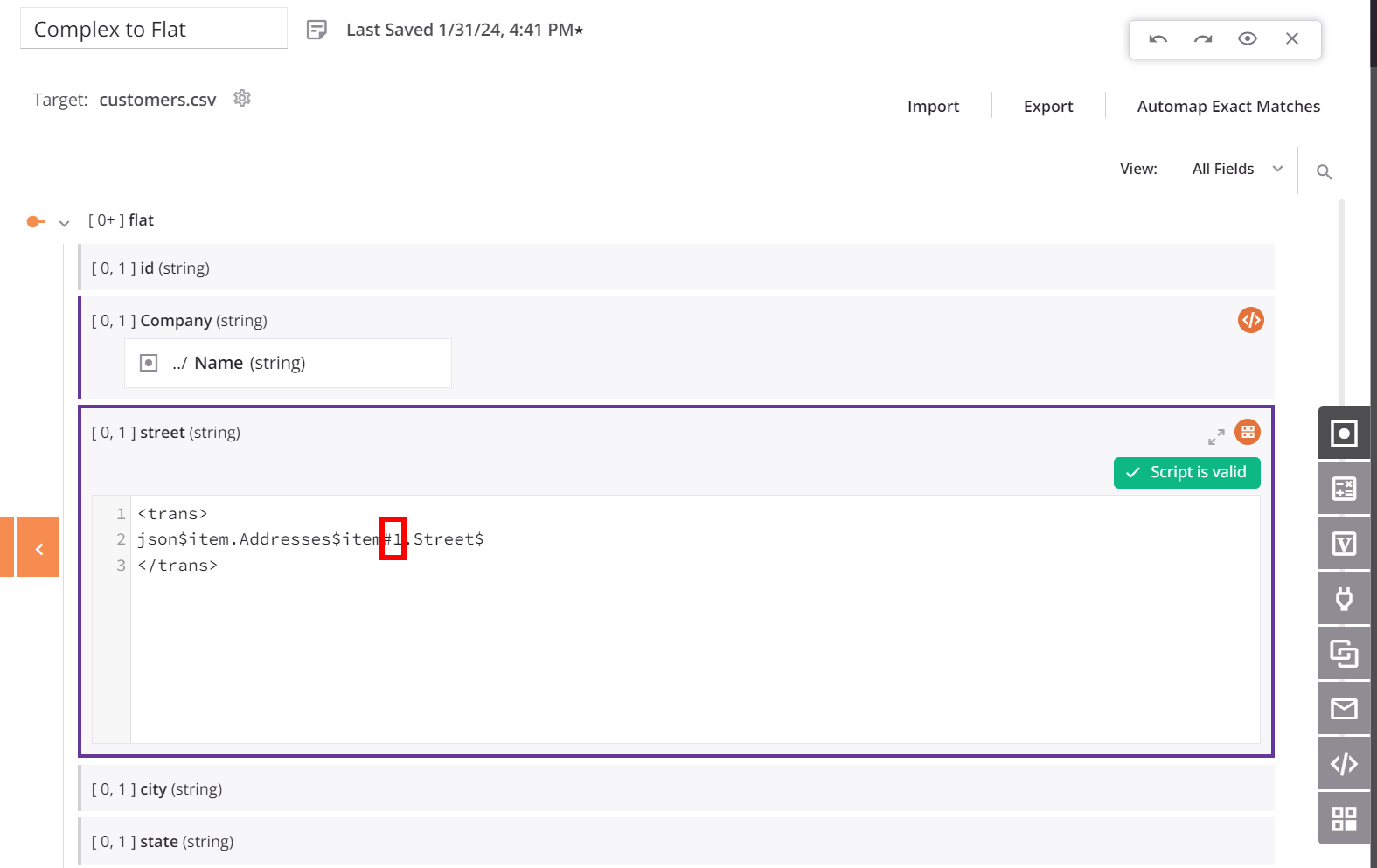
Hinweis
Dieses Beispiel verwendet die Hash-Syntax, die in der Referenzpfadnotation beschrieben ist.
Um die zweiten oder nachfolgenden Elemente des Arrays zurückzugeben, geben Sie #2, #3 usw. an. Die FindValue-Funktion kann ebenfalls verwendet werden, um in einem Array nach einem Wert zu suchen und das zugehörige Feld zurückzugeben. Zum Beispiel könnte das Mapping-Skript für das Ziel-Feld country auf einem Type von Billing basieren:
<trans>
FindValue("Billing", json$item.Addresses$item#.Type$, json$item.Addresses$item#.Country$)
</trans>
Beachten Sie, dass beim Verwenden von Instanzfunktionen das Hash-Symbol automatisch eingefügt wird, wo es erforderlich ist.
Nachdem das Elementreferenz (#1) in das Feld-Mapping-Skript eingefügt wurde, kehrt die Schleifen-Knoten-Iteratorzeile automatisch zum Quell-Top-Level-Kunden/Artikel-Array-Knoten zurück. Dies zeigt, dass für jeden neuen Kunden-Datensatz in der Quelle ein neuer Kunden-Datensatz im Ziel generiert wird:
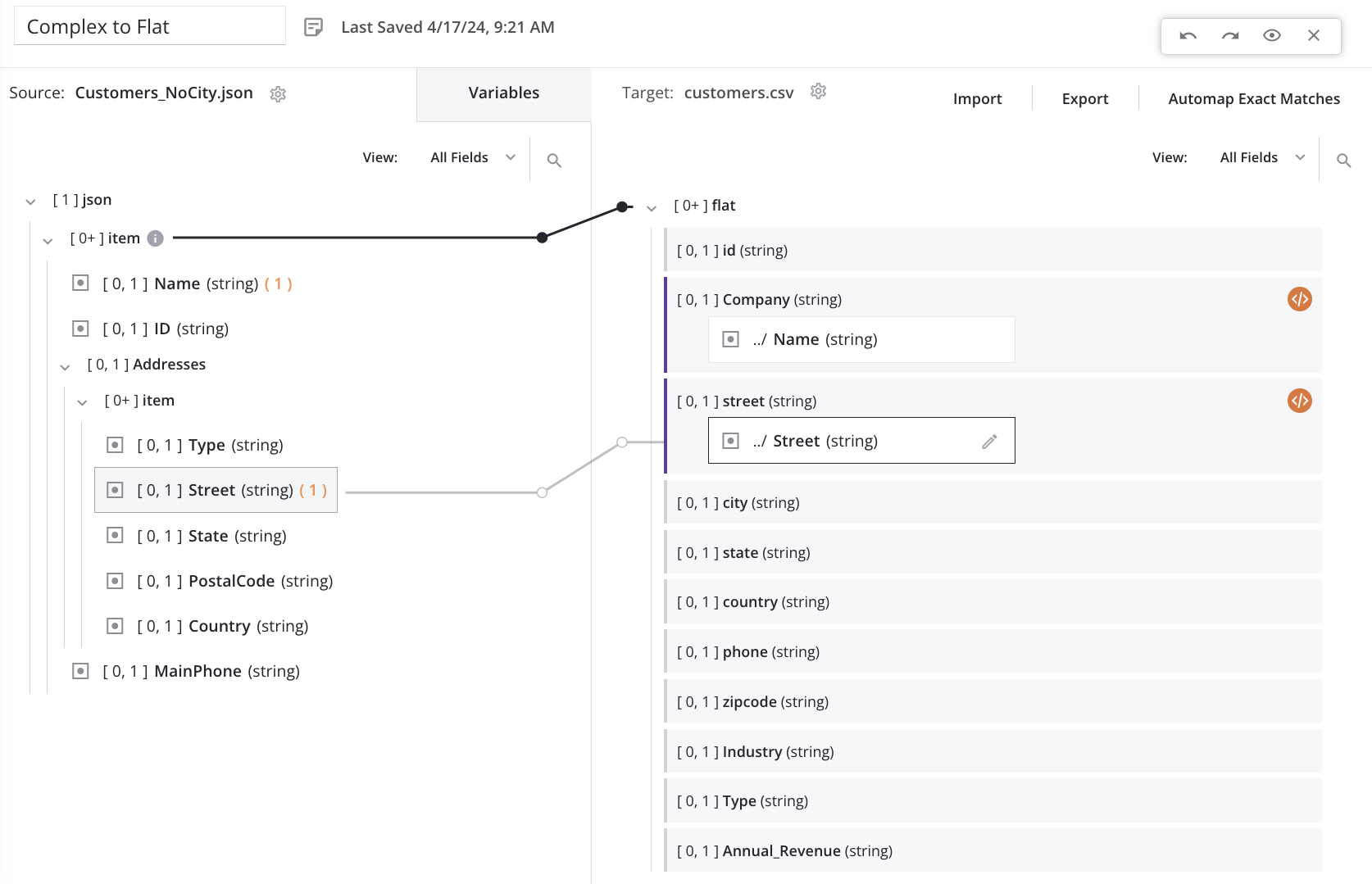
Wenn wir zusätzliche Felder im untergeordneten Array zuordnen, kehrt die Schleifen-Knoten-Iteratorzeile an die ursprüngliche Position zurück. Der Prozess des Hinzufügens der Elementreferenz (#1) muss wie oben für jede Feldzuordnung im Array wiederholt werden.
Entfernen eines Schleifen-Knotens und Zuordnungen
Optionen zum Entfernen eines manuell definierten Schleifen-Knotens oder zum Entfernen eines beliebigen Schleifen-Knotens und seiner Zuordnungen sind im Aktionsmenü eines Knotens verfügbar.
Fahren Sie mit der Maus über einen Knotennamen und klicken Sie auf das Aktionsmenü. Wählen Sie aus dem Menü eine dieser Optionen zum Entfernen von Zuordnungen:

| Menüelement | Beschreibung |
|---|---|
Schleifen-Knoten entfernen entfernt die Definition des Schleifen-Knotens. Diese Aktion ist nur für Knoten verfügbar, die einen manuell definierten Schleifen-Knoten haben. Um eine Schleifen-Knoten-Definition bei einem automatisch generierten Schleifen-Knoten zu entfernen, entfernen Sie alle direkten Blattzuordnungen, wie unter Zielknotenaktionen beschrieben. Hinweis Wenn Sie alle direkten Blattzuordnungen eines manuell definierten Schleifen-Knotens entfernen, bleibt die Definition des Schleifen-Knotens bestehen. |
|
Schleifen-Knoten und Zuordnungen entfernen entfernt die Definition des Schleifen-Knotens aufgrund von Zuordnungen, die direkte Blattkinder sind, die mit dem Schleifen-Knoten verbunden sind, und entfernt diese Zuordnungen. Alle anderen Zuordnungen innerhalb von untergeordneten Schleifen-Knoten unter dem übergeordneten Schleifen-Knoten bleiben erhalten, und der Knoten behält seine Schleifen-Knoten-Definition, wenn mindestens ein Enkelkind zugeordnet ist. Diese Aktion ist nur für Knoten verfügbar, die einen Schleifen-Knoten definiert haben (entweder manuell oder durch automatische Generierung). |