Erstellen Sie Einzel- oder Mehrfachdatensatzausgaben im Jitterbit Design Studio
Anwendungsfall
Ein häufiges Szenario ist, dass die Quelle mehrere Datensätze enthält und eine effiziente Orchestrierung ermöglicht wird, wenn die Zieldateien einzeln geschrieben werden, sodass der Dateiname einen Schlüsselwert enthält, der von einem Feldwert im Datensatz abgeleitet ist.
Das Standardverhalten von Jitterbit besteht darin, eine einzelne Datei mit mehreren Datensätzen zu erstellen, wenn die Quelle mehrere Datensätze enthält. Diese Seite zeigt auch (in Beispiel 2) wie man mit dem reservierten globalen Variablenpräfix SOURCE_CHUNK eine Ausgabe mehrerer Datensätze erreicht.
Beispiel 1: Mehrere Datensätze in einer einzigen Ausgabedatei
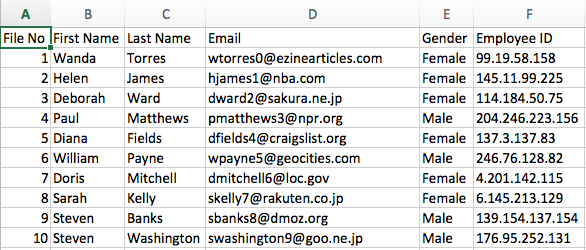
Für diese Beispiele wird davon ausgegangen, dass die Quelldatei eine Liste von Mitarbeitern enthält, wobei ein Feld eine Mitarbeiter-ID enthält.
Beispiel für Quelldaten:
Erstellen Sie eine grundlegende Operation, bei der wir alle Standardeinstellungen akzeptieren:
Definieren Sie die Quelle:
Einfaches Mapping, bei dem die Transformation die Quell- und Zieldatensätze anzeigt:
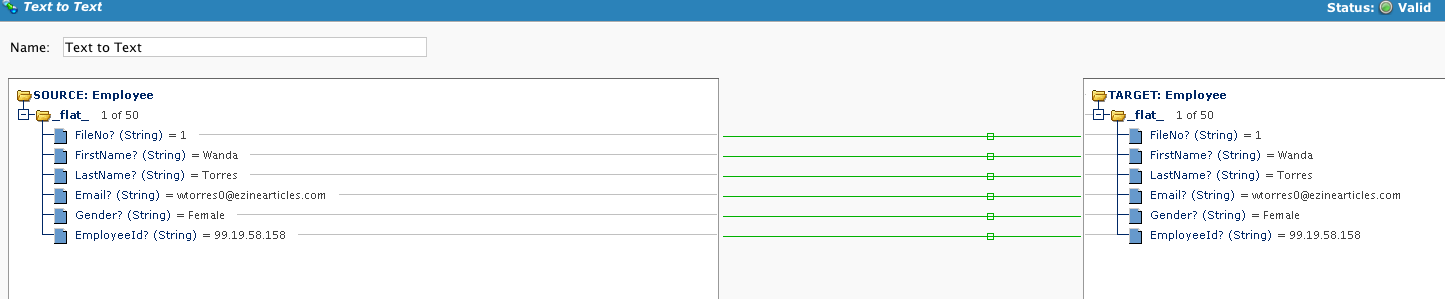
Definieren Sie das Ziel:
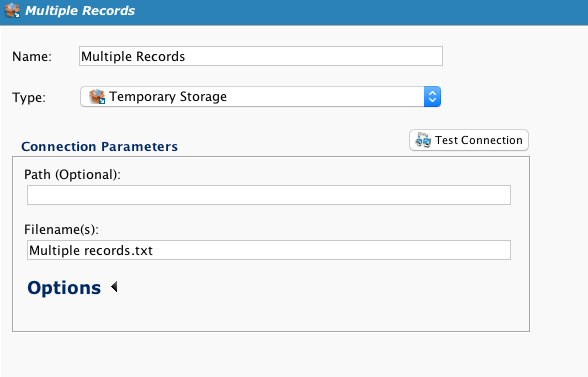
Die Zieldatei (Multiple records.txt) ist eine einzelne Datei, die mehrere Datensätze enthält:

Beispiel 2: Mehrere Ausgabedateien, die einen einzelnen Datensatz enthalten
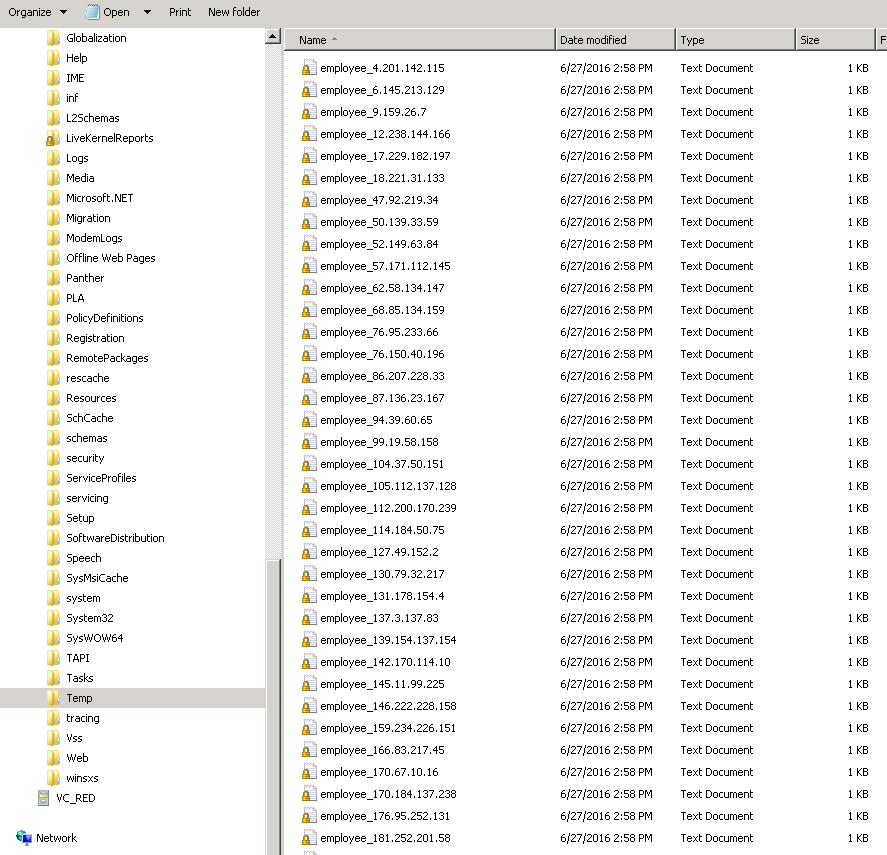
Der Endpoint erfordert ein Dateiformat, bei dem die Mitarbeiter-ID im Dateinamen erforderlich ist. Dies bedeutet, dass 50 Datensätze erstellt werden müssen, wobei jeder Datensatz einen Dateinamen nach dem Muster employee_\<employee id>.txt hat.
Vor der Einführung von SCOPE_CHUNK wäre für die Generierung mehrerer Dateien mit einem einzelnen Datensatz ein zusätzlicher Satz von Vorgängen zum Lesen und individuellen Ausgeben der Datensätze erforderlich gewesen.
Mit SCOPE_CHUNK kann ein einzelner Operation mehrere Datensätze generieren und Kontrolle über den datengesteuerten Dateinamen bieten. In diesem Beispiel wird eine Datei für eine andere Gruppe von 50 Mitarbeitern verarbeitet, die dieselben Datenfelder enthält wie die Quelldatendatei, die in Beispiel 1 verwendet wird. Der Operation in diesem Beispiel erstellt 50 Datensätze, die jeweils mit dem Dateinamen employee_\<employee id>.txt enden.
Achtung
Die SCOPE_CHUNK Die Präfixsyntax wird bei Vorgängen mit einer Transformation, die bedingtes Mapping verwendet, nicht unterstützt.
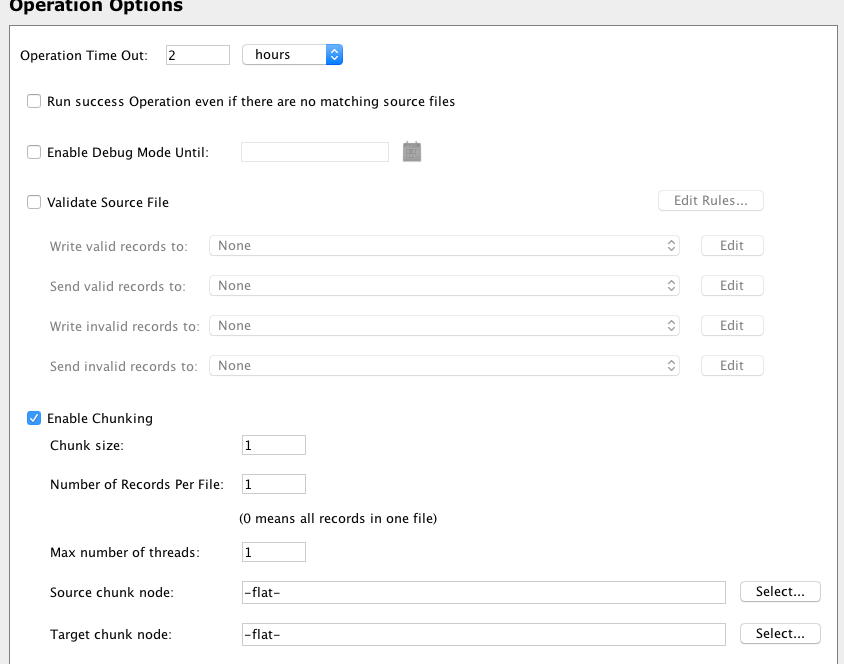
Setzen Sie Chunking aktivieren in den Operationsoptionen. Setzen Sie Chunk-Größe, Anzahl der Datensätze pro Datei und Maximale Anzahl von Threads auf 1. Dadurch wird die Transformation gezwungen, jeweils einen Datensatz zu verarbeiten:
Die Zuordnung ist ähnlich, zusätzlich wird auf das letzte Feld ein Script angewendet. Beachten Sie, dass beim Testen des Operation nur 1 Datensatz verarbeitet wird.
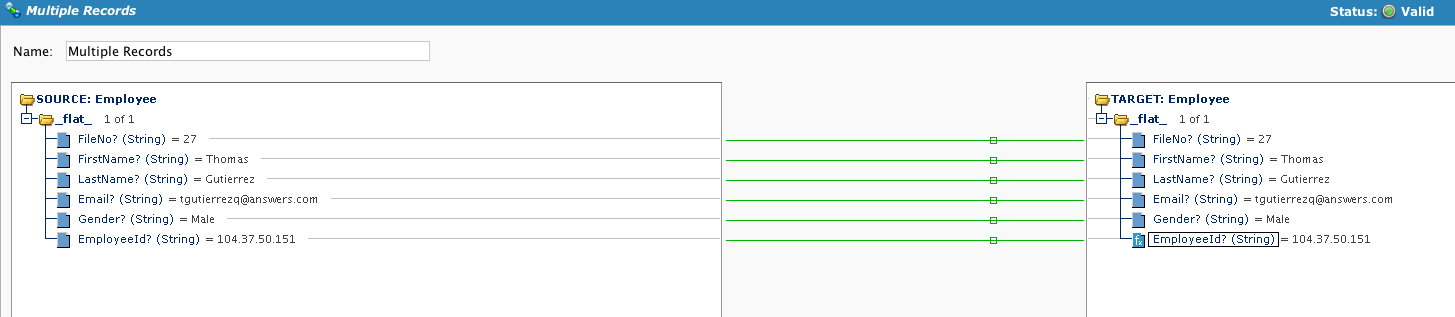
Erstellen Sie ein Script im letzten Feld. Indem wir eine globale Variable mit dem Präfix SCOPE_CHUNK erstellen und den gewünschten Dateinamen eingeben, um einen Datensatzwert einzuschließen, können wir die globale Variable an das Ziel übergeben.
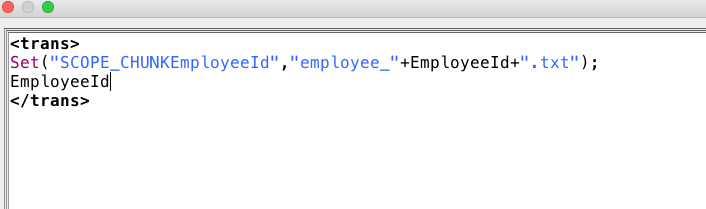
Geben Sie die globale Variable in das Feld Dateiname(n) des Ziels ein:
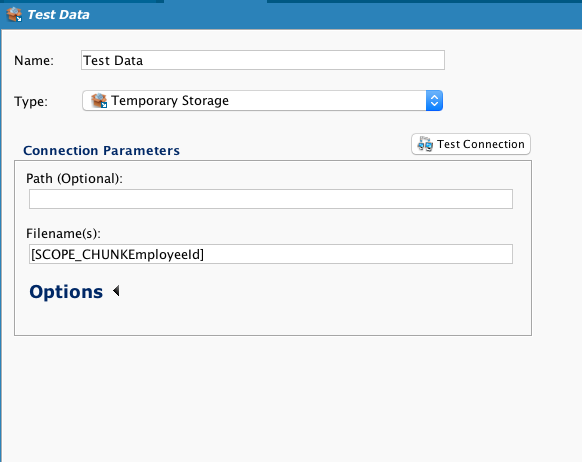
Wenn der Operation ausgeführt wird, wird nun für jeden Mitarbeiter eine individuelle Datei erstellt, die nur diesen einen Mitarbeiterdatensatz enthält und individuell benannt ist, sodass die Mitarbeiter-ID enthalten ist. Im angezeigten Screenshot sind die Dateinamensuffixe (.txt) sind ausgeblendet: